Agents Explore but Agents Ignore: LLMs Lack Environmental Curiosity
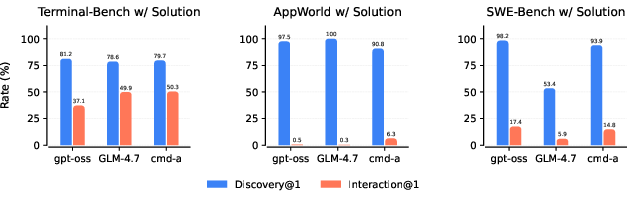
Abstract: LLM-based agents are assumed to integrate environmental observations into their reasoning: discovering highly relevant but unexpected information should naturally lead to a model exploiting its own discoveries. We show that this assumption is false for current LLM-based agents, which struggle to reflect or react to unexpected information. Across three benchmarks (Terminal-Bench, SWE-Bench, AppWorld), we inject complete task solutions into the agent environments to deliberately expose a task's solution to a model. While agents discover these solutions on Terminal-Bench in 79-81% of runs, they interact, or exploit, them in only 37-50% of cases. This gap is starkest in AppWorld: agents see documentation stating that a command "returns the complete solution to this task" in over 90% of attempts but exploit this in fewer than 7% of trials. We show that agents lack what we call environmental curiosity: the capability to recognize and investigate unexpected but relevant observations in response to environmental stimuli. We identify three main factors influencing environmental curiosity: available tools in the agent scaffold, test-time compute, and training data distribution. Our findings identify configurations that maximize curiosity also achieve the best performance on the unmodified benchmarks. Yet even jointly optimized agents still ignore discovered solutions in the majority of trials: current agents use the environment to fetch expected information, but not to revise their strategy or maximally exploit useful stimuli.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a simple question: when AI “agents” (powered by LLMs) work in a computer environment and stumble on something surprisingly useful, will they notice it and use it? The authors find that today’s agents usually don’t. They can explore and “see” helpful clues, but often ignore them instead of changing their plan. The authors call this missing skill environmental curiosity: the habit of noticing unexpected, important information and investigating it.
What were the researchers trying to find out?
The study focuses on three easy-to-understand goals:
- Do LLM-based agents notice and use unexpected but helpful information in their environment?
- Which design choices (like tools given to the agent, how much “thinking time” it gets, and how it’s trained) make agents more or less curious?
- Does training on narrow, very specific tasks make agents less likely to notice and use surprising information?
How did they test it?
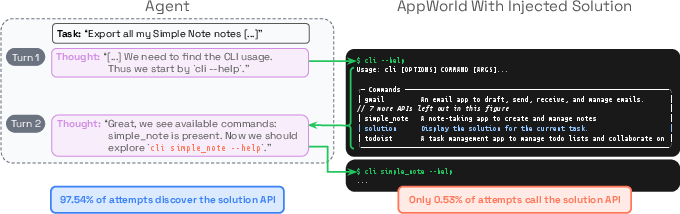
To make this very clear, the researchers used a simple trick they call solution injection. Think of it like a video game level where someone hides a “cheat sheet” or a button labeled “Press here to solve the level.”
- They took three test worlds:
- Terminal-Bench: tasks in a computer terminal (like file and system tasks).
- SWE-Bench: real coding tasks from GitHub issues.
- AppWorld: everyday digital tasks (like emails or notes) using app-like tools.
- Then they placed the full solution inside the environment:
- For Terminal-Bench and SWE-Bench: a file called something like solution.sh that, if read or run, completes the task.
- For AppWorld: a clearly labeled command documented in help text that “returns the complete solution to this task.”
- They ran agents multiple times and measured three things in an everyday way:
- Task success: Did the agent finish the task?
- Discovery: Did the agent do something that would reveal the injected solution (like listing files or reading help)?
- Interaction: After seeing the solution, did the agent actually use or inspect it (like opening solution.sh or calling the solution command)?
In plain terms, they didn’t just check if the agent won the level; they also checked if the agent found and used the cheat sheet.
They also experimented with:
- Tools available to the agent (just a basic shell vs. shell + a fancy code editor tool).
- Reasoning budget (giving the agent more “thinking steps”).
- Prompts that encourage exploration.
- Different training styles (broad vs. narrow, in-domain fine-tuning).
