- The paper introduces a sequence-form variant of logit QRE to compute and select normal-form Nash equilibria in extensive-form games, circumventing exponential blowup of strategy spaces.
- It develops a differentiable path-following algorithm that reliably traces a unique path from a strictly positive interior point to a Nash equilibrium as the rationality parameter increases.
- Numerical experiments confirm robust convergence and consistent equilibrium selection across complex multi-player game scenarios, advancing scalable game-theoretic computation.
Introduction and Motivation
Significant obstacles remain in computing normal-form Nash equilibria and selecting among multiple equilibria in extensive-form games, primarily due to the exponential growth of the normal-form strategy space as the game tree increases. Classical approaches leverage the equilibrium selection property of the logit quantal response equilibrium (logit QRE), which smooths best responses using a rationality parameter and yields Nash equilibria as the rationality parameter diverges. However, applying logit QRE in the normal-form context is computationally infeasible for nontrivial sequential games.
This work addresses the tractability gap by formulating logit QRE directly in the sequence form—circumventing the exponential blowup of pure/mixed strategies and enabling efficient path-following algorithms over polynomial-sized (sequence-form) variable spaces. The framework robustly connects logit QRE's equilibrium selection to sequence-form representations, establishing the essential theoretical and algorithmic foundation for scalable equilibrium selection in general finite n-player extensive-form games with perfect recall.
The core contribution is a sequence-form analog of the logit QRE. Given a finite game Γ specified in extensive form, the normal-form QRE requires working with full-matrix mixed strategies. In the sequence form, player strategies are realization plans—linear-size objects that directly encode the probability of sequences of actions at information sets. The authors formulate an entropy-regularized, strictly convex optimization problem for each player, with entropy weight set by (1−t)/t or equivalently λ as the rationality parameter. The unique optimizer yields a realization plan that encodes a sequence-form logit QRE.
Crucially, for any t∈(0,1] (i.e., λ≥0), the realization plan γ∗ corresponds—via an explicit mapping—to a logit QRE mixed strategy in normal form, and the formulation ensures that the fixed point of the induced mapping coincides with the logit QRE solution in the normal form. The authors prove that as λ→∞, the sequence-form QRE converges to Nash equilibria in normal form, enabling natural equilibrium selection.
Differentiable Path-Following Algorithm
To exploit the QRE selection properties computationally, the authors develop a differentiable path-following scheme for the sequence-form logit QRE. Starting from an arbitrary strictly positive realization plan, a smooth path in strategy space is traced as the rationality parameter λ increases monotonically to infinity. Each iterate on the path is a unique QRE, and the terminal point is guaranteed to be a Nash equilibrium.
The algorithm circumvents logarithmic and division operations via variable substitutions and auxiliary function definitions, ensuring differentiability and smoothness. Nontrivial transformations—particularly an exponential mapping and root-finding reformulation—facilitate stable numerical integration along the homotopy path. Theoretical analysis (via the implicit function theorem and transversality arguments) confirms that almost every initial interior point yields a unique, well-defined path converging to a Nash equilibrium.
Empirical Validation
The paper validates the theoretical claims and algorithmic construction through numerical experiments on representative examples.
For complex multi-player games with many equilibria, the path-following procedure selects distinctive normal-form Nash equilibria, with the entire realization plan/mixed strategy trajectory shown as the rationality parameter increases. These experiments demonstrate:
- Robust convergence from arbitrary strictly positive starting points.
- Smooth transition of both realization plans and the corresponding mixed strategies.
- Consistent selection of Nash equilibria across diverse game topologies.
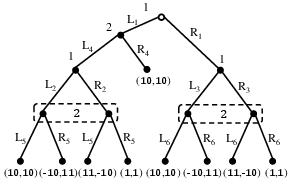
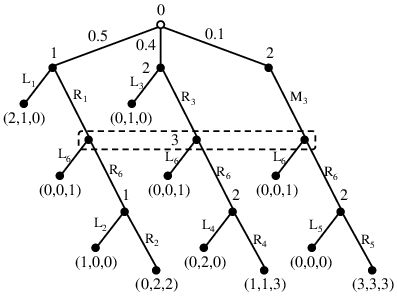
Figure 2: Illustration of an extensive-form game scenario used in one of the experimental validations, providing a nontrivial test case for sequence-form QRE computation.
Theoretical and Practical Implications
The presented sequence-form logit QRE formalism advances both the theory and practice of equilibrium computation and selection in extensive-form games. The theoretical contributions establish that bounded rationality models with rich equilibrium selection properties can be naturally and efficiently realized in the sequence-form domain. Practically, the differentiable path-following framework supports scalable equilibrium computation and is amenable to further extension toward equilibrium refinement concepts and integration into large-scale game-theoretic solvers.
Notably, the approach obviates the need for explicit normal-form construction and readily applies to games in economics, political science, and engineering where extensive-form representations are essential. The results enable routine computation of Nash selection paths and open perspectives for incorporating behavioral and perturbed-equilibrium solution concepts into algorithmic game theory.
Conclusion
This work provides a comprehensive characterization and computational method for selecting normal-form Nash equilibria in finite extensive-form games via a sequence-form variant of logit QRE (2604.16944). The differentiable path-following algorithm generates a solution trajectory from a strictly positive interior point to a Nash equilibrium, with each intermediate point a legal logit QRE in the sequence form. Theoretical and numerical results confirm robust convergence and effectiveness. Future directions include extending the framework to equilibrium refinements (e.g., proper, perfect, trembling-hand) and exploring applications in scalable game-theoretic learning and AI planning systems.

