- The paper introduces COIN with a multi-layer benchmark designed to evaluate interactive reasoning in complex, real-world robotic manipulation tasks.
- It details a low-cost, smartphone-based teleoperation system that enables high-quality multi-view demonstrations and precise trajectory replay.
- Empirical results highlight a stark performance gap between current VLA models and human operators, underscoring the need for innovative adaptive reasoning architectures.
Chain Of Interaction Benchmark (COIN): Systematic Evaluation of Interactive Reasoning in Embodied Robotic Manipulation
Motivation and Scope
Despite rapid advances in vision-language-action (VLA) models and foundation models for robotics, existing embodied benchmarks and manipulation environments predominantly target short-horizon, fully observable tasks or focus on static perception rather than dynamic, iterative reasoning. There is a severe deficit in benchmarks that systematically assay the ability of agents to perform interactive, causally-dependent reasoning through continual perception-action loops under partial observability and frequent environment changes—capabilities prerequisite for robust deployment in real-world scenarios. To fill this gap, "Chain Of Interaction Benchmark (COIN): When Reasoning meets Embodied Interaction" (2604.16886) provides a structured, multi-layered benchmark specifically designed to push and dissect VLA models' interactive reasoning and generalization ability in complex, realistic manipulation settings.
Benchmark Structure and Interactive Reasoning Taxonomy
COIN consists of three hierarchically organized components targeting granular manipulation skills, compositional mid-complexity behaviors, and full long-horizon interactive reasoning:
