- The paper introduces EHRAG, a hybrid hypergraph-based RAG that fuses structural and semantic hyperedges to enable robust multi-hop retrieval.
- It employs efficient BIRCH clustering and personalized PageRank to enhance entity aliasing and semantic diffusion across documents.
- Empirical results on benchmarks like HotpotQA and 2WikiMultiHop demonstrate significant gains in accuracy and scalability.
EHRAG: Hybrid Hypergraph-Based GraphRAG for Bridging Semantic Gaps
Motivation and Problem Statement
Efficient multi-hop retrieval is central to the utility of Retrieval-Augmented Generation (RAG) over large corpora, especially for queries that demand complex, transitive, or entity-aliased reasoning. While Graph-based RAG (GraphRAG) organizes text into structural graphs to support multi-hop chains, standard entity-relation extraction is computationally infeasible for web-scale corpora. Lightweight alternatives (e.g., LinearRAG) use NER and superficial co-occurrence, but fail to capture semantic relationships between non-cooccurring (disjoint) but synonymous or paraphrased entities, resulting in broken reasoning chains and severely degraded retrieval for multi-hop QA.
The paper introduces EHRAG—a Hybrid Hypergraph-based RAG framework—addressing the critical semantic gap in lightweight GraphRAG by augmenting structural co-occurrence with data-driven semantic hyperedges. This hybrid topology enables efficient, global entity aliasing and robust multi-hop reasoning without resorting to high-overhead LLM or relation extraction.
The semantic gap is succinctly illustrated as follows: structural graphs can only link entities that co-occur in the same context, leaving "monarch" and "Queen" (UK) disconnected if they are lexically or contextually distant, which prevents correct multi-hop chaining.

Figure 1: EHRAG bridges semantically related but structurally disjoint entities (e.g., "monarch" and "Queen") via semantic hyperedges, overcoming standard structural graph limitations for multi-hop retrieval.
EHRAG Framework
EHRAG comprises a biphasic pipeline: a linear-time offline construction phase and an online structure-semantic hybrid retrieval phase. Entity extraction/embedding and hyperedge construction remain scalable. Retrieval leverages structure-semantic diffusion and personalized PageRank to achieve both local context and latent semantic integration.
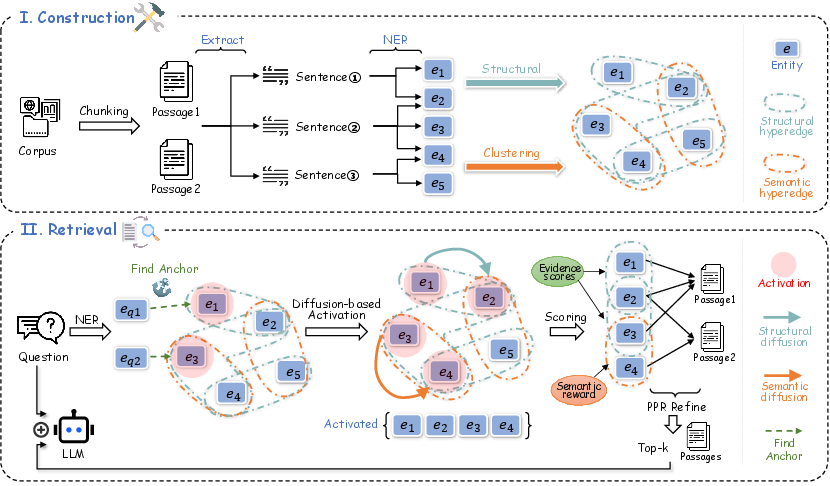
Figure 2: EHRAG pipeline: Offline extraction yields both structural hyperedges (sentence-level co-occurrence) and semantic hyperedges (latent topic clusters via entity embedding clustering). Online retrieval activates anchor nodes and diffuses scores hybridly for robust document ranking.
Hybrid Hypergraph Construction
- Structural hyperedges: Each sentence induces a set of structurally co-occurring entities, producing a sparse, context-preserving hypergraph topology that efficiently encodes explicit co-occurrence without O(N²) pairwise modeling.
- Semantic hyperedges: Entity embeddings are clustered (BIRCH) to form centroids, with each semantic hyperedge linking the top-D entities closest to a cluster centroid. Soft kernel-based weighting alleviates hard decision boundaries and supports semantic uncertainty.
- This hypergraph structure generalizes the pairwise connectivity of a simple graph, enabling high-order semantic connectivities crucial for cross-document/global entity aliasing.
