- The paper introduces HeadRank, which uses entropy-regularized attention head selection combined with ALPS to optimize passage reranking without generative decoding.
- It extracts fine-grained relevance signals from attention scores to overcome the homogenization problem in middle-ranked documents and improve discriminability.
- Experimental results across 14 benchmarks show that HeadRank outperforms existing methods by reducing latency and promoting relevant documents effectively.
HeadRank: Decoding-Free Passage Reranking via Preference-Aligned Attention Heads
Introduction
The HeadRank framework substantially advances the efficiency and discriminability of passage reranking with LLMs. Instead of relying on computationally expensive autoregressive generation or noisy attention heuristics, HeadRank extracts fine-grained relevance signals directly from preference-aligned attention heads. This approach mitigates the attention score homogenization that causes contextually "middle" documents to become indistinguishable—a major failure mode of previous decoding-free reranking solutions.
Problem Analysis and Method
Previous decoding-free rerankers leverage attention scores computed during a single prefill phase (without generation) to estimate document relevance, presenting massive latency benefits over generative methods. However, as context length increases, the attention patterns over candidate documents homogenize, especially in the middle ranks, resulting in a lack of discriminative power and weak listwise ranking (see Figure 1).
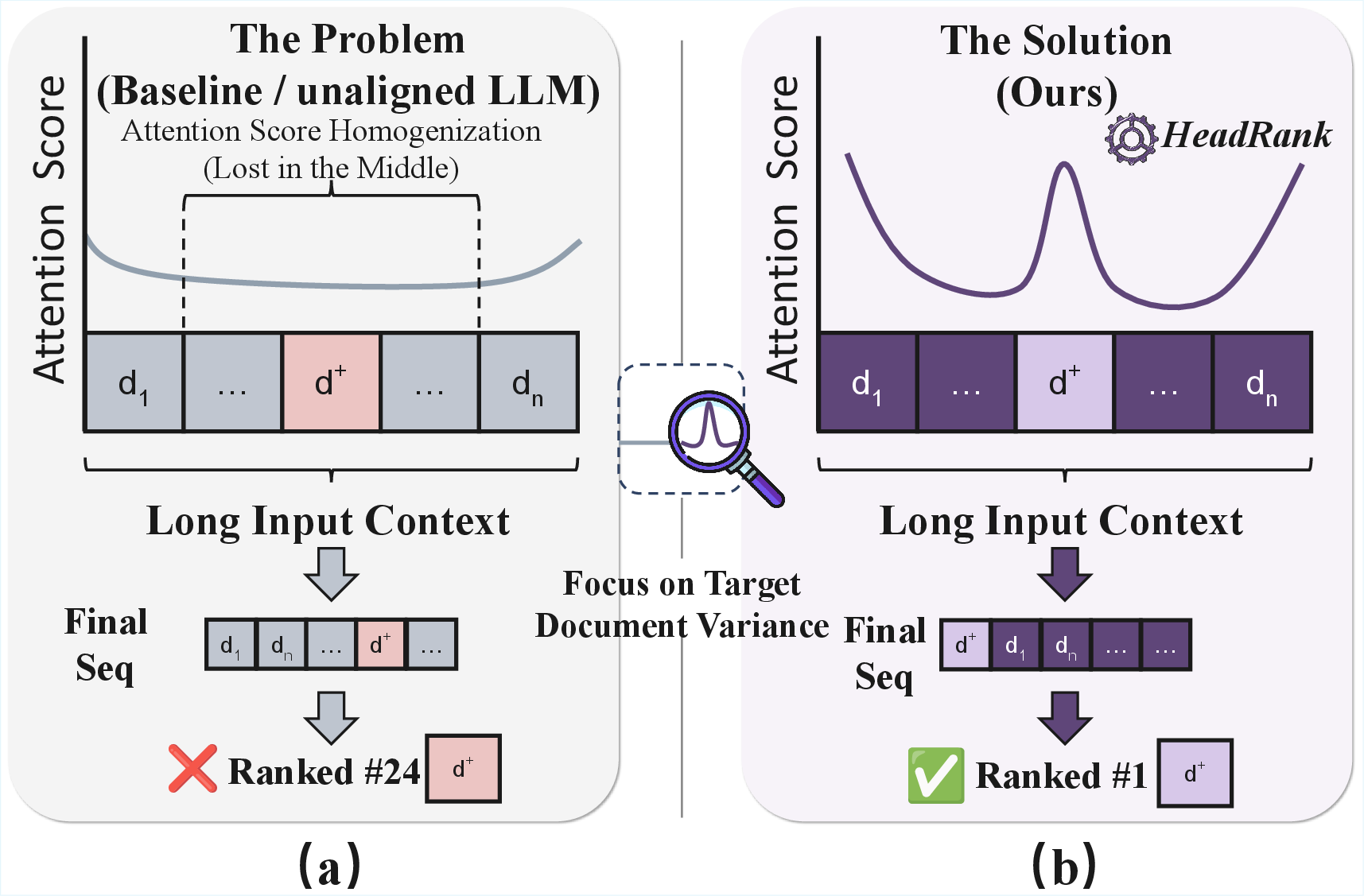
Figure 1: Comparison of reranking paradigms.
