- The paper demonstrates that hardware IR selection, not LLM choice, is the main determinant of simulation and synthesis success.
- It employs a comprehensive multi-IR, multi-model evaluation pipeline including simulation and physical FPGA synthesis to validate the representation-bottleneck hypothesis.
- The study reveals that LLM-generated designs favor simplicity, resulting in higher pass rates on constrained FPGAs compared to complex reference solutions.
From Natural Language to Silicon: Analysis of the Representation Bottleneck in LLM Hardware Design
Introduction
The paper "From Natural Language to Silicon: The Representation Bottleneck in LLM Hardware Design" (2604.17097) offers a comprehensive empirical study of the natural language (NL) to hardware compilation pipeline mediated by LLMs. It critically examines the role of hardware Intermediate Representation (IR) selection in the synthesis of deployable designs from natural language specifications, measured through simulation, hardware implementability, and repairability. The core finding is that IR choice, not LLM choice, dominates end-to-end success—a phenomenon defined as the representation bottleneck. The work is distinguished by an exhaustive, multi-IR, multi-model, end-to-end experimental pipeline and the first robust inclusion of physical FPGA synthesis as an evaluation target.
Evaluation Pipeline and Methodology
The experimental pipeline is formalized as a cascade of binary filters (Fig. 1), isolating distinct IR-dependent failure modes across three phases: lowering and compilation, functional verification via simulation, and hardware synthesis targeting physical FPGAs. Each phase not only isolates IR-specific error modes but also enables precise attribution of failure loci in the end-to-end flow.
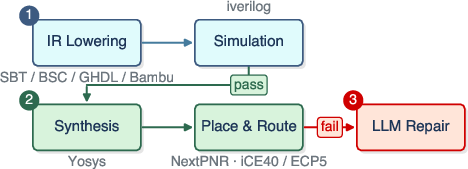
Figure 1: The evaluation pipeline processes an NL specification via LLM generation, IR lowering and simulation, FPGA synthesis, and repair, isolating distinct quality dimensions at each stage.
The NL-to-silicon pipeline is benchmarked on 202 design tasks sourced from VerilogEval and RTLLM, using three contemporary LLMs (Claude Sonnet 4.6, Gemini 3 Flash Preview, GPT-5.4) and six IRs spanning Verilog, VHDL, Chisel, Bluespec, PyMTL3, and HLS C. Synthesis is evaluated on resource-constrained (iCE40UP5K) and resource-rich (ECP5-85K) FPGAs to disambiguate code-quality failures from resource-exhaustion failures. All evaluation steps—prompt construction, IR lowering, simulation, synthesis, and iterative LLM-based minimal repair—are automated and quantitatively tracked.
Empirical Findings
IR Selection Versus Model Selection
The data reveals that simulation and hardware implementation pass rates are far more sensitive to hardware IR choice than to LLM backend. For a fixed model, simulation pass rates vary approximately 3\%–88\% across IRs but only 1.25× across different LLMs for a given IR. This effect persists across both simulation and hardware mapping stages, indicating that the primary bottleneck is not generation but representation—and model scaling alone yields diminishing returns once IR-induced attrition saturates.
Simulation Bottleneck Dominates Hardware Synthesis
A striking pattern is that the attrition bottleneck is almost entirely located in the pipeline's frontend—IR lowering and simulation. Once a candidate survives simulation, synthesis pass rates on iCE40 and ECP5 are uniformly high (83\%–100\%). The contrast between Verilog (best simulation pass rates due to open-source dominance in LLM training corpora) and HLS C (lowest due to toolchain interface mismatches) validates the representation-bottleneck hypothesis. Notably, HLS C designs often fail due to systematic incompatibility between synthesized interface protocols and standard testbench assumptions, reflecting not a shortfall in LLM capabilities but a structural ecosystem barrier.
