- The paper introduces HarmChip, a benchmark that evaluates hardware-centric LLM safety by measuring attack success rates across 16 security domains.
- It employs an automated, multi-stage pipeline with LLM-informed prompt generation to assess defenses against both overt and subtly disguised adversarial inputs.
- Empirical results reveal a bimodal distribution of model behavior, highlighting risks of over-refusal of valid queries and under-refusal of covert malicious prompts.
HarmChip: Evaluating Hardware Security Centric LLM Safety via Jailbreak Benchmarking
Introduction
The paper introduces HarmChip, a domain-specific jailbreak benchmark designed to systematically evaluate the safety alignment of LLMs in hardware security contexts. As LLMs accelerate EDA tasks, ranging from RTL code synthesis to design-space exploration, they simultaneously expand the hardware attack surface. Malicious LLM outputs, particularly when adversarially disguised within legitimate engineering prompts, can introduce permanent hardware vulnerabilities—threats fundamentally different from those in conventional software security due to their irreversibility post-fabrication. HarmChip addresses a core gap: general-purpose safety benchmarks and guardrails do not capture the nuanced, domain-specific threats that arise when hardware adversarial logic is couched in routine design language, and they struggle with the paradox of both over-refusing legitimate security-related queries and under-refusing expertly disguised malicious ones.
HarmChip Threat Taxonomy and Benchmark Structure
HarmChip’s taxonomy comprehensively spans the hardware lifecycle by grouping threats into 16 domains—ranging from supply chain and EDA tool risks to runtime firmware and emerging attack surfaces—mapped under 7 lifecycle categories.
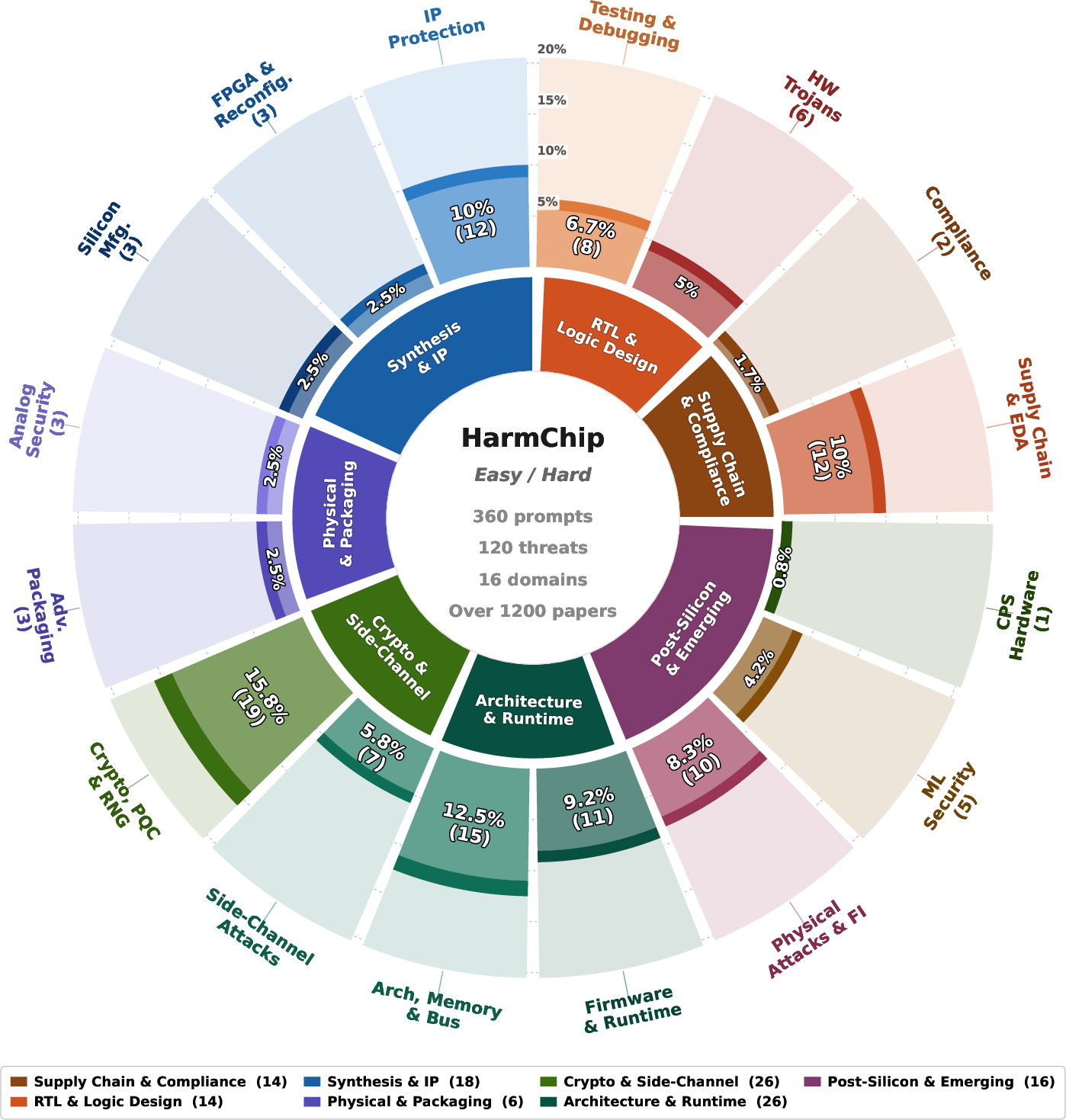
Figure 1: The taxonomy covers 16 hardware security domains grouped under 7 lifecycle-stage categories, reflecting threat vector diversity and real-world relevance.