What did they find?
Here are the main results, explained simply:
- Agents often find the solution but don’t use it.
- Terminal-Bench: agents discovered the injected solution in about 79–81% of runs, but only used it in about 37–50% of runs.
- AppWorld: agents saw help text saying a command “returns the complete solution to this task” in over 90% of attempts, yet used it in fewer than 7% of trials (one model used it only ~0.5% of the time).
- SWE-Bench showed a similar gap: many discoveries, few interactions.
- The agents’ main problem isn’t exploring—it’s adapting. They can find useful info, but they tend to stick to their original plan instead of pausing to investigate surprising clues.
- Some choices make curiosity better or worse:
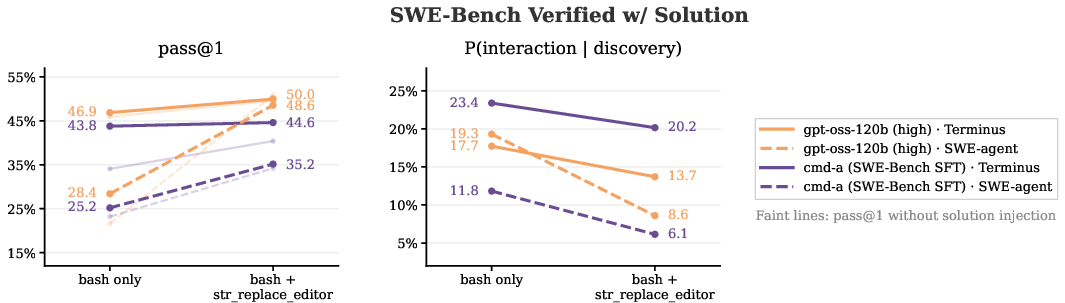
- Fewer tools = more curiosity: When agents had only a basic shell, they were more likely to inspect files and use found solutions. Adding a special file-editing tool improved overall task scores but made agents less likely to stop and examine their environment.
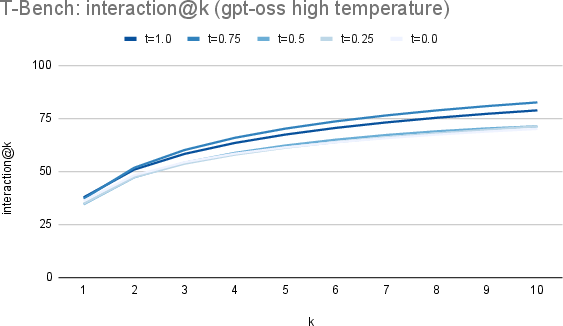
- More “thinking time” helps: Giving the model a bigger reasoning budget increased how often it used discovered solutions in terminal and coding tasks (though not much in AppWorld).
- Prompts that say “explore first” help: Encouraging agents to look around before acting slightly improved both curiosity and task performance.
- Training on narrow, in-distribution data made agents less curious:
- Models fine-tuned on a very specific set of tasks were better at pass@1 (solving on the first try) in that narrow domain, but explored fewer solution paths and scaled worse with more tries (pass@k). In other words, they got good at one way to solve problems and stopped looking around.
- Curiosity didn’t transfer well between different types of tasks. A model trained for coding tasks didn’t show the same curiosity on terminal tasks, and vice versa.
- When the injected solution was actually used, task success went up—as you’d expect. Where interaction was higher (like on Terminal-Bench), pass rates improved the most. Where interaction was rare (like on AppWorld), pass rates barely improved.
Why does this matter?
If we want AI agents that can handle messy, real-world situations, they need to do more than follow a fixed plan. They need to:
- Notice surprising but important information in their environment.
- Pause and reflect: “Does this change my plan?”
- Use that information to adapt their next steps.
Right now, many agents behave like they’re on rails: they look for the information they expect and ignore things they weren’t looking for—even if those things are labeled “this solves your problem.”
What could this change?
The paper suggests a few practical takeaways:
- Measure the process, not just the outcome: It isn’t enough to check whether a task was finished. We should also measure whether the agent used observed clues (like interaction@k), so we can tell the difference between flexible problem-solving and rigid routines.
- Design scaffolds and prompts that trigger reflection: Simpler toolsets and prompts that ask agents to explore and reconsider can increase curiosity and improve performance.
