- The paper introduces a Dual-Anchoring framework that regularizes agent states through instruction progress and memory landmark anchoring to counteract state drift.
- It leverages fine-grained progress supervision and dense landmark reconstruction to boost success rates, achieving up to 65.6% on the R2R-CE benchmark.
- The approach demonstrates robust real-world generalization, validated by zero-shot deployment on a quadruped robot and enhanced trajectory fidelity.
Dual-Anchoring: Structured State Regularization for Continuous Vision-Language Navigation
Introduction and Motivation
Vision-Language Navigation (VLN) in continuous 3D environments presents fundamental challenges for embodied AI, particularly when executing multi-step natural language instructions over extended trajectories. Despite advances in VLN via Video LLMs (Video-LLMs), a persistent failure mode—State Drift—limits robustness in long-horizon navigation. State Drift emerges as the gradual decoupling of the agent's internal cognitive representation from the true environment and task execution status. The paper decomposes this into two cognitive deficits: Progress Drift (mis-tracking instruction progress) and Memory Drift (loss of distinct representations for previously visited landmarks).
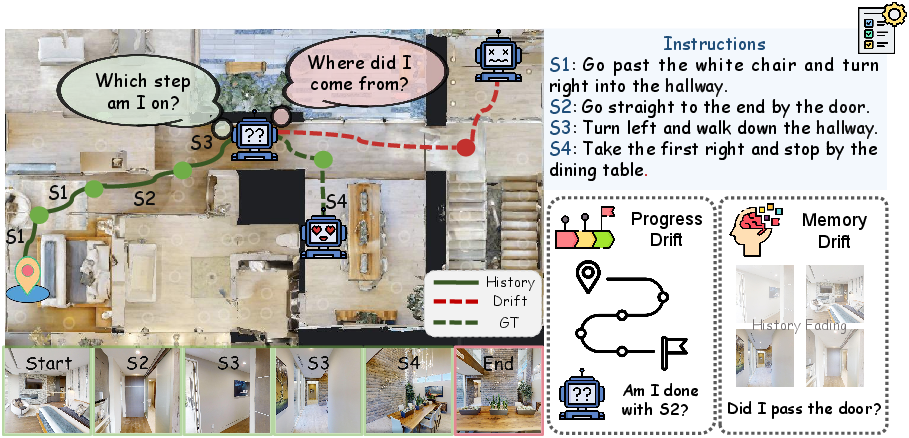
Figure 1: The Challenge of State Drift in long-horizon VLN, with progress and memory drift compounding navigation errors.
To address these issues, the authors propose a Dual-Anchoring Framework that explicitly regularizes and aligns the internal state of Video-LLM-based VLN agents at two axes: (1) Instruction Progress Anchoring, which supervises the agent to maintain structured, aligned mental checklists of completed and remaining sub-goals, and (2) Memory Landmark Anchoring, where the agent reconstructs dense object-centric representations from salient landmarks to preserve contextual memory. This approach is designed to ensure semantic alignment and mitigate perceptual aliasing, particularly critical for robust, interpretable, and generalizable navigation.
Dual-Anchoring Framework
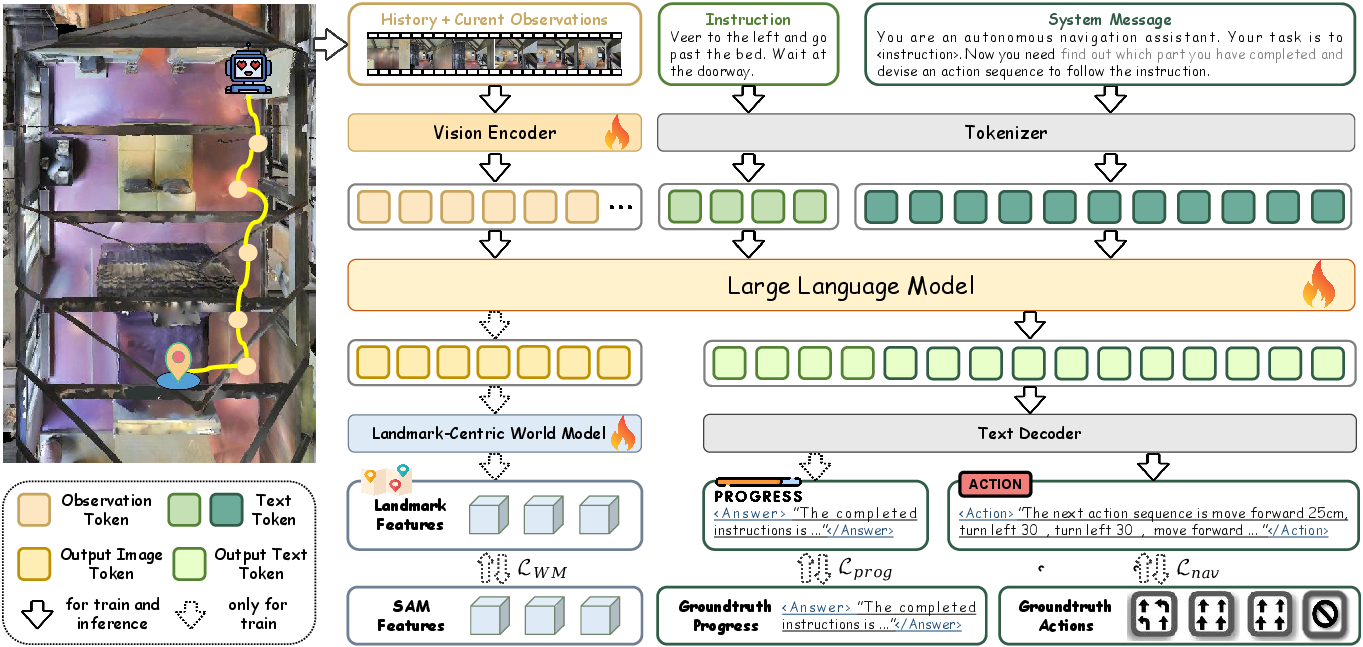
Figure 2: Overview of the Dual-Anchoring Framework, extending a streaming Video-LLM backbone with auxiliary supervision for instruction progress and memory anchoring.