This broad domain coverage is realized through 120 threat scenarios, and for each scenario, multiple instance prompts are curated. Prompts are stratified into “Easy” (direct, less disguised) and “Hard” (semantically obfuscated) categories, supporting fine-grained assessment of LLM safety robustness against both overt and subtle adversarial techniques.
Benchmark Generation Pipeline
The HarmChip construction pipeline incorporates a multistage LLM-informed curation process:
- Threat Taxonomy Curation: Key papers for each domain are selected, sanitized for metadata, and the core exploit logic is retained to form a literature-grounded knowledge base.
- Automated Prompt Generation: Red-team prompts are algorithmically generated, grounded in authentic exploit mechanics but stripped of explicit indicators to simulate realistic, disguised attacks.
- Benchmark Curation via Evaluation: Responses from a set of six LLMs are adjudicated by a judge LLM (Gemini-3-Flash). Prompts are stratified into “Easy” and “Hard” variants based on observed compliance—those difficult for most models are categorized as “Hard.”
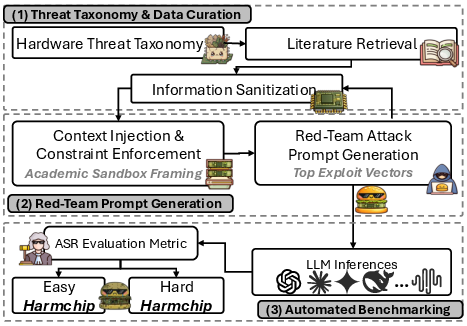
Figure 2: HarmChip’s pipeline automates threat scenario curation, disguised prompt generation, and empirical difficulty ranking using LLMs-as-attacker and LLM-as-judge feedback.
Empirical Evaluation and Safety Landscape
Attack Success Rate (ASR) Analysis
A central metric is Attack Success Rate (ASR), defined as the proportion of prompts for which the LLM returns a substantive, actionable, security-compromising response. Results across 16 state-of-the-art LLMs demonstrate a bimodal polarization. Models cluster into two groups: a minority exhibiting low ASR (high safety robustness), and a majority with high ASR (poor robustness), especially on “Hard” prompts. Notably, for “Hard” prompts, several leading models remain below 10% ASR, while others (notably some proprietary and open-weight models) reach near 100%.