- COIN-Primitive: 20 atomic manipulation tasks distilled from broader real-world scenarios, providing 50 diverse expert demonstrations per primitive.
- COIN-Composition: 20 intermediate tasks composed by perturbing primitives (visual/instruction variations), probing skill composition and generalization.
- COIN-50: 50 high-complexity tasks requiring multi-stage, causally dependent interaction, iterative feedback loops, and sophisticated adaptation to partial observability and temporal dependencies.
The benchmark defines a principled taxonomy of reasoning skills needed for embodied interactive manipulation, covering object-centric reasoning (physical property inference, spatial relations, mechanism understanding), robot-centric reasoning (embodiment awareness, control optimization), and compositional reasoning (tool use, failure-driven adaptation, hierarchical planning, experience transfer). This organization enables systematic dissection of embodied agents’ performance on each axis.
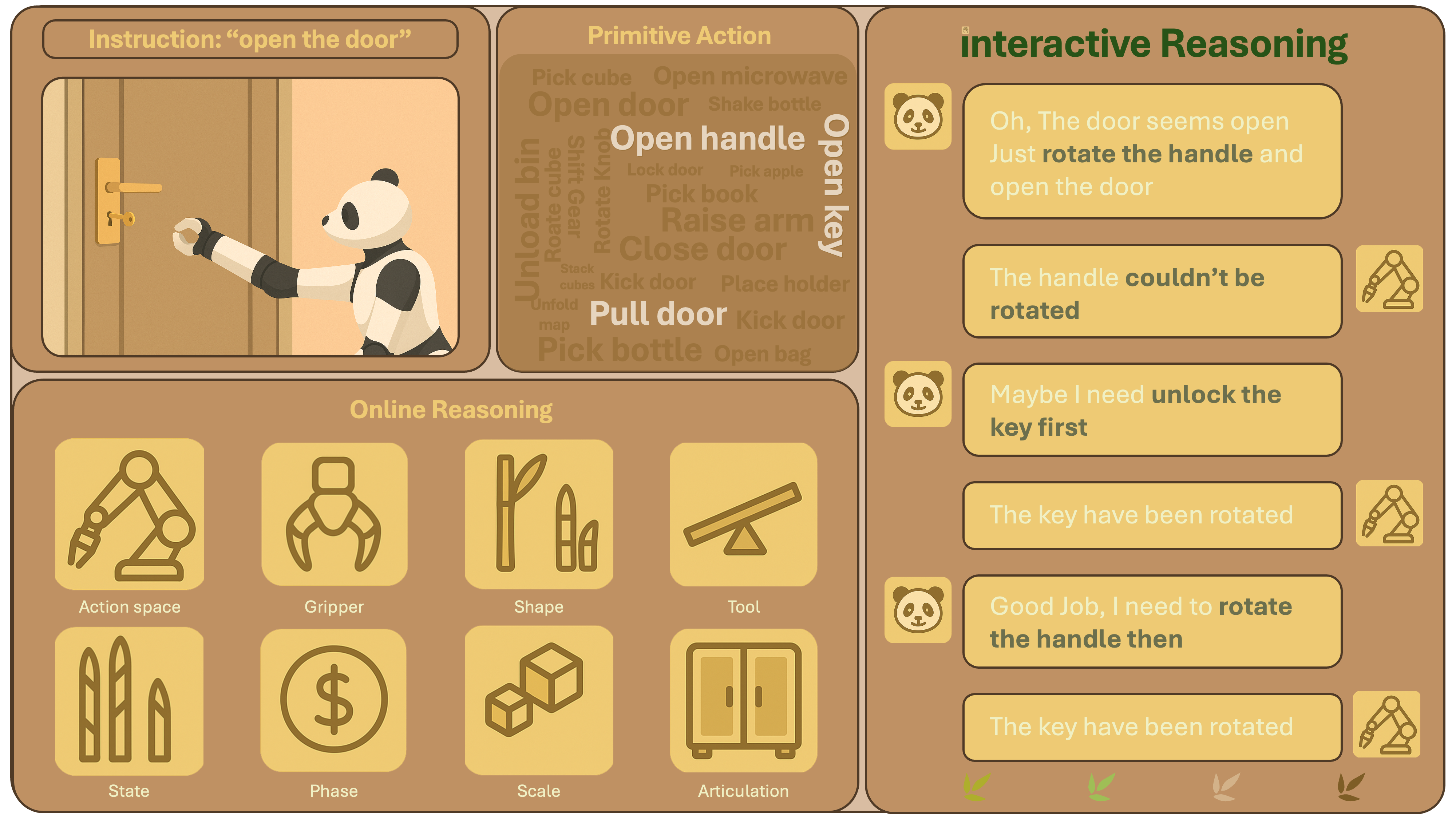
Figure 1: An overview of COIN emphasizing its coverage of rich interactive reasoning demands across primitive and composed manipulation actions.
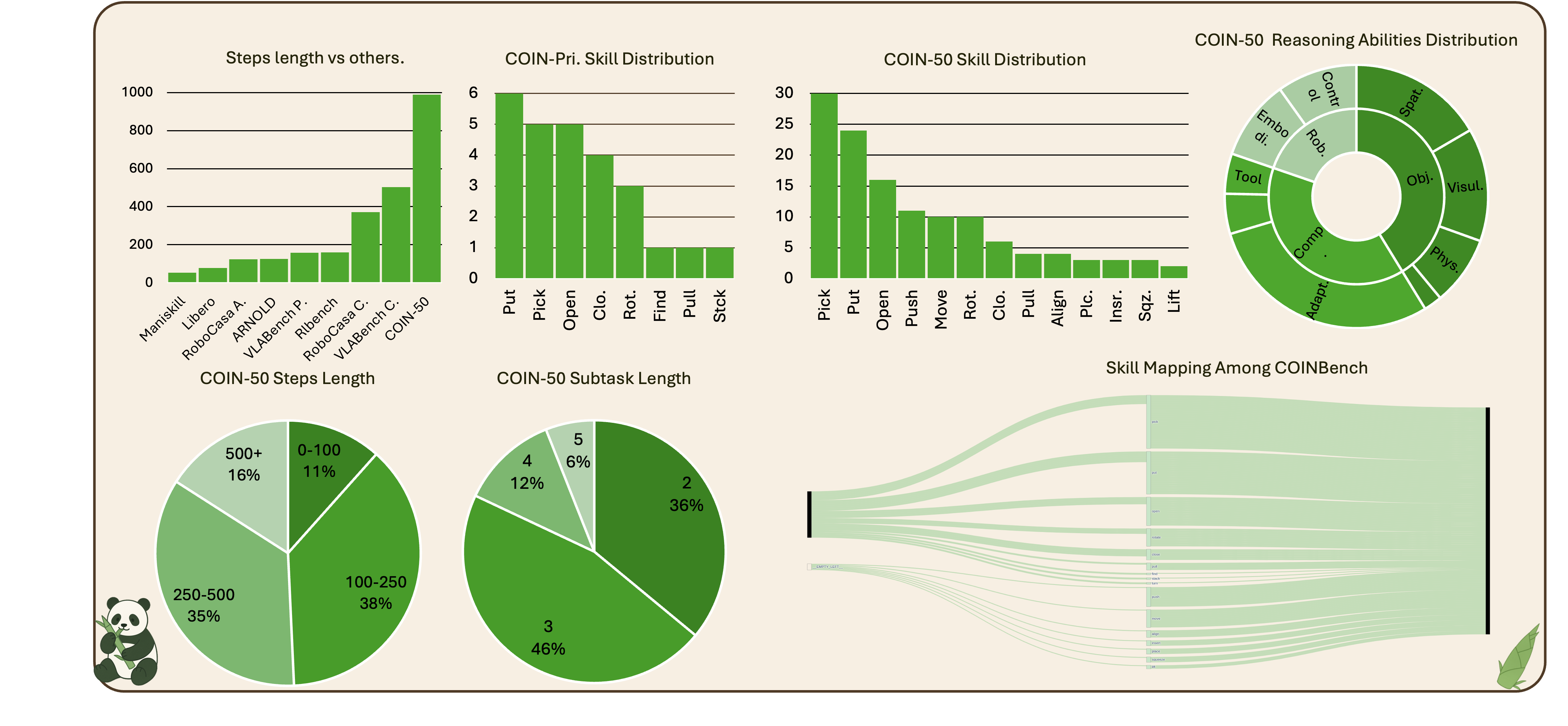
Figure 2: Task diversity in COIN, highlighting the decomposition from simple primitives to complex compositional and interactive reasoning scenarios, with ground-truth (GT) planning supervision.
Low-Cost Teleoperation Data Collection Pipeline