HeadRank addresses this by reframing reranker optimization as preference alignment directly in the Transformer attention space, removing dependence on output tokens. The method comprises three core contributions:
- Entropy-regularized head selection: Only attention heads demonstrating both high discriminability between relevance grades and low entropy (i.e., localized, stable attention) are used for scoring. This step removes noisy or diffuse heads and guarantees that relevance signals are sharp and structured.
- Adjacent-Level Preference Sampling (ALPS): Training pairs are strictly constructed from adjacent relevance levels, ensuring the hardest possible local contrasts. This supervision maximizes the information content of the preference signal, targeting the boundaries where fine-grained distinctions are essential.
- Attention-space DPO with score regularization: Direct Preference Optimization (DPO) is projected from token space to attention score distributions. The loss includes explicit regularization terms to minimize entropy and maximize variance among middle-zone candidate scores, directly combating "Lost in the Middle" attention collapse.
The framework also supports early-exit inference by truncating the forward pass at the deepest selected head layer, yielding fixed-complexity (O(1)) inference, in contrast to listwise generative rerankers which require O(N) decoding steps per query.
Experimental Results
Evaluation spans 14 passage retrieval and multihop reasoning benchmarks, using three Qwen3 model scales (0.6B, 1.7B, 4B). HeadRank is trained on only 211 MS MARCO queries, constructing ∼91K--200K preference pairs via ALPS.
HeadRank achieves strict improvements over both decoding-free (ICR, NIAH, QR-R, CoRe) and generative (RankGPT) baselines. On in-domain TREC-DL benchmarks, 4B-parameter HeadRank matches or exceeds all baselines, demonstrating the efficacy of attention-space preference alignment. Out-of-domain generalization is robust; with just 211 training queries, HeadRank outperforms all zero-shot baselines on BEIR and multi-hop benchmarks without overfitting (see Figure 2 for per-model visualization).
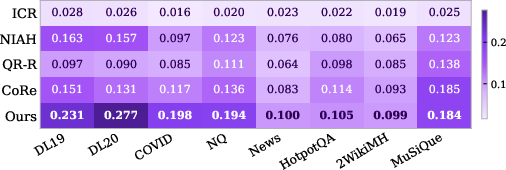
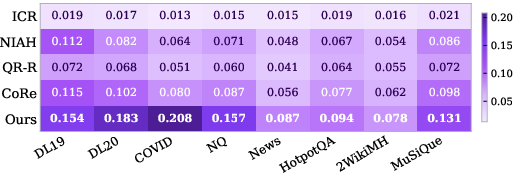
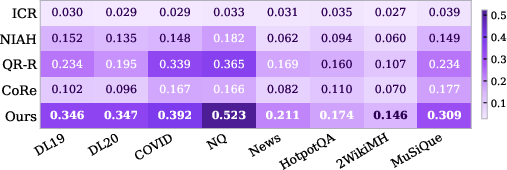
Figure 2: Qwen3-0.6B HeadRank model.
Crucially, the attention-based scoring mechanism ensures 100% output formatting success by construction, unlike generative approaches, which fail on up to 23.4% of queries due to malformed outputs.
