- The paper demonstrates that HPC containerization can fully leverage unmodified cloud-native engines by integrating explicit orchestration layers.
- It introduces an Environment Definition File that enables portable runtime specifications, scalable image access, and dynamic host resource injection.
- Experimental results show similar scaling and lower startup latency compared to Enroot+Pyxis, validating its efficiency across diverse HPC workloads.
Sarus Suite: Upstream-Aligned, Cloud-Native Containerization for HPC
Introduction
The Sarus Suite proposes a fundamentally upstream-aligned architectural approach to HPC containerization, decoupling portable image semantics from site- and system-specific integration while preserving direct continuity with cloud-native Open Container Initiative (OCI) standards and tooling. Built around an unmodified Podman engine, Sarus Suite introduces explicit system layers for declarative runtime specification, scalable image access, scheduler-native execution, and controlled host capability injection. This essay presents a technical analysis of the Sarus Suite architecture and its implications for production HPC—both practical and theoretical—highlighting architectural decisions, implementation realities, and quantified experimental results.
Architectural Model and Execution Semantics
Sarus Suite is predicated on the argument that HPC requirements—scheduler-awareness, scalable startup, and integration with specialized hardware and communication stacks—should be handled at the system integration layer, with the container engine left fully aligned with upstream cloud-native evolution.
The execution model centers on four architectural pillars:
- Declarative Runtime Specification: The Environment Definition File (EDF) encapsulates all container execution semantics, decoupling them from both image construction and launch-time scripting. EDFs combine image references, mount binds, working directory, device exposure (via CDI), and integration requests (as OCI annotations) into a reusable, versionable specification object. This enables stable, portable, and shareable runtime contracts abstracted from site-specific instantiation logic.
- Scalable Image Access: The Parallax component provides an HPC-optimized shared image store based on SquashFS and FUSE, supporting efficient, concurrent access and eliminating the I/O and metadata pressure associated with repeated untarring/unpacking of layered OCI images on parallel filesystems. Parallax implements “pull-once, run-everywhere” semantics compatible with both rootless and privileged deployment, leveraging image flattening and user ID mapping at the FUSE layer.
- Controlled Host-Capability Injection: Through a combination of CDI specifications and OCI runtime hooks, host-specific libraries (e.g., CUDA/communication stacks), devices, and configuration files are injected at container start, enabling late binding of essential runtime dependencies without sacrificing image portability. This supports both static and dynamic resource descriptor models (CDI and precreate/prestart hooks) and allows for transparent ABI compatibility enforcement for high-performance communication stacks.
- Scheduler-Native Execution: The Skybox SPANK plugin integrates container creation directly into the Slurm job lifecycle. It enforces a one-container-per-node strategy (rather than per-rank) and places ranks into container namespaces via
setns, maintaining full scheduler control over process placement and accounting. This model enables minimal overhead attachment and preserves expected isolation properties in an HPC context.
After EDF specification and image provisioning, interactive and job submission workflows are unified. Users validate EDFs and perform image staging interactively with sarusctl, while production launches execute containers at scale using Slurm with the same artifacts. The Skybox execution model is illustrated below.