A significant technical contribution is a smartphone-based teleoperation platform (hardware cost <$20), which leverages commodity AR frameworks for real-time, 6-DoF robot control at 20Hz. This system enables democratized collection of high-quality, multi-view manipulation demonstrations at scale and with high replay fidelity (90% trajectory replay success), supporting efficient training and community adoption.
Task Complexity and Evaluation Protocol
COIN features average interaction episode lengths orders of magnitude longer than prior benchmarks (mean ≈990 steps for COIN-50), with compositional tasks demanding recurrent "interaction–reasoning–interaction" cycles as opposed to mere action-chaining. The dataset captures substantial solution diversity and strong temporal dependencies, presenting an explicit challenge for both memory retention and planning under partial observability.
A comprehensive evaluation suite is introduced:
- Success Rate (SR) and Class Success Rate (CSR) for aggregate and domain-specific competence,
- Visual QA Score (VS) probing on-the-fly perceptual reasoning,
- Trajectory Stability (TS) and Gripper Stability (GS) for low-level execution quality,
- Generalization Capability Score (GCS) for measuring robustness under task/instruction variations.
Model Families and System Architecture: H-VLA vs. CodeAsPolicy
COIN categorizes tested models into three families:
- H-VLA (Hierarchical Vision-Language-Action): Two-tiered system combining a high-level vision-LLM planner (VLM, e.g., GPT-4o or Gemini 2.0) with a low-level, closed-loop VLA executor (e.g., Gr00t N1 [nvidia_gr00t_2025], Pi0 [openpi], CogACT [li_cogact_2024]). The high-level planner decomposes the goal into sub-tasks, while the executor performs real-time control, both communicating via language.
