- The paper introduces a scalable RL post-training framework that uses deterministic solver feedback to improve autoformalization in operations research.
- It leverages synthetic data generation through structural asymmetry to create verified training pairs for LP, MILP, and nonlinear problems.
- Empirical results show AutoOR outperforms SFT and frontier models by achieving up to 97.2% accuracy and significant gains on complex non-linear optimization tasks.
AutoOR: RL-Based Post-Training of LLMs for Autoformalization in Operations Research
Autoformalizing optimization problems—transforming unstructured natural language descriptions into solver-readable formulations—is a foundational requirement in operations research (OR) applications spanning manufacturing, logistics, and industrial scheduling. Historically, this translation required considerable human expertise, imposing significant bottlenecks as industrial decision-making scales. Existing LLM-centric approaches leverage prompting, multi-agent orchestration, and supervised fine-tuning (SFT) with synthetic datasets, but these methods lack scalability, accuracy, and coverage for realistic or non-linear problem classes. They are further constrained by the scarcity of verified training data and inability to generalize beyond linear and mixed-integer programs.
AutoOR intervenes by turning the autoformalization pipeline into a scalable, verifiable RL domain. The approach synthesizes high-fidelity training data from standard forms and bootstraps online RL post-training using deterministic solver execution as reward feedback. This unlocks model generalization across LP, MILP, and previously intractable non-linear optimization problems, addressing both practical deployment and theoretical limitations.
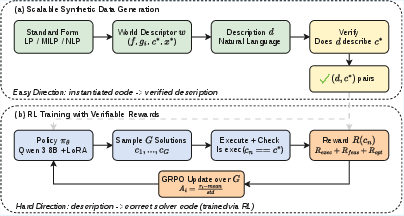
Figure 1: AutoOR overview illustrating synthetic problem generation and RL training loop with solver-execution rewards.
Synthetic Data Generation via Structural Asymmetry
AutoOR capitalizes on the structural asymmetry in optimization modeling. For any category where a standard mathematical template exists, fully-instantiated parameters directly yield correct solver code. These instantiations are then backtranslated to natural language descriptions—an operation that is easily verifiable component-wise using LLMs. The pipeline comprises four stages:
- Template Selection: Domain-appropriate standard forms for LP, MILP, or NLP.
- Instantiation: LLMs are used to populate templates with parameters, generating world descriptors (w), ground-truth code (c∗), and solutions (x∗).
- Backtranslation: LLMs convert w into domain-relevant natural language descriptions d (with control over complexity and incompleteness for multi-turn settings).
- Verification: High-throughput LLM-based checks validate description fidelity relative to w, yielding a scalable, verified synthetic dataset.
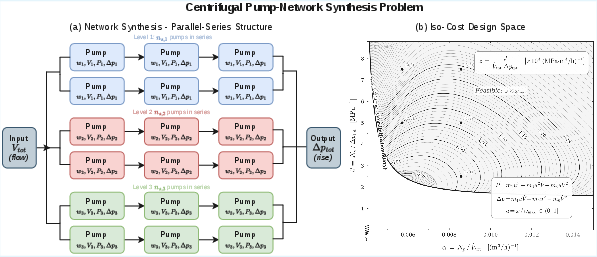
This strategy ensures nearly every accepted pair is correct-by-construction, mitigating the noise/ambiguities plaguing prior synthetic datasets. For non-linear domains with physical dynamics, the pipeline bootstraps from domain-specific exemplars (e.g., pump network synthesis), scaling via parameter variation while preserving the governing equations.
Reinforcement Learning Training with Verifiable Rewards
AutoOR employs Group Relative Policy Optimization (GRPO) for post-training of Qwen3-8B. The RL loop is grounded in verifiable rewards derived from deterministic solver feedback:
- Reward Function: Composite reward for code execution, constraint feasibility, and objective optimality (with increasing weights), computed programmatically and only for fully correct solutions.
- Advantage Estimation: Group normalization across sampled code rollouts, which robustly handles the high variance of code generation.
- Policy Update: Clipped surrogate objective with per-token importance sampling.
This RLVR setup is particularly suited to the domain, as solver verification eliminates reward model noise and enables robust learning from execution results—a paradigm validated in RL-based formal math and code generation research. Curriculum RL with privileged information (e.g., solver syntax) is introduced for hard non-linear classes, overcoming the cold-start barrier wherein frontier models produce no solvable rollouts.