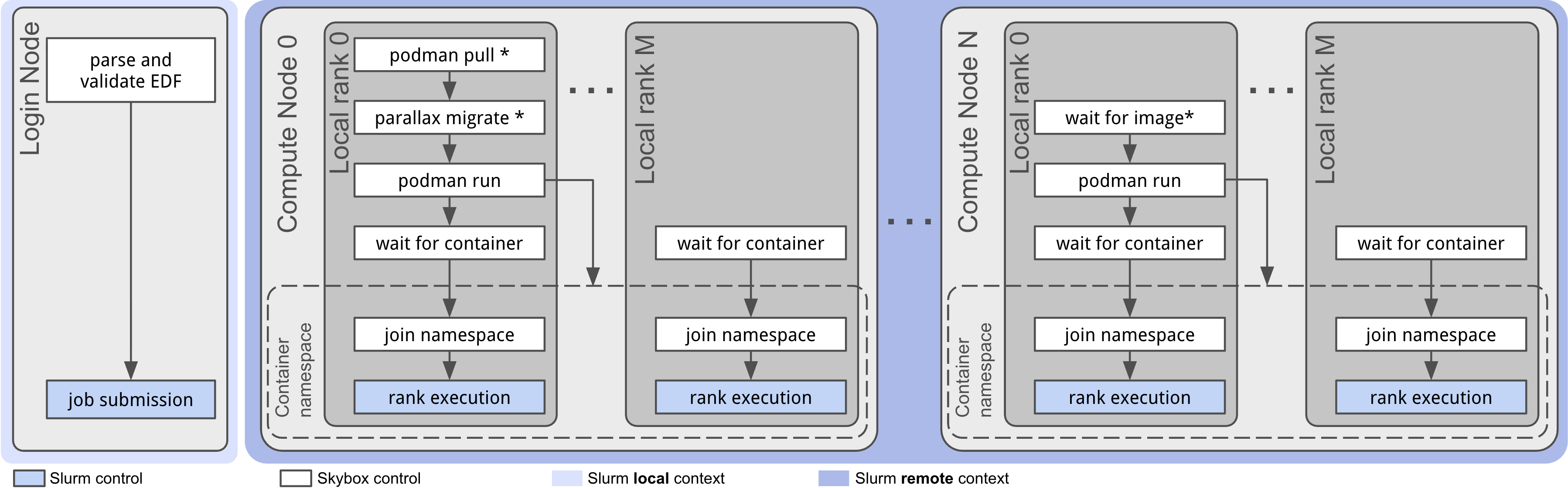
Figure 2: Skybox execution model under Slurm, highlighting job-wide EDF rendering, image acquisition and per-node container startup, with namespace joining by multiple ranks.
This architecture positions Sarus Suite as an integration stack—deployable independently of the underlying container engine—allowing frictionless adoption of cloud workflows (including Kubernetes manifest-driven multi-container pods and direct OCI registry usage) within the constraints of highly optimized, resource-managed HPC environments.
Implementation Details
The implementation divides responsibilities among composable tools:
- EDF (Environment Definition File): Written in TOML, specifying the complete container environment and integration requests. EDFs are system-agnostic, with site-policy mapping handled at instantiation time.
- Sarusctl: CLI for EDF management, interactive runs, and image migration; exposes a uniform model across development and production.
- Skybox: Slurm SPANK plugin for job lifecycle integration, orchestrating container creation, rank namespace entry, and hooks/CDI resource activation.
- Parallax: OCI-compatible image migrator and custom overlay mount program; supports cross-filesystem SquashFS storage and user ID mapping at mount time, transparently resolving permission mismatches for rootless users.
- CDI and OCI hooks: Site-managed Rust binaries for device and library injection, supporting dynamic linking and configuration for optimal host integration (including custom MPI/NCCL/provider injections and dynamic linker cache synchronization).
These components collectively realize a model where EDF/manifest-driven specifications determine runtime instantiation—with system configuration, policy, and resource access kept strictly external to container images and workflows.
Experimental Results
The suite is validated experimentally on a production Cray EX GH200 system across representative benchmarks: communication-intensive scientific codes (PyFR, SPH-EXA), metadata-heavy Python startup (Pynamic), and large-scale AI (Megatron-LM). Primary comparison is against Enroot+Pyxis, the reference production HPC container stack.
PyFR: OpenMPI, Strong Scaling
PyFR results show that Sarus Suite delivers virtually identical net simulation time and speedup compared to Enroot+Pyxis, scaling from 32 to 1024 GPUs with a parallel efficiency of 69.6% at the largest node count.
