- The paper introduces a hierarchical taxonomy that categorizes RL methods for LLMs under limited data regimes.
- It details innovative data pruning, synthesis, and compression techniques to maximize sample efficiency and reduce redundancy.
- The paper explores training-centric and framework-centric strategies, including advanced trajectory generation and self-evolving architectures, to bolster robust learning.
A Comprehensive Survey of Reinforcement Learning for LLMs under Data Scarcity: Challenges and Solutions
Introduction
The paper "A Survey of Reinforcement Learning for LLMs under Data Scarcity: Challenges and Solutions" (2604.17312) systematically investigates the intersection of data-efficient reinforcement learning (RL) and LLM post-training. Recognizing data scarcity as a fundamental bottleneck for RL-based LLM enhancement, the authors propose a hierarchical taxonomy to coherently categorize and analyze the fragmented research landscape. The taxonomy encompasses data-centric, training-centric, and framework-centric perspectives, enabling a comprehensive evaluation of methods designed to optimize both external data utilization and endogenous model capabilities under constrained data regimes.
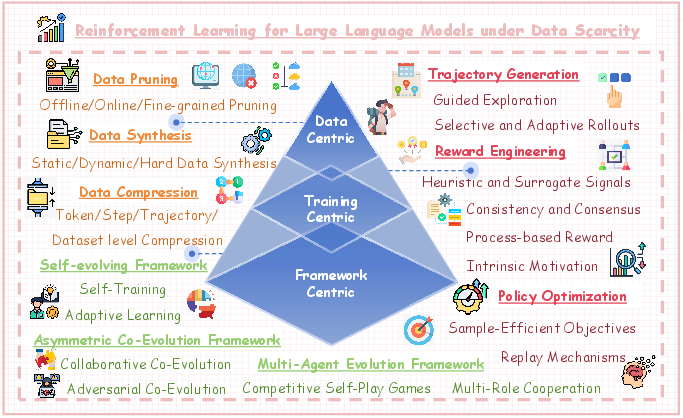
Figure 1: High-level overview of RL for LLMs under data scarcity, framing the field into data-, training-, and framework-centric design axes.
Taxonomy Overview
The paper introduces a bottom-up hierarchical taxonomy to classify RL approaches for LLMs under data scarcity. The three primary axes are:
- Data-centric perspective: Manipulation and optimization of data resources through pruning, synthesis, and compression to maximize the informativeness and efficiency of available training signals.
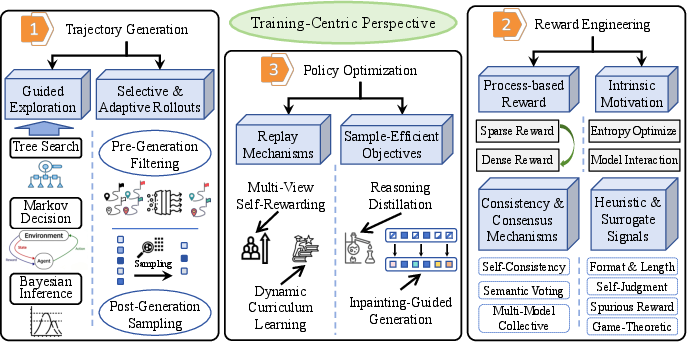
- Training-centric perspective: Innovations in trajectory generation, reward engineering, and policy optimization to improve learning dynamics when both supervision and trajectories are limited.
- Framework-centric perspective: Architectural shifts toward self-evolving, asymmetric co-evolution, and multi-agent paradigms, enabling autonomous curriculum generation, self-correction, and experience mining.
Each axis is further decomposed into sub-categories, formalizing the relationships and distinctions among current methodologies.
Data-Centric Perspective
The data-centric perspective is focused on maximizing the utility of scarce data. Three main strategies are emphasized:
- Data Pruning: Encompasses offline, online, and fine-grained methods to retain only high-information samples. Influence function-based ranking, dynamic online selection, and variance-based down-sampling emerge as core techniques to optimize learning curves and reduce the computational burden. Methods such as GAIN-RL and DOTS demonstrate that judicious selection based on prompt difficulty and trajectory informativeness can lead to significant sample-efficiency gains.