- End-to-End VLA: Direct mapping from ego-centric multi-view observations to actions without explicit high-level planning, e.g., Pi0, Gr00t N1, CogACT.
- CodeAsPolicy: VLM-based planning with hand-crafted or programmatic low-level skills, executing an initial plan in an open-loop or with basic feedback (e.g., Voxposer [voxposer], Rekep).
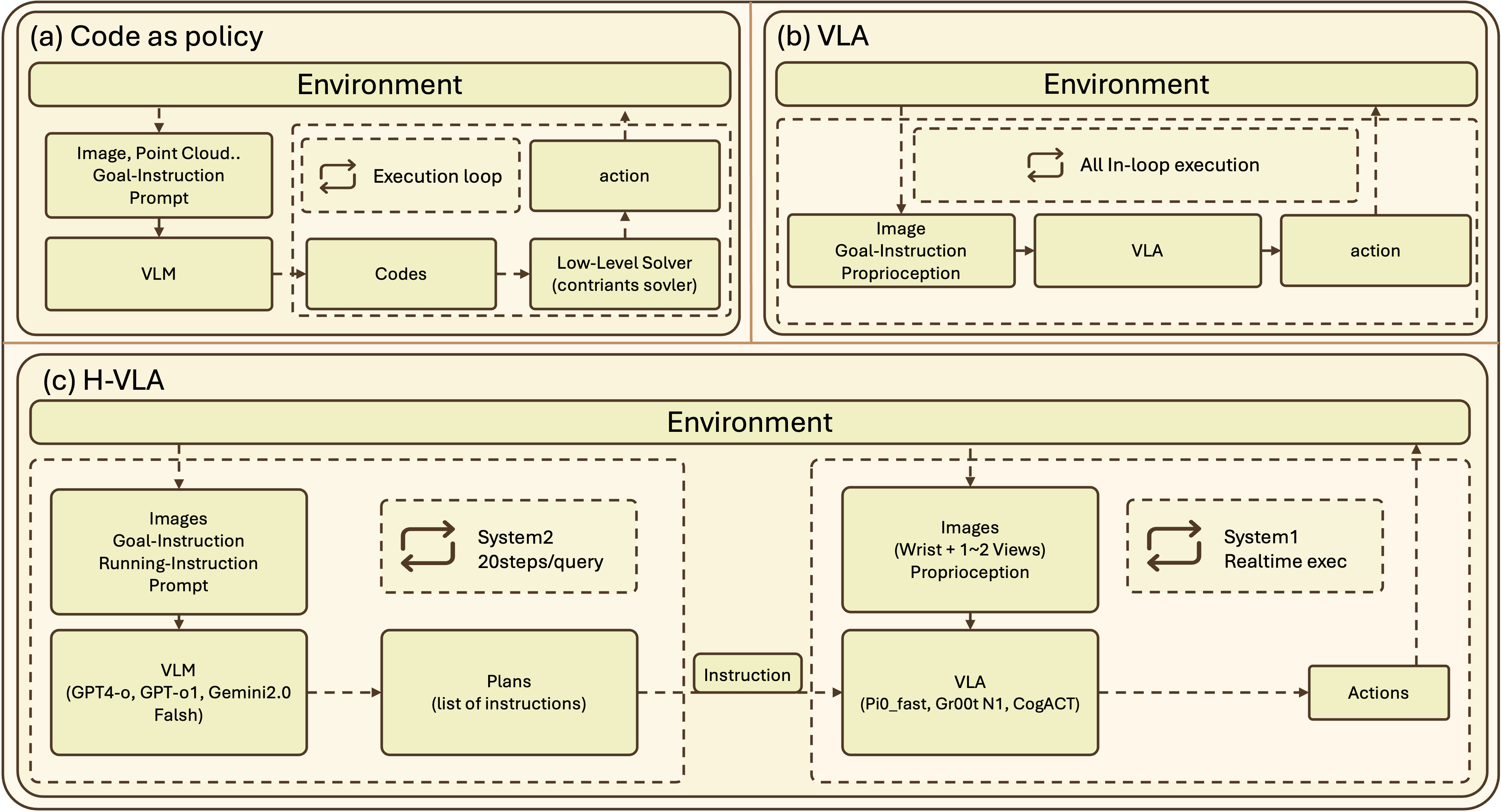
Figure 3: Architectural comparison: (a) CodeAsPolicy's modular VLM-based planning with separate low-level controllers, (b) end-to-end VLAs mapping perception to actuation, (c) H-VLA's hierarchical planner-executor structure linked via language.