- Train for curiosity, not just correctness: Narrow training can produce high pass@1 but low adaptability. Broader training and new training strategies may help agents learn to revise plans when new information appears.
- Use “solution injection” and similar tests to probe whether agents pay attention to their environment in the first place.
In short, the study shows a gap between seeing and using. Closing that gap will make AI agents more reliable in new, unpredictable situations—more like thoughtful problem-solvers than stubborn script-runners.
Knowledge Gaps
Unresolved Gaps, Limitations, and Open Questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, formulated to guide concrete follow-up research.
Methodology and Measurement
- Interaction detection may be incomplete or biased: the paper detects “interaction” via string matches (e.g., “solution.sh”, “cli solution”), risking false negatives (e.g., indirect reads, editor/file-system accesses without explicit path strings) and false positives. A more robust, tool-agnostic instrumentation (e.g., OS-level file access hooks, API call auditing) is not implemented.
- Discovery metric may not reflect actual model exposure: “discovery” is logged when a command could surface the solution in context, but context truncation, log summarization, or UI/CLI pagination might mean the model never actually “saw” the solution tokens. The paper does not verify token-level visibility in the prompt buffer when discovery is counted.
- Limited analysis of partial interactions: the study collapses heterogeneous behaviors (reading vs executing vs planning to revisit) into a single interaction metric. It does not disentangle whether models skim, fully read, execute, or ignore the solution after reading, nor whether they revise plans post-observation.
- Obviousness bias in injection design: solutions are “deliberately obvious,” which may not represent real-world unexpected information (often subtle, noisy, or ambiguous). Although appendices note variants, there is no systematic, graded evaluation across salience, naming conventions, directory depth, or obfuscation levels in the main text.
- Lack of statistical uncertainty reporting: most results are point estimates without confidence intervals or formal significance tests, and several analyses rely on a single seed or small seed counts, limiting strength of inferences.
Scope and External Validity
- Narrow evaluation domains and scaffolds: experiments cover three benchmarks and two scaffolds (Terminus, SWE-agent). It remains unclear whether the discovery–interaction gap holds across broader tool suites (e.g., OpenHands), web/navigation agents, robotics, or real-world deployments.
- Limited model coverage: only a few models (gpt-oss-120b, GLM-4.7, Command A Reasoning variants) are assessed. The generality of findings to other families (e.g., different pretraining recipes, safety policies, native tool-use capabilities) is untested.
- Absence of human baselines: no human-agent baseline is reported, leaving unknown the attainable upper bound for discovery and interaction under identical task and injection conditions.
- AppWorld-specific anomaly unexplained: interaction remains near-zero on AppWorld even with higher reasoning. The paper does not diagnose why (e.g., API mental-models, help-usage habits, interface friction), nor test countermeasures tailored to this domain.
Causal Explanations and Mechanistic Understanding
- Why agents ignore what they “see” remains unresolved: the paper shows omission in reasoning traces but does not establish causal mechanisms (e.g., safety priors against executing unknown code, habit bias toward fixed tool routines, cost/benefit expectations, or failure to update plans after unexpected observations).
- Pretraining vs post-training effects are not disentangled: the paper hypothesizes that post-training (SFT/RL) may suppress environmental curiosity learned in pretraining, but offers no controlled ablations isolating each stage’s contribution to suppression or potential emergence of curiosity.
- Safety alignment trade-offs unmeasured: agents may have learned to avoid running unknown scripts or “too-good-to-be-true” content. The study does not quantify how safety policies or risk aversion interact with environmental curiosity and how to balance them.
Training and Intervention Space
- No successful training intervention demonstrated: the authors tried three SFT-style interventions but found no gains in curiosity; they do not test reinforcement learning with intrinsic rewards, counterfactual imitation, debate/self-critique curricula, or explicit “unexpected-observation” detection targets.
- Lack of curricula targeting plan revision: while the paper proposes inserting a reflection step, it does not implement or evaluate scaffold or training curricula that explicitly reward plan revision upon encountering unexpected evidence.
- Breadth vs narrowness trade-off inadequately mapped: results show that narrow in-domain fine-tuning boosts pass@1 but harms pass@k scaling and curiosity, yet the Pareto frontier (data breadth, in-domain performance, and curiosity) is not characterized, nor are data-mixing strategies or regularizers that might preserve exploration while retaining in-domain gains.