- Data Synthesis: Static, dynamic, and hardness-driven data synthesis strategies have emerged. Synthesizing preference data via strong LLMs (e.g., UltraChat, CodeUltraFeedback), multi-agent rule-based generation (Fellowship), and verifiable problem generation (Reasoning Gym, SynLogic, EvoSyn) all extend supervised coverage despite label constraints. Emerging works on dynamic synthesis, such as OAIF and SwS, tightly interleave the training loop with on-policy sample augmentation and weakness-focused problem generation.
- Data Compression: Methods such as token-level update-masking (High-Entropy Minority Tokens), trajectory replay filtering, and single-example "one-shot" RLVR highlight that large portions of RL training data are redundant or suboptimal. The finding that "one-shot" RLVR can match full-dataset performance especially underlines the presence of immense data redundancy in alignment tasks.
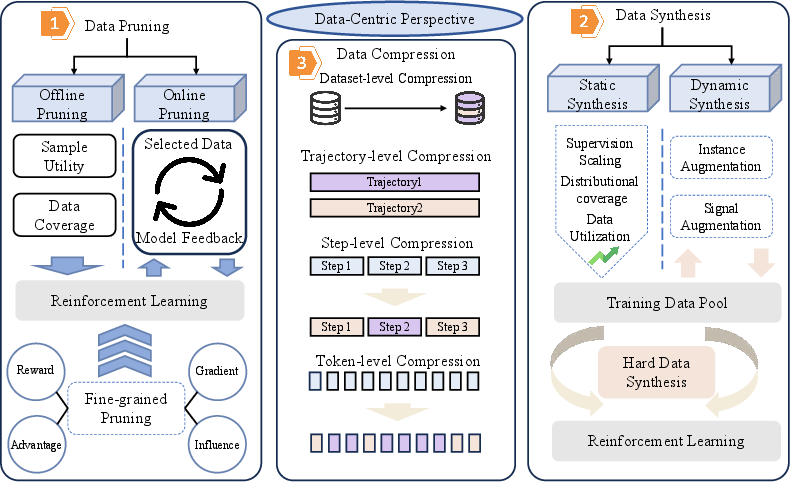
Figure 3: Schematic of various data-centric strategies for RL-based LLM improvement, including pruning, synthesis, and multi-level compression.
Training-Centric Perspective
The training-centric axis targets optimization of the RL process itself:
Framework-Centric Perspective
Beyond data and training specifics, the framework-centric perspective considers system-level designs capable of overcoming external data dependence:
- Self-Evolving Frameworks: Single-model systems exploit self-labeling, pseudo-rewarding, and self-verification (e.g., SeRL, SSR-Zero) to form a closed-loop learning cycle using only endogenous supervision. The paradigm of self-generated trajectories and rewards enables both scaling and safety challenges, although reward-hacking and model collapse remain unsolved.
- Asymmetric Co-Evolution: Dual-agent setups (e.g., proposer-solver architectures as in PasoDoble or adversarial settings like SPC and GAR) yield automatically generated curricula or dynamic verification, enriching learning signals via adversarial or cooperative interaction.
- Multi-Agent Evolution: Generalization to co-evolving populations (SPIRAL, SPELL, MAE) provides diverse, adaptive objectives and enables intricate multi-task curriculums, but at significantly increased computational cost and complexity.
Notably, these architectural shifts break the "echo chamber" phenomenon by introducing dynamic, often external, evaluation signals, facilitating both de-biasing and improved generalization.