Latency/quality tradeoffs are highlighted in Figure 3, showing that HeadRank occupies the Pareto frontier across latency tiers and model sizes. This is achieved without any generative decoding overhead, as relevance is scored pre-generation.
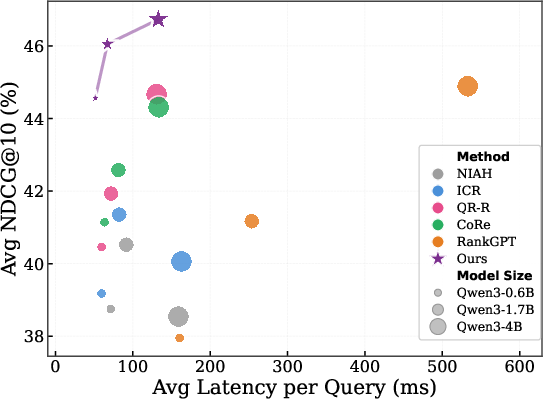
Figure 3: Inference latency vs. NDCG@10—HeadRank offers best accuracy at any latency/scale without decoding overhead.
HeadRank maintains high middle-zone variance after alignment, as detailed in the heatmaps of Figure 4. Standard deviation in this zone increases monotonically with model scale, reflecting improved discriminability. Baselines (especially ICR and NIAH) plateau or collapse, indicating persistent attention flatlining.
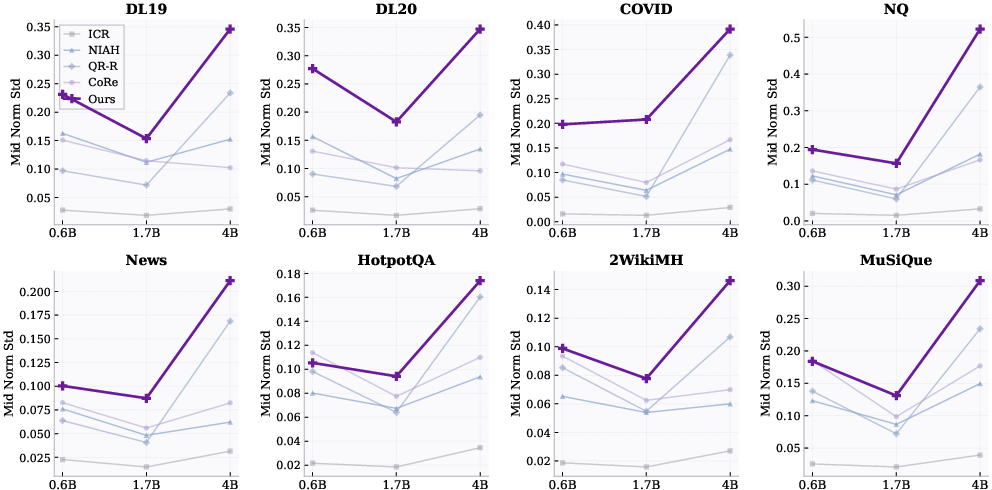
Figure 4: Scaling of normalized standard deviation in middle-zone attention scores, showing monotonic improvement with model size for HeadRank.
Structural and Mechanistic Insights
Deep analysis demonstrates that discriminability gains in the middle zone translate into correct document promotions. At 4B, 57.4% of relevant documents initially buried in the middle zone are promoted to the top quartile, compared to only 14.2% of irrelevant documents—a selectivity gap of 43 percentage points. This monotonic scaling is absent in all baselines and is visually confirmed in Figure 5.