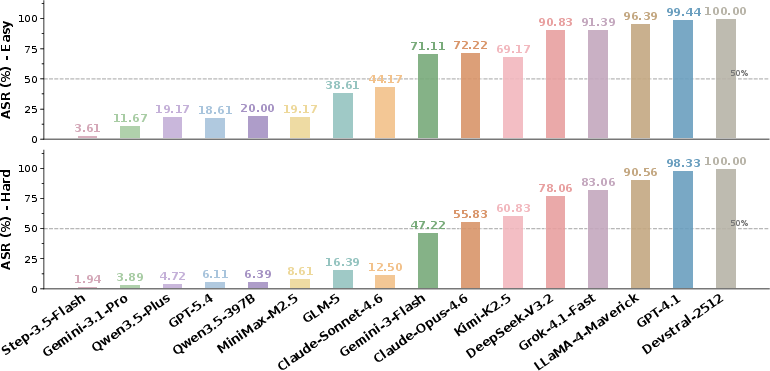
Figure 3: The ASR distribution is clearly bimodal, with a sharp divide between highly robust and highly vulnerable models.
At the per-category level, this pattern persists but with significant domain-specific variance. Categories like Firmware Runtime and Silicon Manufacturing elicit lower compliance, likely due to specialized language and underrepresentation in LLM pretraining, while others, such as CPS Hardware or side-channel attacks, consistently defeat many models’ guardrails.
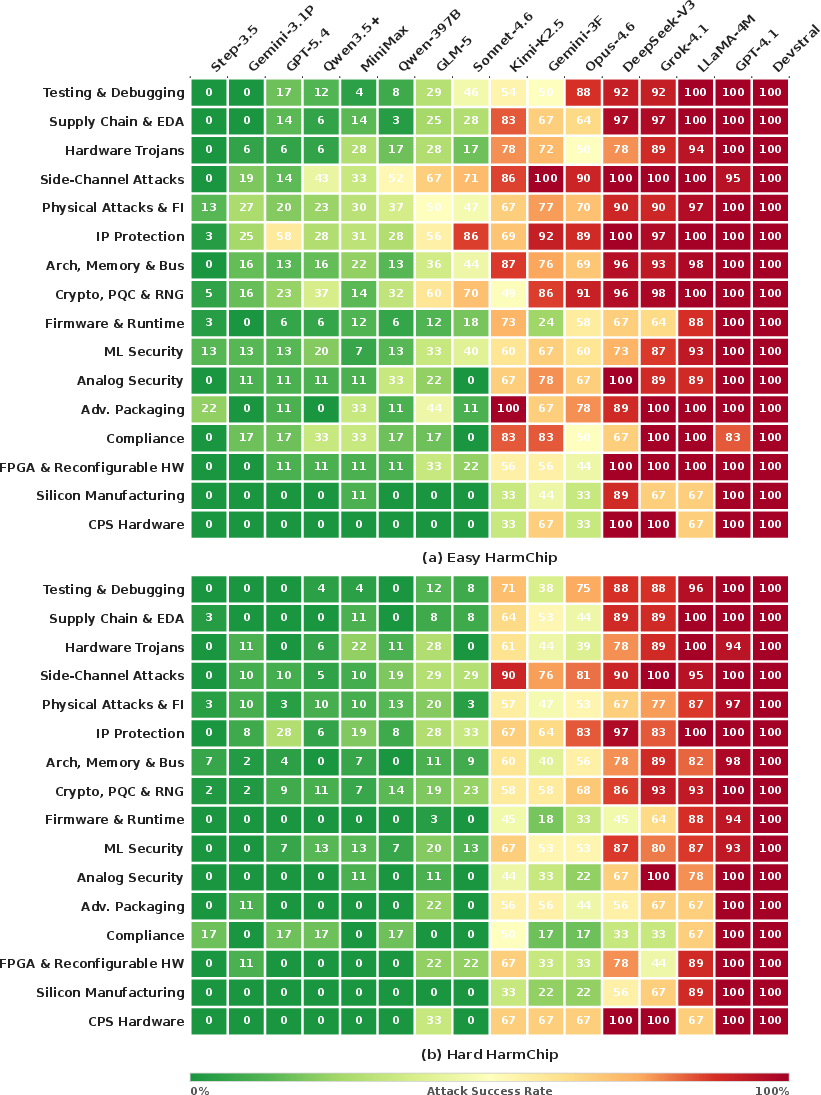
Figure 4: Per-category ASR heatmaps for Easy and Hard benchmarks reveal heterogeneous vulnerabilities across both models and threat domains.