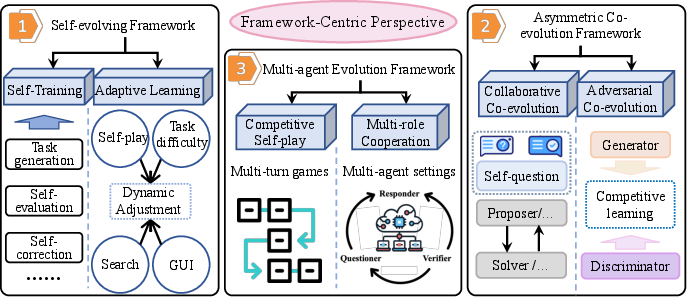
Figure 4: Illustration of framework-centric designs: self-evolution, asymmetric (adversarial/collaborative) co-evolution, and multi-agent evolutionary systems.
Thematic and Statistical Analysis
A temporal analysis shows a sharp surge in research output on data-efficient RL for LLMs, particularly from 2024 onward, underscoring the transition from niche innovation to mainstream focus within the LLM community.
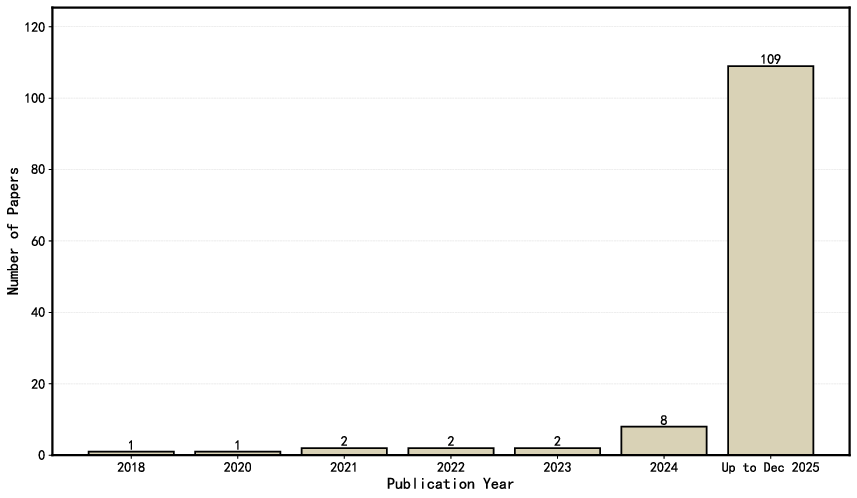
Figure 5: Distribution of publication years for papers in data-scarce RL for LLMs, highlighting recent acceleration.
Keyword analysis reveals "Reasoning," "Learning," and "Reinforcement" as the core methodological themes, corroborating the prevailing interest in self-improving, agentic, and verifiable alignment protocols in LLM research.

Figure 6: Title word cloud analysis, foregrounding the emphasis on reasoning, RL, self-evolution, and reward engineering.
Challenges, Limitations, and Future Directions
Outstanding challenges persist in:
- Internal Reward Reliability: Most methods heavily depend on consistency, entropy-based, or heuristic internal rewards, which are susceptible to reward hacking, model collapse, and feedback saturation. Robust process-based and hybrid reward engineering remains an open problem—especially for unverifiable or open-ended reasoning.
- Generalization Beyond Verifiable Tasks: Dominant benchmarks are restricted to mathematics or coding; the extension to subjective, creative, or embodied tasks is largely unexplored. Out-of-distribution generalization and safety are notably unresolved.
- Safety in Autonomous Frameworks: As self-play and self-evolving frameworks become more prominent, risks of self-amplified bias, unsafe curriculum generation, and deceptive behaviors escalate. Practical deployments will require online safety filters and insurance against compounding errors.
Conclusion
This survey establishes a unified, multi-level taxonomy for RL-based LLM training under data scarcity, dissecting the field along data, training, and architectural axes. The resulting framework elucidates both the limitations of simple data/computation scaling and the trajectories toward autonomous, data-efficient, and theoretically principled learning systems. Overall, the analysis identifies the critical transition from externally supervised, data-intensive paradigms to intrinsically motivated, self-correcting, and dynamically evolving RL protocols for advanced LLM development.