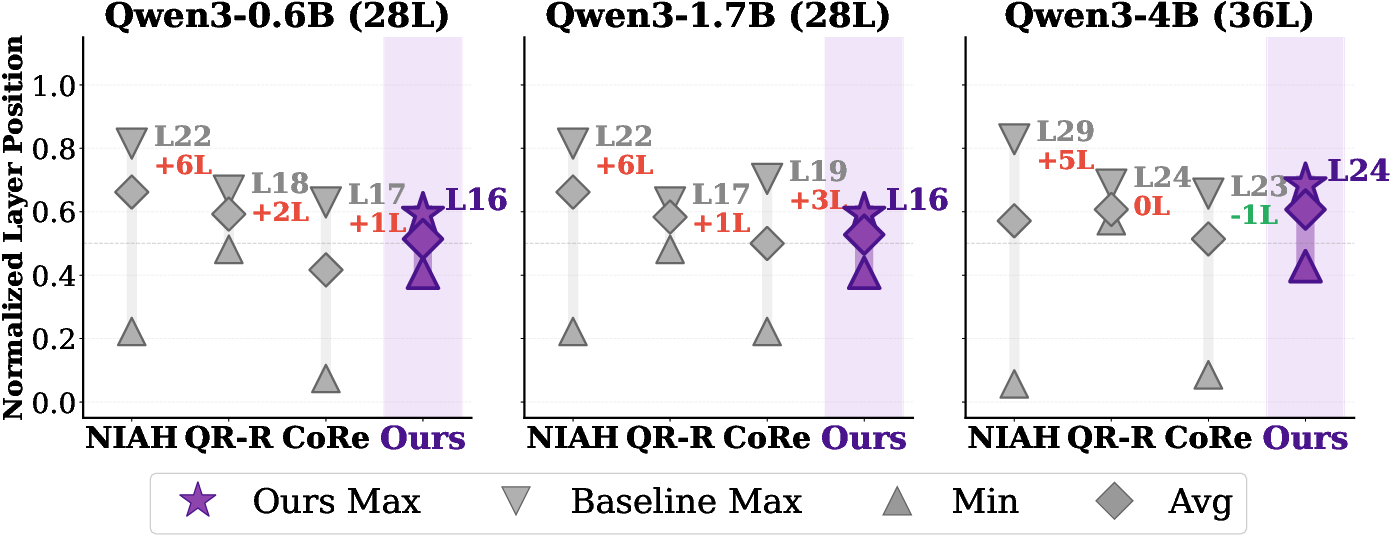
Figure 5: Depth distribution of selected core attention heads for Qwen3-0.6B; heads above the truncation threshold are omitted for early-exit inference.
The rationale for strict entropy gating and ALPS supervision is underlined by ablation: removing either catastrophically diminishes score variance, with global attention or randomly paired supervision yielding collapsed, non-discriminative outcomes. Replacing HeadRank’s DPO with traditional SFT further degrades performance and generalization, as unconstrained SFT distorts attention structure away from retrieval priors.
Practical and Theoretical Implications
HeadRank provides a principled path for aligning LLMs’ internal attention with external user or task preference signals, sidestepping the inefficiencies and reliability concerns of token-based generation. The entropy-regularized, middle-zone-biased regularization is key for overcoming the "Lost in the Middle" effect, which has broad implications for listwise modeling in long-context retrieval, reasoning, and RAG settings.
Practically, this enables deployment of passage rerankers that are both fast (no decoding) and highly listwise-discriminative on large candidate pools, without the risk of non-conformant output. The method also supports structural efficiency via early-exit, reducing FLOP requirements by only running up to the deepest selected head layer rather than the full Transformer stack.
Theoretically, HeadRank demonstrates that attention-space modeling—when preference-optimized—can recover and even surpass the discriminative capacity of generative listwise rerankers, without entangling the optimization in discrete generation artifacts.
Future Directions
Potential extensions include:
- Dynamic (query-adaptive) head selection to further sharpen instance-specific discriminability, particularly for heterogeneous query distributions.
- Training-time efficiency improvements through targeted layer freezing: since selected core heads reside within a strict set of layers, freezing the remainder during optimization could substantially reduce memory and compute requirements.
- Generalizing the regularization scheme for other preferences (e.g., fairness, bias control) in LLM retrieval architectures.
Conclusion
HeadRank reframes passage reranking as direct preference optimization over continuous attention structures, achieving robust generalization, strong listwise discriminability, and O(1) latency by design. The framework realizes theoretical and practical speed improvements while maintaining or exceeding the ranking precision of established autoregressive or attention-based baselines. These advances position HeadRank as a compelling solution for both research and production retrieval pipelines across LLM architectures.