Instruction Progress Anchoring
Instruction Progress Anchoring addresses Progress Drift by compelling the agent to generate semantically structured progress descriptions at each step, explicitly delineating subsumed versus pending sub-instructions. To obtain high-quality, fine-grained supervision, the framework synthesizes progress data at scale using a multimodal LLM with visual prompting, chain-of-thought reasoning, and instruction-aligned refinement.
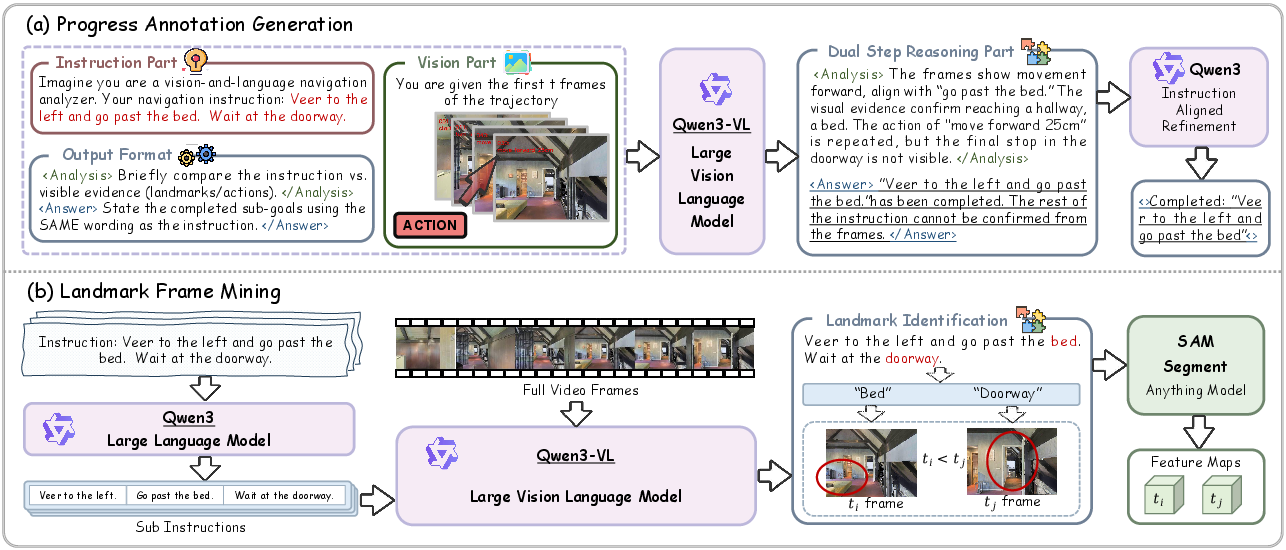
Figure 3: Data generation pipeline for (a) high-fidelity progress descriptions and (b) temporally grounded landmark frames with object-centric SAM features.
During training, these structured progress annotations are used as co-training targets, with action prediction conditioned on explicit declarations of instruction status. This supervision induces the agent to maintain a persistent, verifiable mapping between its decision process and instruction semantics, thereby preventing brittle or shortcut-driven policy learning.
Memory Landmark Anchoring
Memory Drift is attacked via Memory Landmark Anchoring, introducing a retrospective world modeling component. Here, the framework first decomposes instructions into atomic sub-goals, identifies temporal frames where referenced landmarks are encountered, and extracts their dense spatial features using the Segment Anything Model (SAM). The agent is then supervised to reconstruct these features from its internal video-LLM representations at each step, effectively creating a "rear-view mirror" mechanism. This spatially explicit loss grounds the agent’s memory in persistent, object-centric representations, fostering robust scene understanding and trajectory awareness.