Structure-Semantic Mixed Retrieval
- Anchor Initialization: Query NER extraction identifies entity anchors, matched to hypergraph nodes via embedding similarity.
- Diffusion Mechanism:
- Semantic diffusion (one-off): Anchor activations are projected across semantic hyperedges to include lexically/semantically similar entities, addressing synonymy/paraphrase and cross-document coreference.
- Iterative structural diffusion: Scores propagate across sentences structurally linked to the (semantically augmented) active set, using a query-gated filter for semantic relevance at each hop.
- Dynamic pruning and gating: Ensure only highly relevant nodes participate at each step.
- Topic-Aware Scoring and PPR Refinement:
- Passage scores are composed of global context match, explicit evidence score (weighted entity overlap), and a semantic reward for document topicality with the retrieved entity set.
- Personalized PageRank imposed on the hybrid subgraph enforces global node-passage consistency for the top-k ranking.
Theoretical Justification
A latent space model analysis establishes that the BIRCH-driven semantic hyperedges strictly tighten the probabilistic bound for connecting semantically similar nodes, even when structural co-occurrence is absent. This provably reduces the latent distance (in the latent Euclidean space sense) between relevant but structurally disconnected entities, which is impossible in the structural-only regime (cf. LinearRAG).
Empirical Results
EHRAG is evaluated on four multi-hop QA benchmarks:
- HotpotQA
- 2WikiMultiHop (notably high semantic aliasing)
- MuSiQue
- Medical (GraphRAG-Bench)
EHRAG consistently outperforms all strong baselines, including LLM-based extraction methods (GraphRAG, G-retriever), lightweight graph frameworks (LinearRAG, LightRAG), and neurobiologically-inspired diffusion (HippoRAG, HippoRAG2).
- On 2WikiMultiHop, EHRAG achieves +3.2% SubEM and +6.9% LLM-Acc improvements over the strongest lightweight baseline (LinearRAG), directly evidencing the semantic gap closure.
- On HotpotQA, +2.8% LLM-Acc.
- On specialized/long-context domains (Medical), EHRAG surpasses vanilla RAG and LLM-heavy graph methods, demonstrating robustness to domain shifts and structural noise.
Efficiency and Scalability
A comprehensive efficiency comparison demonstrates EHRAG’s zero token consumption for construction, and linear-time indexing and retrieval—on par with the most efficient current systems (e.g., LinearRAG).
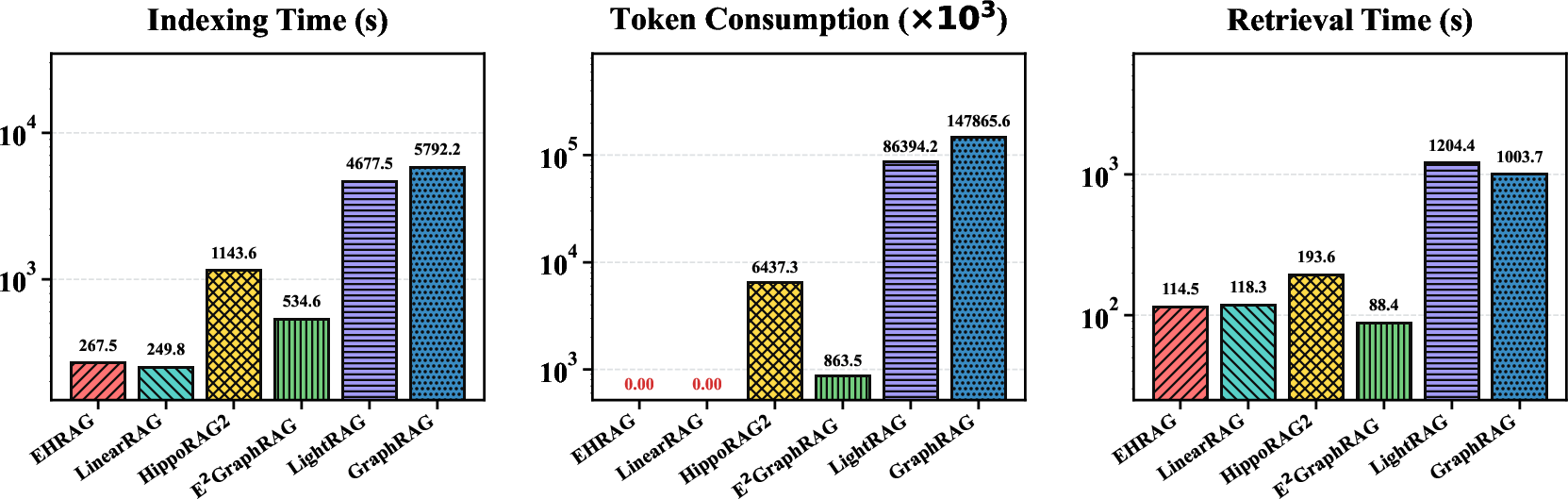
Figure 3: Efficiency analysis on 2WikiMultiHop: EHRAG achieves fast indexing and retrieval with zero token consumption, outperforming LLM-heavy and most existing lightweight methods.