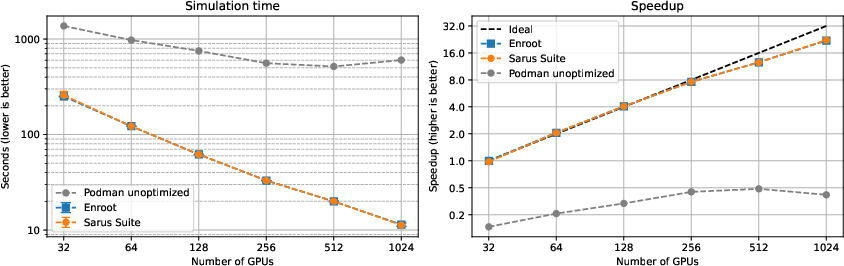
Figure 4: PyFR performance and speedup on up to 1024 GPUs; Sarus Suite matches Enroot+Pyxis across the entire scaling envelope.
Unoptimized Podman fails to scale at such concurrency due to inadequate scheduler and network integration, highlighting the necessity of Sarus Suite’s integration architecture.
SPH-EXA: MPICH, Strong Scaling
SPH-EXA experiments confirm that the architectural claims generalize beyond OpenMPI, retaining 43.6% parallel efficiency at 256 GPUs. Again, Sarus Suite and Enroot+Pyxis are virtually indistinguishable in performance.
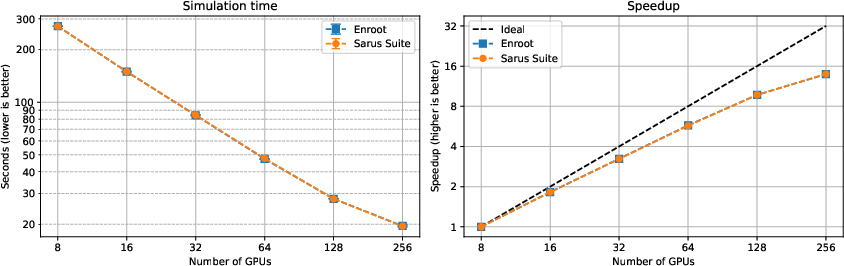
Figure 6: SPH-EXA strong scaling and speedup: Sarus Suite and Enroot+Pyxis attain identical scaling across 8–256 GPUs.
Megatron-LM: NCCL, Weak Scaling, NGC Images
For AI workloads dependent on complex site-optimized communication stacks, Sarus Suite supports running directly from upstream NVIDIA NGC images without any site-specific rebuild, delivering identical throughput per GPU up to 1024 GPUs and exposing the full performance of the Slingshot interconnect through late-bound host resource injection.
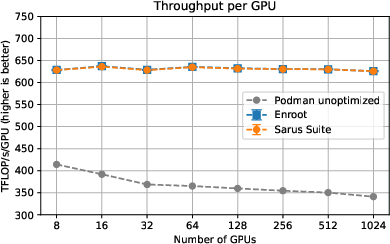
Figure 1: Megatron-LM per-GPU throughput: Sarus Suite achieves parity with Enroot+Pyxis using unmodified NGC containers.
Baseline Podman again exhibits rapid performance degradation with increased scale, underscoring the impact of missing scheduler and network stack integration.
For Pynamic, which stresses parallel metadata access during Python startup, Sarus Suite’s use of SquashFS-based image sharing ensures launch behavior is flat up to 128 nodes, with only gradual increases at higher scales, paralleling Enroot+Pyxis and outperforming plain Podman, which saturates parallel filesystem metadata servers.
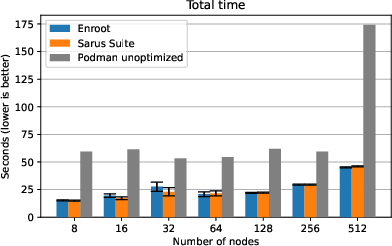
Figure 3: Pynamic startup and import times highlight the importance of Parallax’s scalable image staging for Python-dominated workloads.