Empirical Evaluation: Model Failures and Capability Gaps
Thorough evaluation on COIN-50 reveals a catastrophic gap between current models and human performance on truly interactive reasoning tasks:
- Human teleoperation (simulation): 40% SR; human (real robot): 100% SR.
- Best AI model (Rekep): 3.26% SR overall—over an order of magnitude below human baseline.
- H-VLA: 1.5–2.5% SR dependent on model pairing.
- CodeAsPolicy: 0.29–3.26% SR depending on planning/execution coupling.
Models persistently fail to accumulate and utilize history, plan adaptively, or recover from local execution failures, even with access to high-fidelity demonstrations and hierarchical planning (see Table 1 in paper supplement). This exposes a fundamental deficit in handling causal dependency chains, environmental ambiguity, and strategy replanning—all hallmarks of realistic robotic autonomy.
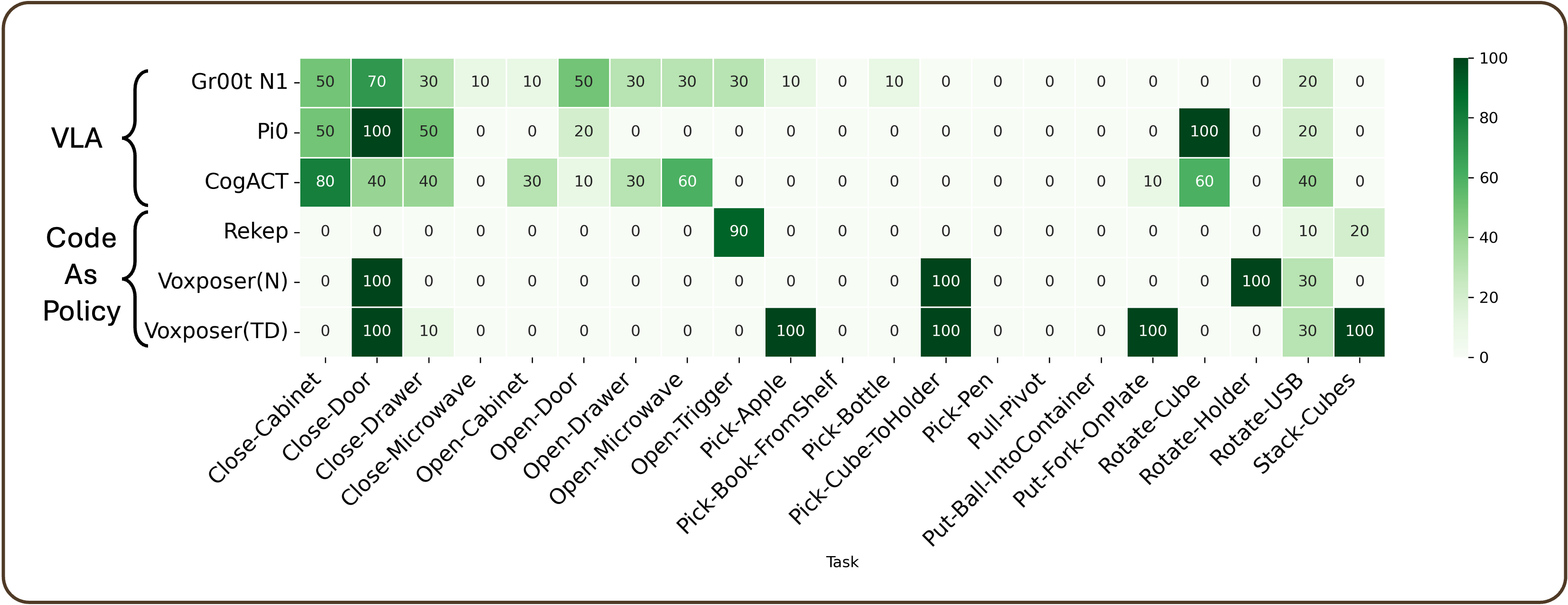
Figure 4: COIN-Primitive performance heatmap, demonstrating that pure VLA models achieve broader primitive task coverage than CodeAsPolicy, but both have limited robustness and generalization.