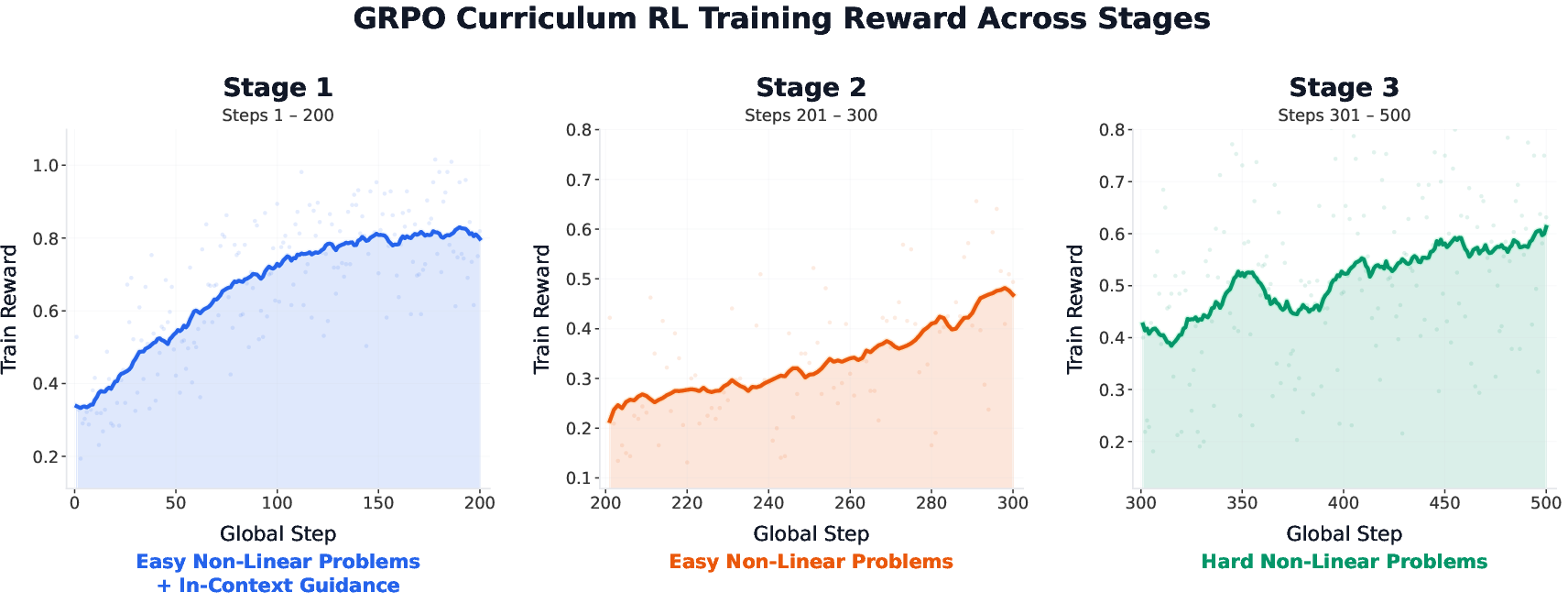
Figure 2: Curriculum RL stages for non-linear optimization, enabling model bootstrapping and tractable RL learning signal.
Empirical Results and Benchmark Comparison
AutoOR-8B is evaluated across six established and three new benchmarks, compared against baseline and frontier models (Gemini 3 Pro, Gemini 2.5 Pro, Qwen3-8B), as well as published learning-based methods (ORLM, Step-Opt, OptMATH, OR-R1). Main findings:
Recognizing the practical necessity for agentic behavior in optimization modeling, AutoOR incorporates a multi-turn RL setup where models are trained to actively query for missing information. This is instantiated as a simulated human-in-the-loop environment, with two-turn GRPO optimizing both clarification query precision and final code correctness.
- Experimental Results: Multi-turn RL yields a dramatic accuracy improvement (66.75% vs 18.5% uninformed baseline), closing most of the gap to the full-information regime.
- Scalability: The framework is readily extensible to higher-turn interactions and tool integration, setting the stage for broader agent-based optimization assistance.
Practical and Theoretical Implications
AutoOR advances both the practical deployment and theoretical feasibility of scalable autoformalization:
- Practical Accessibility: Enables competitive performance with small, open-source LLMs, reducing reliance on expensive proprietary frontier models and supporting privacy-preserving model training on domain-specific distributions.
- Generalization Beyond SFT: RL post-training incentivizes solution exploration and verifiable reasoning, overcoming the memorization pitfalls of pure SFT. Particularly in code and optimization contexts, this translates to improved out-of-distribution performance and scalability.
- Agentic Industrial Decision-Making: The multi-turn pipeline lays groundwork for LLMs as active participants in real-world modeling workflows, with iterative information gathering, tool use, and model refinement.
Limitations and Future Directions
AutoOR’s non-linear success is demonstrated on pump synthesis but requires extension to broader NLP domains (e.g., quadratic programming, conic optimization, multi-objective settings). Reward coarseness (execution, feasibility, optimality checks) does not yet capture formulation efficiency or solver tractability differences. Multi-turn setups are currently simulated; practical deployment will require richer tool integrations and iterative agent post-training.
Future directions include expanding coverage to more diverse non-linear classes, training for formulation efficiency and solver-agnostic outputs, and scaling agentic behaviors with tool calls and real-world multi-turn interactions. These developments will further advance industrial decision automation and optimization accessibility.
Conclusion
AutoOR transforms the autoformalization of OR problems into a verifiable RL domain by leveraging scalable synthetic data generation and programmatic reward feedback. RL post-training on small open-source LLMs matches or outperforms frontier models on a wide array of benchmarks, achieves tractability on previously unsolved non-linear classes via curriculum, and demonstrates agentic capabilities through multi-turn formalization. This establishes a practical, generalizable paradigm for expert-level optimization modeling and supports the advancement of LLM-powered industrial decision-making.