Startup Latency
Measured per-node startup times demonstrate a consistent advantage (1.5−2.5× lower) for Sarus Suite over Enroot+Pyxis, with most overhead attributable to Podman’s internal initialization and EDF-driven orchestration overhead being negligible.
Cloud-Native and Composable Workflows
Sarus Suite’s model extends to the direct support of cloud-native, multi-container pod deployment using standard Kubernetes YAML manifests. This allows HPC sites to leverage modern compositional and staged workflow designs (including init containers, ephemeral shared storage, and pod-scoped annotations) without the introduction of heavyweight orchestration infrastructure. Site-optimized integrations (e.g., network hooks, GPU resource CDIs) remain accessible through manifest-driven annotations, maintaining exportable and portable workflow semantics within the bounds of HPC scheduling and resource management.
Implications and Future Directions
Practical Implications
Sarus Suite’s architectural model eliminates the divergence between production HPC and upstream “cloud-native” container engines, obviating the need for system maintenance of custom or divergent container runtimes. By exposing standard OCI workflows and direct registry interoperability, it addresses the accelerating cadence of AI/ML software evolution, enabling the use of externally maintained application artifacts (e.g., NGC, PyPI, Docker) without loss of performance or operational control. Thus, validation and promotion, as well as reproducibility, are improved while reducing local site adaptation and revalidation effort.
The scheduler-centric, one-container-per-node model enforces stable and predictable job placement, ownership, and accountability—key operational invariants in controlled, multi-tenant HPC settings—while providing minimal attach overhead and cross-rank resource sharing essential for high-performance communication. The integration of composable, multi-container pods through direct Kubernetes-manifest workflows further aligns site operations with the broader AI/ML software ecosystem.
Theoretical Considerations
The paper robustly demonstrates that there is no inherent requirement for divergent HPC-specific container runtimes to achieve optimal communication, scaling, or workflow performance, contradicting prior assumptions about the necessity for custom engines. The systematic separation of image specification, runtime intent, and host integration decompresses concerns, enabling explicit modeling of system policy and site-specific optimization without impeding upstream compatibility.
Furthermore, the late binding of host resources through dynamic injection ensures operational contracts can be preserved even under rapidly evolving hardware and software landscapes, facilitating forward compatibility as accelerator, networking, or scheduler technologies change.
Future Developments
From an AI/ML workflow perspective, Sarus Suite’s architecture is well positioned to support emerging patterns including:
- Tight integration with more complex orchestration models (Kubernetes-native or hybrid);
- Automatic, policy-driven mapping of workflow descriptions (e.g., Common Workflow Language, Nextflow) to HPC-optimized container launches;
- Support for dynamically composable environments and ephemeral resource claims (e.g., GPU partitioning, node-local NVMe staging);
- Extension to federated, cross-site execution where containerized environments must satisfy both local and global resource and policy constraints.
Extending explicit EDF-driven models to encapsulate data movement, artifact tracking, and cross-container orchestration semantics would further reduce the barrier to AI/ML system deployment at scale.
Conclusion
Sarus Suite demonstrates, quantitatively and architecturally, that full-featured HPC containerization can be realized on top of unmodified upstream engines by introducing explicit system integration, scalable image management, scheduler-native orchestration, and host resource injection layers. It achieves parity with domain-specific engines in communication, startup latency, and composable workflow support, while also preserving direct access to, and alignment with, the mainstream OCI/cloud-native software ecosystem. By asserting that production HPC needs only to specialize the integration layer, Sarus Suite substantially reduces long-term operational and software maintenance burden for sites supporting fast-evolving AI and scientific code bases. Its model further suggests a practical future for AI workflows in HPC—one where upstream alignment and site-specific performance are no longer in tension.
References
For additional details and cited results, see "Sarus Suite: Cloud-native Containers for HPC" (2604.17064).