- Core diffusion and topic-scoring steps consume only a minor fraction of end-to-end latency per query; bulk of computation lies in entity embedding and standard pipeline steps.
- The online query phase remains sublinear in corpus size due to efficient sparse matrix operations.
Robustness and Parameter Sensitivity
Parameter analysis demonstrates robust performance under variations of:
- Cluster size (D)
- Semantic decay (γ)
- Scoring weights (λ1, λ2)
Best practices: moderate D (≈100) and γ (<0.5) maximize semantic coverage without introducing noise; semantic reward weight λ2 is stable across datasets.
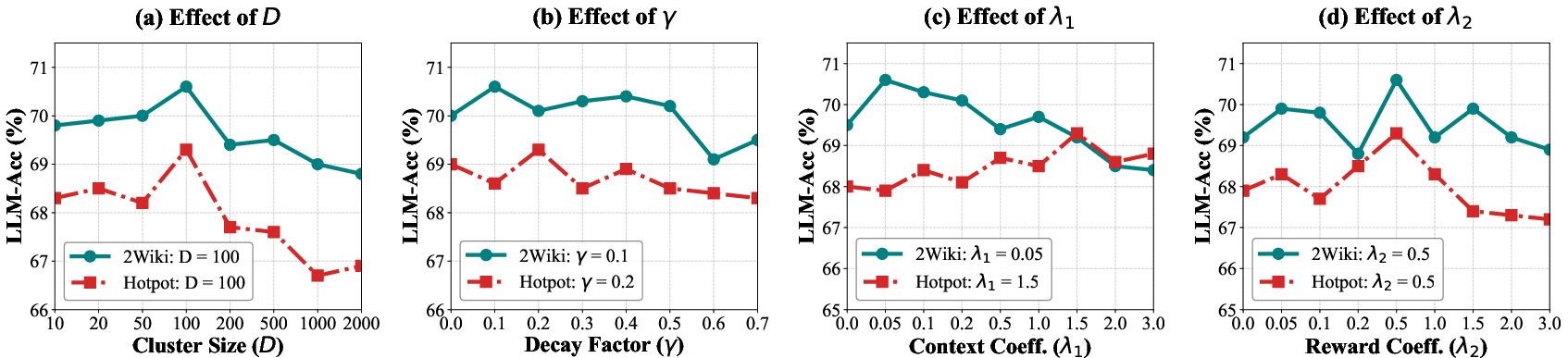
Figure 4: Sensitivity analysis for key hyperparameters across datasets reveals stable and robust optimums for semantic clustering and reward balancing.
Practical and Theoretical Implications
- EHRAG establishes that high-fidelity semantic integration in graph-based RAG is achievable without high-overhead LLM triple extraction or structural completeness.
- The approach scales to arbitrary corpus sizes, supporting real-world deployment in web-scale, federated, or streaming document settings.
- Generative QA systems can now routinely bridge the semantic gap in multi-hop and aliasing scenarios, including domain-specific corpora where entity surface forms, paraphrases, or domain-specific synonyms often evade structural-only extraction.
- Theoretical analysis grounded in latent space models supports EHRAG's guarantees for alias-bridging and multi-hop retrieval without information loss.
Future Directions
Extensions are suggested in:
- Adaptive hyperedge formation: Beyond BIRCH, online or contrastive methods for entity clustering.
- Multi-modal integration: Incorporating cross-modal entity linking in the hypergraph, e.g. with image or tabular anchors.
- End-to-end differentiable retrieval: Jointly tuning semantic diffusion weights or hyperedge strengths with generative model parameters.
Conclusion
EHRAG delivers principled, scalable, and robust multi-hop retrieval for RAG systems, closing the semantic gap inherent in structure-only graph construction, and achieves strong empirical gains over state-of-the-art on multi-hop QA. Its hybrid hypergraph design establishes a general template for future structure-semantic RAG architectures targeting knowledge-intensive tasks requiring deep entity chaining (2604.17458).