Simplicity Bias in LLM-Generated Designs
LLMs, due to corpus and prior bias, generate structurally simple, small designs, resulting in higher conditional hardware synthesis pass rates than dataset reference solutions on iCE40 (86.5\% vs. 68.7\%). Crucially, this is not a claim of superior functionality but rather a byproduct of simplicity—LLMs infrequently generate designs that overrun FPGA resource budgets, while reference designs often employ complex idioms leading to hardware mapping failures on constrained devices. Dual-target diagnostic runs demonstrate that reference designs recover on the resource-rich ECP5, confirming resource-centric failure modes.
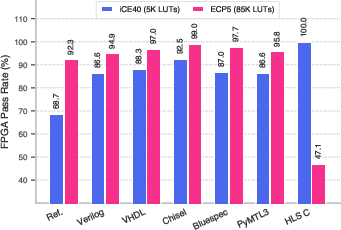
Figure 2: FPGA pass rates by IR and target show LLM-generated designs gain less from larger devices (ECP5) compared to reference, evidencing simplicity-induced resource fit.
Accessibility-Competence Paradox
An accessibility–competence paradox is evident: IRs with the lowest abstraction barriers for zero-knowledge users (HLS C, PyMTL3) yield the worst LLM performance, while less accessible IRs such as Chisel approach perfect synthesis pass rates. The root cause is training data economics—LLM competence correlates with corpus prevalence, not language abstraction level or synthesis-friendliness.
Compilation latencies for IR lowering and synthesis vary by two orders of magnitude (0.1 s for Verilog up to 30 s for Chisel, primarily due to JVM/Scala overhead). Nonetheless, maximum frequency (fmax) is nearly invariant across IRs, as Yosys/NextPNR normalization dominates backend mapping. Thus, IR selection impacts throughput and user experience significantly, especially in rapid prototyping or agent-in-the-loop regimes.
Theoretical Implications and Evolution of IR Strategy
This work formalizes the representation bottleneck and demonstrates that it is currently dominated by architectural, not model-based, factors. As LLM training data broadens—a near certainty with increased IR diversity in public and synthetic repositories—the optimal IR for NL-to-hardware flows is expected to migrate up the abstraction hierarchy. Higher-abstraction IRs (e.g., Chisel, Bluespec) already offer latent advantages in regularity, metaprogrammability, and structural verifiability once LLMs achieve basic code-generation competence.
The broader implication is that the NL-to-silicon stack should not blindly adhere to legacy HDLs intended for human experts but should consider the development of LLM-native IRs that maximize both generation and synthesis efficiency, perhaps borrowing from compiler theory's lessons on IR design.
Practical Takeaways and Future Prospects
- For current zero-knowledge NL-to-hardware applications, Verilog is the safest IR, balancing simulation pass rate, repairability, and toolchain speed.
- Chisel offers superior synthesis robustness on designs passing simulation, albeit with higher toolchain latency, and will become more attractive as corpora grow.
- HLS C and PyMTL3 are currently inconsistent choices due to training-data and verification-ecosystem mismatches.
- Future work should target domain-tuned IR augmentation, LLM fine-tuning for underrepresented IRs, and the development of verification-aligned, LLM-favored IRs rather than continued model scaling.
- Synthetic training data, transfer learning, and toolchain-in-the-loop adaptations are promising vectors for closing the accessibility–competence gap.
Conclusion
The paper delivers a rigorous end-to-end analysis of LLM-driven NL-to-silicon pipelines, exposing hardware IR selection as the central determinant of compilation and deployability success—a finding with strong implications for both academic research and toolchain development in AI-driven hardware design. The results highlight the persistent, IR-driven architecture of the representation bottleneck, the structural effects of LLM bias, and the shifting optimality frontier for hardware IRs as LLM competence evolves. Understanding and leveraging these phenomena are prerequisites for designing scalable, accessible, and reliable NL-to-hardware flows as LLMs progress beyond contemporary baselines.