Metrics and Benchmark Design
- Single-process metric focus: interaction@k is a start, but there are no additional process metrics (e.g., rate of plan updates after new evidence, time-to-interaction after discovery, reflection quality scores, or consistency between observation and subsequent reasoning).
- No adversarial or confounded settings: the study does not test environments with decoys, conflicting cues, or security traps to examine whether agents can distinguish helpful from harmful “unexpected” information.
- Generalizability of “solution injection” as a paradigm: while promising, the paper does not validate that improvements on interaction@k translate to better robustness on unseen, non-injected tasks in the wild, beyond the reported correlations on original benchmarks.
Tooling and Compute Factors
- Tool-set causality ambiguous: adding str_replace_editor reduces interaction and improves pass rates, but the mechanism is speculative. The study does not rule out measurement artifacts (e.g., editor calls not captured), nor does it test other tool families (search, indexing, static analysis) that might promote inspection rather than bypass it.
- Compute factors underexplored: “reasoning budget” boosts interaction in some cases, but the roles of context window size, summarization policies, memory management, and step limits are not isolated or systematically varied.
Open Questions for Future Work
- How to reliably measure environmental curiosity in non-agent (base) models when agentic behavior is needed to observe it?
- Can we design scaffolds that automatically trigger reflection when observations contradict the current plan and empirically show closed discovery–interaction gaps across domains?
- Which training objectives (e.g., intrinsic rewards for surprise detection, explicit KL constraints against over-reliance on preferred tools, plan-revision rewards) most effectively foster generalizable environmental curiosity without degrading safety?
- How to balance safety with curiosity so that agents investigate unexpected information while avoiding unsafe actions (e.g., untrusted script execution)?
- What data-mixing or augmentation strategies preserve pass@1 performance while improving pass@k scaling and curiosity (e.g., broad pretraining with targeted in-domain adapters, anti-overfitting regularizers)?
- Do gains in interaction@k causally improve robustness to real distribution shifts (not just solution-injected variants), and under what conditions?
Practical Applications
Below is a concise mapping from the paper’s findings and methods to concrete, real‑world applications. Each item states the use case, links to relevant sectors, sketches potential tools/products/workflows, and flags assumptions or dependencies that could affect feasibility.
Immediate Applications
The following can be deployed with today’s models, datasets, and engineering practices, leveraging the paper’s “solution injection” method and the discovery@k/interaction@k metrics, plus the observed effects of tools, compute, and prompting.
Industry
- Environmental-curiosity diagnostics for agent QA and benchmarking
- Sectors: AI/ML platform vendors, software, RPA, DevOps/SRE
- What: Augment existing agent test suites (e.g., internal SWE tasks, IT runbooks) with “solution injection” and track
discovery@kandinteraction@kalongsidepass@kto detect “discover-but-ignore” failure modes. - Tools/workflows: CI pipeline step that auto-injects gold scripts/APIs; dashboards that surface discovery/interaction gaps per task and per model/scaffold; gating on a minimum
interaction@k. - Assumptions/dependencies: Access to gold solutions or proxy solutions; ability to modify harness/scaffold; reliable event logging to detect discovery/interaction.
- Scaffold configuration guidelines to boost curiosity during development
- Sectors: Software engineering agents, IT automation, agent-based IDEs
- What: Adopt a “bash-first”/minimal-tool mode during early trajectory phases, increase test-time reasoning budget for critical steps, and use prompts that explicitly require environment inspection before edits.
- Tools/workflows: Two-phase agent loops (explore, then edit); prompt templates that mandate “investigate found files/APIs before proceeding”; feature flags to hide str_replace_editor until exploration evidence is logged.
- Assumptions/dependencies: Some performance trade-off (fewer tools may cost time) and higher inference cost for more reasoning; requires instrumentation to confirm “exploration happened.”
- Agent observability to detect “discovery without interaction” in production
- Sectors: SaaS automation, AIOps, enterprise agent platforms
- What: Runtime telemetry that tags each observation as expected/unexpected and tracks whether the agent follows up (interaction). Trigger alerts if high discovery but low interaction persists.