Expanded analysis on COIN-Primitive and COIN-Composition reveals concrete failure modes:
- Planning–Execution Disconnect: CodeAsPolicy approaches exhibit a rigid open-loop plan–execute paradigm and cannot adapt meaningfully to mid-trajectory feedback, particularly under partial observability.
- Generalization Collapse: VLA models, despite modest primitive performance (16-19% SR), fail almost entirely on minor compositional variations (0–6.5% SR).
- Weak Language–Skill Compositionality: Minor changes in instruction phrasing can dramatically degrade VLA performance, showing an inability to abstract and modularize learned behaviors (cf. [instruction_consistency]).
- Poor Trajectory/Gripper Smoothness: Only CogACT approaches human baseline for trajectory quality, but all VLAs exhibit discontinuities, erratic movements, and unreliable skill transitions.
Planning and Perceptual Reasoning Analysis
Direct assessment of VLM planners along expert demonstration trajectories confirms a consistent absolute gap (∼1.5 points) in reasoning ability in favor of GPT-4o over Gemini 2.0, across object-centric and compositional domains.
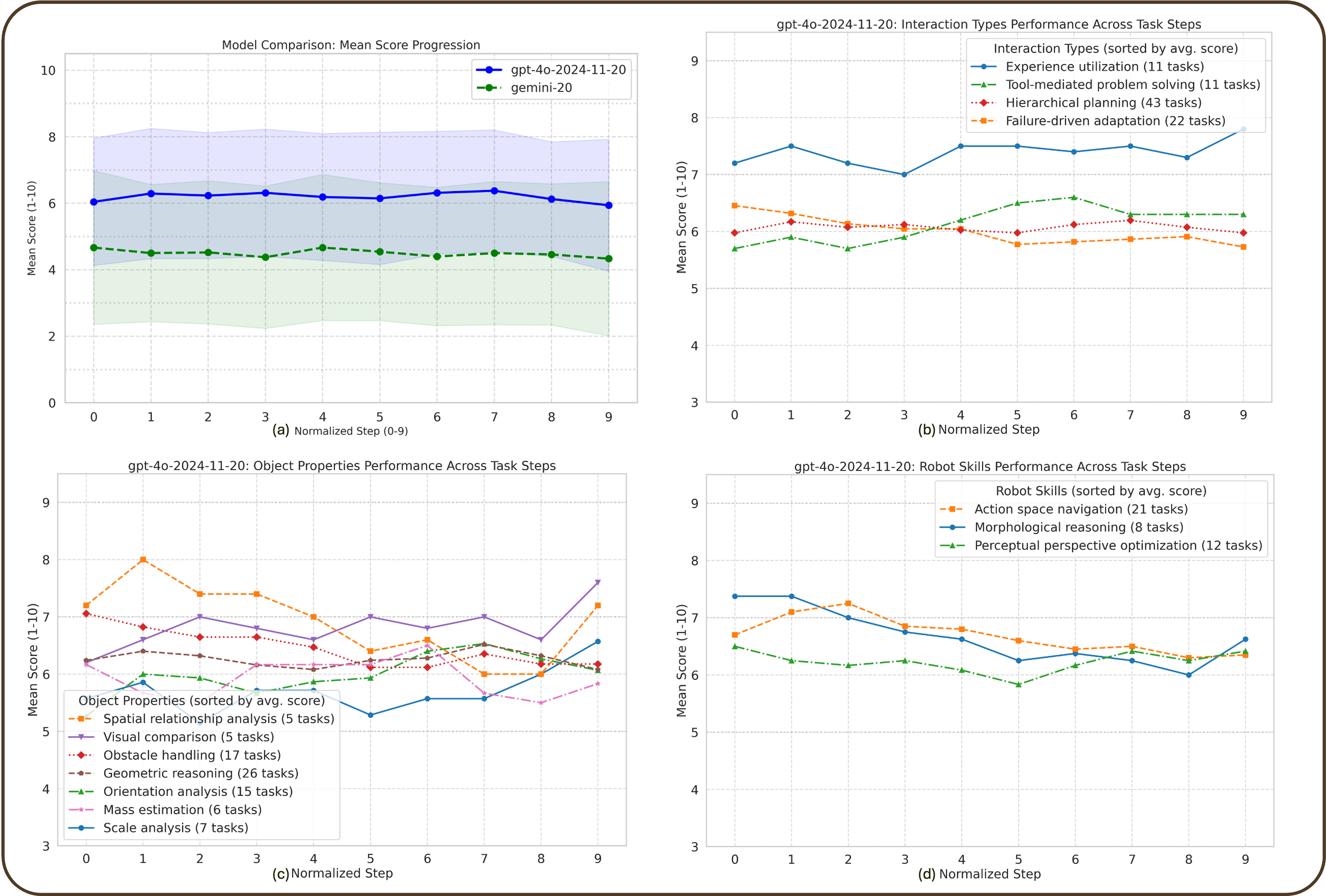
Figure 5: VLM reasoning comparison by time and domain—GPT-4o outperforms Gemini 2.0, but both degrade over long interaction horizons, unable to leverage accumulating context.
VQA probing suggests that perceptual reasoning accuracy peaks mid-task but deteriorates before task completion—further evidence that state maintenance and information integration over interaction cycles remains unsolved.
Implications and Future Directions
COIN's findings conclusively demonstrate the current inability of leading VLA and CodeAsPolicy approaches to achieve adaptive, robust, and generalizable interactive reasoning. Closing the performance gap to human operators on COIN-50 is not a matter of incremental scaling but demands architectural and algorithmic breakthroughs in several dimensions:
- Trajectory and Control Smoothness: Mechanisms for stabilization (e.g., CogACT's temporal ensemble) must be adopted and extended for all VLA models.
- History and Observation Integration: New memory-augmented, world-model-based architectures are needed to support efficient utilization of environmental feedback and belief updating during partial observability (cf. [zawalski_robotic_2024], [reflective planning (Feng et al., 23 Feb 2025)]).
- Flexible Reasoning and Closed-Loop Replanning: Interfaces between high-level planning and low-level execution must move beyond raw language; latent space bridges and hierarchical, feedback-driven planning should be explored ([instruction_consistency], [skreta_replan_2024], [yang_guiding_2024]).
- Robust Skill Compositionality and Generalization: Architectures must facilitate systematic recombination of primitives, abstraction over linguistic variability, and transfer across minor scene perturbations. Zero-shot and few-shot adaptation methods, possibly leveraging compositional priors or curriculum-based curriculum learning, should be validated on benchmarks with COIN's diversity and complexity.
- Accessible Data Collection: Democratized teleoperation pipelines such as COIN’s AR-based system should become standard for scalable community-driven demonstration gathering.
Conclusion
COIN establishes a new standard for embodied AI evaluation: experimental difficulty matched to real-world manipulation, multi-layered reasoning taxonomy, fine-grained trajectory and generalization metrics, and quantitative exposure of global failure modes currently limiting research progress. It sets a critical target for architectural innovation and robust generalization in VLA-based robotics, and forms an indispensable testbed for future model developments in perception–action–reasoning integration, memory-augmented policy design, and interactive planning under uncertainty.

Figure 6: COIN’s integrated environment setup, leveraging multi-view vision, proprioception, and low-cost AR-based teleoperation for robust data collection.