Training Strategy and Data Composition
The methodology leverages an extensive, diverse mixture of standard navigation trajectories, self-collected progress/landmark datasets, DAgger rollouts, and general vision-language corpora to avoid overfitting and catastrophic forgetting. A two-stage training paradigm is adopted: navigation data pre-training with dual-anchoring objectives, followed by DAgger-augmented and vision-language fine-tuning.
Empirical Evaluation
Simulation Results

Figure 4: Qualitative comparison in simulation; baseline diverges due to drift, while Dual-Anchoring maintains trajectory fidelity and interpretable internal states.
Empirical results on R2R-CE and RxR-CE benchmarks demonstrate strong numerical gains: on R2R-CE, Success Rate (SR) increases from 56.9% to 65.6%, and on the more challenging RxR-CE, SR reaches 61.7%, a substantial improvement (+8.8% absolute) over the strong Video-LLM baseline. These improvements are especially pronounced on long-horizon trajectories (24.7% relative gain), validating the framework's critical utility for scaling VLN to real-world time horizons.
Ablation studies further corroborate the complementary nature of the two regularization branches. Instruction Progress Anchoring alone primarily boosts semantic alignment and immediate goal tracking (SR), while Memory Landmark Anchoring yields improvements in navigation efficiency (SPL) and error metrics. The combination consistently yields optimal results across data regimes.
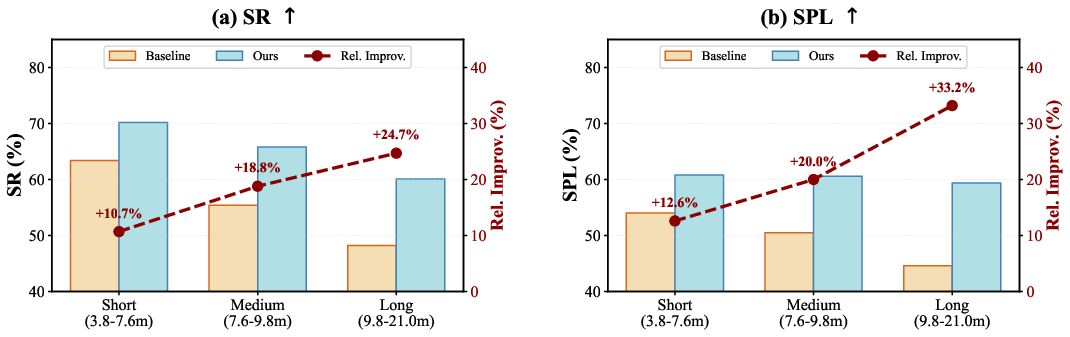
Figure 5: Success Rate and SPL improvements as a function of increasing trajectory length, highlighting enhanced stability of Dual-Anchoring under long horizons.
Data Quality and Real-World Generalization
Rigorously designed metrics demonstrate that the self-collected progress and landmark data possesses low hallucination rates and strong logical consistency; object-centric landmark frames are found in target locations at over 75% frequency (versus 13.9% random baseline). These robust signals drive downstream performance gains.

Figure 6: Real-world deployment on a quadruped robot, showing robust instruction-state tracking and domain transfer.
Zero-shot deployment on a Unitree Go2 quadruped robot validates transferability: the model, trained solely in simulation, correctly generates interpretable progress descriptions and remains robust to domain shift, mitigating state drift in real-world navigation tasks.
Implications, Theoretical Perspectives, and Future Directions
This work foregrounds the limitations of pure next-action supervised Video-LLMs for embodied navigation, especially in their inability to maintain persistent, grounded internal state representations across extended compositional tasks. The Dual-Anchoring Framework offers a principled augmentation: by integrating fine-grained, verifiable progress and history supervision, it explicitly couples the agent’s cognition to both instruction semantics and fixed visual anchors. This approach advances both the practical performance and interpretability of VLN policies, suggesting a broader design paradigm for embodied AI in which internal state must be explicitly regularized and grounded by structure-aware auxiliary constraints.
Future developments could extend dual-anchoring principles to online adaptation, interactive dialog navigation, and applications beyond navigation such as embodied instruction following with manipulation, general multi-modal sequential decision-making, or continual learning settings. Integration with SLAM-like scene graphs or richer memory architectures is also a promising trajectory for scaling context-awareness. The work opens avenues for using retrospective world models not merely for physical simulation but as continual trackers of semantic and episodic memory in agent architectures.
Conclusion
Dual-Anchoring establishes explicit state regularization as a critical component for robust, generalizable, and interpretable VLN in continuous 3D environments. By anchoring the agent’s cognition along both progress and memory axes, the proposed framework demonstrably overcomes the core limitations of prior Video-LLM navigators under long-horizon and real-world conditions, setting a new performance standard and theoretical baseline for state management in embodied foundation models (2604.17473).