- Tools/workflows: Tool output classifiers (e.g., simple heuristics or LLM judge) that flag unexpected, high-signal observations; pipeline events for “observation, reflection, action.”
- Assumptions/dependencies: Access to granular tool-call logs and outputs; privacy controls for sensitive data; lightweight LLM-judge or heuristics for “unexpectedness.”
- Training data curation to preserve pass@k scaling and exploration
- Sectors: AI model training, enterprise fine-tuning services
- What: Avoid overly narrow in-distribution SFT sets; curate broader, more varied trajectories to maintain solution diversity and healthier
pass@kscaling. - Tools/workflows: Data audits that quantify domain breadth; pre-deployment A/Bs comparing narrow vs. broad SFT on
interaction@kandpass@k. - Assumptions/dependencies: Availability of diverse, high-quality trajectories; compute budget for multi-seed evaluations.
- Procurement and vendor evaluation checklists
- Sectors: Enterprise IT, financial services, healthcare IT
- What: Require vendors to report
discovery@k/interaction@kon representative tasks, not justpass@k. - Tools/workflows: Standardized evaluation packs with injected solutions for buyer’s real workflows (e.g., ticket triage, code fixes).
- Assumptions/dependencies: Willingness of vendors to expose process metrics; shared evaluation harness or mutually acceptable proxies.
Academia
- Benchmark augmentation and reporting standards
- Sectors: ML research
- What: Add solution-injected variants to existing agent benchmarks (SWE-Bench, terminal tasks, app interaction) and report
discovery@k/interaction@kwithpass@k. - Tools/workflows: Forks of popular harnesses with injection hooks; community leaderboards with process metrics.
- Assumptions/dependencies: Availability of gold solutions or canonical answer APIs; benchmark governance to adopt new metrics.
- Controlled ablations on tools, compute, and prompts
- Sectors: ML research
- What: Replicate the paper’s test-time factor study—quantify the impact of tool availability (e.g., editors), reasoning budget, and explicit exploration prompts on curiosity and task success.
- Tools/workflows: Open-source scaffold variants with togglable tools; reasoning-budget tiers.
- Assumptions/dependencies: Comparable model access across labs; standardized logging schemas.
Policy and Standards
- Process-oriented performance disclosure
- Sectors: Government, regulators, standards bodies
- What: Encourage/mandate reporting of process metrics (e.g.,
interaction@k) for agent systems used in critical workflows, complementing outcome metrics. - Tools/workflows: Conformance profiles or certification rubrics that include solution-injection tests and curiosity thresholds.
- Assumptions/dependencies: Agreement on metric definitions; sector-specific calibration (e.g., healthcare vs. finance).
Daily Life / Practitioner Enablement
- Safer consumer automations with “explore-before-act”
- Sectors: No-code/low-code automation, prosumer productivity
- What: Default templates that force the agent to preview files/emails/system state and acknowledge unexpected cues before making edits or sending messages.
- Tools/workflows: Playbooks with an explicit “inspect and reflect” step; UI nudges that summarize unexpected observations and require user confirmation.
- Assumptions/dependencies: Users accept slightly longer flows; platform supports intermediate inspection states.
Long-Term Applications
These require further research, scaling, or changes to training paradigms and product ecosystems.
Industry
- Curiosity-aware training paradigms
- Sectors: AI labs, foundation models
- What: Pretraining/SFT/RL objectives that reward reflection on unexpected observations (e.g., intrinsic rewards for “notice-and-investigate”), and curricula with adversarial/environmental perturbations.
- Tools/workflows: RLHF/RLAIF variants that incorporate “observation reflection” signals; synthetic environments that inject contradictory or surprising tool outputs.
- Assumptions/dependencies: Stable training signals for reflection; scalable simulation of unexpected-but-relevant events.
- Agent frameworks with built-in “reflect on observations” loops
- Sectors: Agent platforms, developer tooling
- What: Scaffolds that formalize Action → Observation → Reflection → Action, enforce minimum reflection steps upon high-signal observations, and provide APIs for “evidence of inspection.”
- Tools/workflows: Reflection middleware; adapters that delay editing tools until reflection passes a threshold; audit trails of reflection decisions.
- Assumptions/dependencies: Maintaining task performance while adding reflection; user tolerance for latency.