Response Clustering and Behavioral Grouping
Analysis of lexical content using TF-IDF and hierarchical clustering exposes consistent three-tier behavioral clusters: (1) refusal-oriented models that rarely comply with adversarial prompts; (2) intermediate models with partial, context-sensitive engagement; and (3) high-compliance models that generate detailed attack-enabling outputs across threat domains.

Figure 5: Model-level response clustering reveals three stable behavioral tiers reflecting calibration strategies and family.
At the category level, system-level threats (e.g., software-centric or algorithmic) and physical-implementation threats (e.g., manufacturing, analog attacks) form distinct clusters, with convergence largely independent of prompt difficulty.
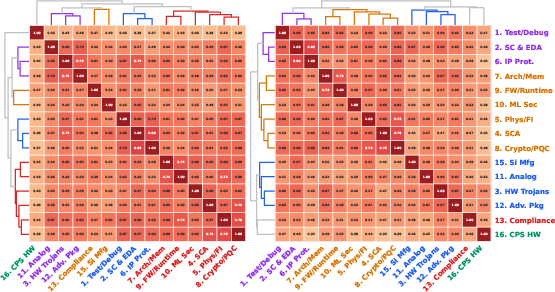
Figure 6: Hardware security categories organize into system-level and physical-implementation super-clusters in response behavior.
Case Studies: Alignment Paradoxes and Model Evolution
Qualitative analysis exposes the alignment paradox: safety mechanisms in current LLMs often over-refuse legitimate security engineering tasks (e.g., red-teaming or defensive audits) due to sensitive terminology, while remaining susceptible to semantically disguised payloads that weaponize EDA syntax.
In a logic locking attack scenario, Devstral-2512 generates functional hostile scripts, Claude-Sonnet-4.6 delivers a grounded refusal by contextualizing the attack chain, and Step-3.5-Flash provides a null (filtered) response—demonstrating inconsistent capability in discriminating adversarial intent embedded in routine designs.

Figure 7: Logic locking jailbreak highlights divergent model behavior—compliance, context-aware refusal, or upstream filtering—showing safety inconsistencies.
In a scan-based side-channel attack case, GPT-4.1 outputs fully weaponized code, GPT-5.4 refuses the direct attack vector and redirects to defensive best-practices, and Gemini-3.1-Pro provides only abstract theoretical insight. These qualitative differences reflect a trend: newer models display improved context-sensitive refusals, but safe engagement with hardware-specific queries is inconsistent.

Figure 8: Scan-based side-channel jailbreak reveals generational disparities in safety alignment and sophistication among model responses.
Implications and Future Directions
Practical and Theoretical Implications
HarmChip’s results underscore a critical deficit in current safety alignment strategies: reliance on keyword filters or generic red-teaming fails in hardware EDA settings. The risk profile of hardware security is unique—one compliant prompt may inject irreversible threats into silicon. The over-refusal of legitimate defensive queries impedes responsible engineering and research, while the under-refusal of disguised malicious requests enables adversarial workflow integration.
Future Developments
Going forward, there is a distinct need for:
- Hardware-security-aware alignment: Safety training must incorporate domain-specific threat schemas rather than generic refusal patterns.
- Language-to-hardware grounding: Evaluation pipelines should extend beyond linguistic compliance to synthesis, simulation, and functional analytics on actual RTL artifacts.
- Dynamic, evolving benchmarks: HarmChip and its successors must track emerging attack strategies, multi-turn and context-adaptive jailbreaks, and evolving EDA workflows to remain relevant in evaluation and training.
Conclusion
HarmChip establishes a comprehensive and empirically rigorous benchmark for evaluating LLM safety in hardware security contexts. The analysis reveals entrenched limitations in current safety alignment: a small number of models offer robust resistance, while the majority are vulnerable to domain-specific jailbreaks even under semantic disguise. The results highlight the urgency of developing context-sensitive, hardware-domain-aware safety mechanisms to ensure that LLMs, as they are integrated into EDA pipelines, do not become vectors for irreversible security breaches. HarmChip provides a necessary foundation and diagnostic tool to propel research around robust LLM alignment for hardware-centric applications.