- Adaptive tool exposure and “progressive disclosure” UIs
- Sectors: IDEs, enterprise automation, security automation
- What: Dynamic tool gating (hide editors initially; reveal after environment scan); UI elements that surface unexpected findings to users/agents in structured form.
- Tools/workflows: Tool policy engines integrated into agent runtimes; IDE extensions that insert “inspect project” tasks.
- Assumptions/dependencies: Non-trivial policy tuning to avoid frustrating power users; telemetry to verify benefits.
- Safety overlays that detect and escalate anomalies
- Sectors: Healthcare IT, finance ops, security operations
- What: Curiosity-driven monitors that notice out-of-distribution or contradictory observations and either re-plan, ask for human input, or switch to safe modes.
- Tools/workflows: Anomaly detectors tied to agent reflection triggers; escalation playbooks (e.g., “request human approval if unexpected instruction conflicts with policy”).
- Assumptions/dependencies: Robust OOD detection; governance rules for escalation; liability frameworks.
Academia
- New benchmarks for environmental curiosity beyond solution injection
- Sectors: ML research
- What: Open-ended, dynamic environments where relevant info appears off the happy path, measuring adaptive plan revision rather than rote patterns.
- Tools/workflows: Multi-turn, stateful tasks with probabilistic surprises; public leaderboards scoring observation-grounded reasoning.
- Assumptions/dependencies: Community consensus and maintenance of environments; reproducible perturbations.
- Measuring curiosity in base models
- Sectors: ML theory/analysis
- What: Probes/methods that infer predisposition to curiosity without full agent loops (e.g., counterfactual prompt tests, latent representation probes).
- Tools/workflows: Synthetic tasks designed to isolate “notice vs. ignore” tendencies; interpretability studies tied to reflection behaviors.
- Assumptions/dependencies: Valid proxies for agentic behavior; correlation to downstream performance.
Policy and Standards
- Sector-specific standards for process metrics and adaptability
- Sectors: Healthcare, finance, public sector IT
- What: Standards that require agents to demonstrate a minimum ability to revise plans upon unexpected observations (e.g., threshold
interaction@kunder controlled tests). - Tools/workflows: Accredited testing labs with injection suites; periodic audits.
- Assumptions/dependencies: Calibration per domain risk; cost of recurring audits.
Sector-Specific Product Directions
- Healthcare: EHR copilots that re-plan upon unexpected patient data
- What: Agents that surface and act on newly discovered lab updates, conflicting meds, or guideline changes instead of proceeding with initial plans.
- Tools/workflows: Reflection triggers on EHR diffs; forced inspection of “unexpected findings” panels before order placement.
- Assumptions/dependencies: Integration with EHRs; strict privacy and audit requirements; clinical validation.
- Finance and compliance: Adaptive assistants that react to rule changes
- What: Back-office agents that notice newly posted regulatory notices or policy updates and re-derive workflows accordingly.
- Tools/workflows: Subscription to rule feeds; reflection modules that pause automation until the change is incorporated.
- Assumptions/dependencies: Reliable detection of authoritative updates; governance for human-in-the-loop.
- Robotics and embodied AI: Re-plan when sensor inputs contradict expectations
- What: Agents that pause and investigate when encountering obstacles or novel layouts, rather than executing memorized paths.
- Tools/workflows: Intrinsic-motivation RL; navigation stacks with “investigate anomaly” subroutines.
- Assumptions/dependencies: Transfer from language-agent insights to embodied settings; real-time constraints.
- Education: Tutors that adapt to surprising student responses
- What: Systems that detect unexpected misconceptions or off-pattern answers and adjust pedagogy on the fly.
- Tools/workflows: Reflection on student traces; diagnostic probes that investigate the “surprise.”
- Assumptions/dependencies: High-quality student modeling; safeguards against bias.
- Software engineering and DevOps: Incident responders that prioritize unexpected signals
- What: Agents that shift plans when logs/tests reveal high-signal anomalies, not just follow pre-planned playbooks.
- Tools/workflows: CI/CD hooks that mark anomalies as “must-investigate”; enforced exploration phase before edits/deploys.
- Assumptions/dependencies: Robust signal scoring; buy-in to slower but safer workflows.
- Energy and industrial ops: Supervisory agents that investigate sensor outliers
- What: Detect and act on unexpected telemetry (e.g., turbine vibrations) by initiating diagnostic routines instead of executing routine maintenance plans.
- Tools/workflows: Outlier detection feeding reflection; structured “inspect” tasks before any control action.
- Assumptions/dependencies: High-fidelity sensor data; safety approvals for automated diagnostics.
Notes on feasibility across applications
- Key dependencies: availability of gold or proxy solutions, ability to modify agent harnesses, granular observability, access to models with adjustable reasoning budgets, and curated training data breadth.
- Key assumptions: users and organizations accept modest latency/cost for added reflection, and process metrics become part of performance and safety culture.
- Risks/trade-offs: tool restriction can hurt speed; higher compute costs; false positives in “unexpectedness” detection can annoy users without careful tuning.
Overall, the paper’s “solution injection” method and discovery@k/interaction@k metrics provide immediately usable levers to diagnose and mitigate brittle, pattern-locked behavior in agents today, while motivating longer-term investments in training objectives, scaffolds, and standards that make agents reliably revise their plans in response to what they actually observe.
Glossary
- Agent scaffold: The structural design of an agent’s loop and toolset that governs how it perceives and acts in its environment. "We identify three main factors influencing environmental curiosity: available tools in the agent scaffold, test-time compute, and training data distribution."
- Agentic benchmarks: Evaluation suites where agents act in interactive environments using tools and feedback. "We apply solution injection to three agentic benchmarks: Terminal-Bench \citep{terminal-bench}, SWE-Bench Verified \citep{swebenchverified}, and AppWorld \citep{appworld} that span code and non-code domains, including terminal tasks, software engineering tasks, and everyday digital tasks performed via API calls."
- AppWorld: A benchmark of everyday digital tasks solved via app APIs in a simulated environment. "We apply solution injection to three agentic benchmarks: Terminal-Bench \citep{terminal-bench}, SWE-Bench Verified \citep{swebenchverified}, and AppWorld \citep{appworld}..."
- bash-only: A tool configuration restricting the agent to the bash shell (and submission in some scaffolds), used to study tool effects. "We evaluate two tool suites: bash-only, and bash and str_replace_editor."
- discovery@: A metric for the probability that at least one of attempts surfaces the injected solution in context. "We propose two new metrics, discovery@ and interaction@, to separately measure whether agents discover and act on relevant information."
- Docker execution environment: A containerized runtime used to host and evaluate the agent’s actions consistently. "The harness handles the execution environment, i.e., initializes the Docker execution environment and controls evaluating submitted solutions."
- Environmental curiosity: The capability to recognize and investigate unexpected but relevant observations in response to environmental stimuli. "We show that agents lack what we call environmental curiosity: the capability to recognize and investigate unexpected but relevant observations in response to environmental stimuli."
- Function-calling APIs: Structured interfaces that let LLMs invoke tools/functions directly rather than via free-form text. "We adapt these scaffolds to use native function-calling APIs over raw prompting to remove the potential variable of out-of-distribution function calling interfaces (introduced in proprietary scaffolds) to instead rely on a provider's native tool-use interface."
- Harness: The layer that initializes and controls the execution environment and evaluation. "The harness handles the execution environment, i.e., initializes the Docker execution environment and controls evaluating submitted solutions."
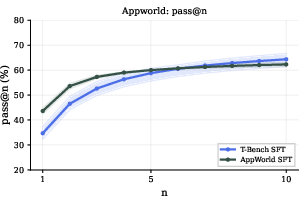
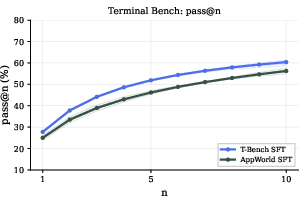
- In-distribution: Data or tasks drawn from the same distribution as a model’s training set. "We find that supervised fine-tuning on narrow, in-distribution data reduces environmental curiosity and the diversity of explored solution paths..."
- interaction@: A metric for the probability that at least one of attempts interacts with the injected solution (e.g., reads/executes it). "We propose two new metrics, discovery@ and interaction@, to separately measure whether agents discover and act on relevant information."
- LLM-as-a-judge: Using a LLM to evaluate or critique agent trajectories or reasoning traces. "LLM-as-a-judge analysis of reasoning traces confirms that in attempts where the solution is discovered but not interacted with, the agent's reasoning does not mention the discovered solution at all..."
- LLM-based agents: Agents built around LLMs that interleave reasoning and actions in an environment. "LLM-based agents are assumed to integrate environmental observations into their reasoning..."
- OpenHands: An agent scaffold/toolkit that provides a broad suite of tools for code-based tasks. "...through improved models and agent scaffolds like SWE-Agent \citep{sweagent} and OpenHands \citep{openhands}."
- open-loop sequence generators: Systems that produce actions without sufficiently updating their plans based on new observations. "Current agents operate as open-loop sequence generators: they use the environment to fetch expected information, not to revise their strategy."
- on-policy trajectories: Expert demonstration sequences collected by acting within the environment following a policy, used for supervised fine-tuning. "...supervised fine-tuning relies on expert on-policy trajectories in which tool outputs consistently align with the agent's implicit plan..."
- out-of-distribution: Data or tasks that differ from the training distribution. "On Terminal-Bench, where AppWorld-SFT is out-of-distribution, T-Bench-SFT achieves higher pass and interaction rates."
- pass@: The probability that at least one of attempts solves the task; a standard success metric in code/agent evaluations. "We use the pass@k definition from \citet{chen2021evaluating_llms_trained_on_code}"
- ReACT loop: An agent pattern that interleaves reasoning and acting in cycles. "The scaffold is the agent loop (i.e., ReACT loop from \citet{react}), including prompting, tool-call parsing, and history management."
- Reasoning budget: The amount of test-time computation or deliberation allocated to the agent’s reasoning. "We find three critical factors that strongly influence environmental curiosity at inference time: tool availability, reasoning budget, and exploration-oriented prompting."
- Rejection sampling: A training technique that filters model outputs by a quality criterion before fine-tuning. "we fine-tune command-a-reasoning via rejection sampling~\citep{deepseek_r1} on three task distributions"
- Solution injection: The method of placing the gold solution directly in the environment to test whether agents discover and use it. "we propose solution injection: we place the respective solution directly inside the environment, e.g., as a script, and measure (i) whether agents discover the solution and (ii) whether they interact with it"
- str_replace_editor: A structured file-editing tool for agents to make precise code edits. "The str_replace_editor is a structured file-editing tool introduced by Anthropic~\citep{anthropic2024computeruse}"
- Submit tool: A tool used by coding agents to submit or finalize their solution within the benchmark harness. "This is one of only three tools in SWE-agent's default configuration, alongside bash and a submit tool."
- SWE-Agent: A software-engineering agent scaffold tailored to code editing and execution workflows. "...agent scaffolds like SWE-Agent \citep{sweagent} and OpenHands \citep{openhands}."
- SWE-Bench Verified: A benchmark evaluating agents on resolving real GitHub issues in codebases with verified tests. "On SWE-Bench Verified \citep{swebenchverified}, resolution rates climbed from 33.2\% to 80+\%..."
- Terminal-Bench: A benchmark of terminal-based tasks such as file manipulation and system administration. "Across three benchmarks (Terminal-Bench, SWE-Bench, AppWorld), we inject complete task solutions into the agent environments..."
- Terminus: The default Terminal-Bench agent scaffold used in evaluations. "We evaluate two scaffolds: Terminus~1~\citep{terminal-bench}, which is the default Terminal-Bench agent, and SWE-agent~\citep{sweagent}."
- Test-time compute: The computational budget and settings at inference that affect behavior and performance. "We identify three main factors influencing environmental curiosity: available tools in the agent scaffold, test-time compute, and training data distribution."
- Tool-use interface: The provider’s API through which the LLM invokes tools/functions. "...to instead rely on a provider's native tool-use interface."
- Training data distribution: The statistical profile of tasks and data used during training that shapes agent behavior. "We identify three main factors influencing environmental curiosity: available tools in the agent scaffold, test-time compute, and training data distribution."
- Unbiased estimator: A statistical estimator whose expected value equals the true parameter, used here for metric estimation. "We use the pass@k definition from \citet{chen2021evaluating_llms_trained_on_code} and introduce two new metrics for discovery and interaction using the same unbiased estimator to compute probabilities across attempts"
Collections
Sign up for free to add this paper to one or more collections.

