- The paper presents a diagnostic framework that separates context-independent and context-dependent regimes to identify failure modes in long-horizon robotic manipulation.
- It employs stage-wise scoring and over 1,000 real-world episodes to detail execution errors, time-critical challenges, and memory-related ambiguities.
- Results reveal that naive memory integration is insufficient, highlighting the need for structured context reasoning to improve long-horizon performance.
LongBench: Mechanism-Aware Evaluation of Robotic Manipulation on Real-World Long-Horizon Tasks
The intrinsic challenge of long-horizon robotic manipulation in the real world lies in the accumulation of errors, temporal dependencies, and context-sensitive ambiguities that disrupt sustained physical interaction. Existing benchmarks largely rely on simulation or aggregate success rates, offering little explanatory power regarding why failures occur. "LongBench: Evaluating Robotic Manipulation Policies on Real-World Long-Horizon Tasks" (2604.16788) addresses this diagnostic deficit by introducing a framework explicitly designed to disentangle and analyze diverse mechanisms of temporal difficulty in real-world long-horizon manipulation.
LongBench operationalizes the distinction between Context-Independent and Context-Dependent regimes. The former focuses on long-horizon tasks with full observability, emphasizing execution robustness and dynamic interaction; the latter captures tasks where ambiguity can only be resolved through retention and application of episodic context. The result is a benchmark that enables mechanism-aware analysis and diagnosis of where and how long-horizon manipulation policies break down.
Benchmark Structure and Task Taxonomy
LongBench comprises over 1,000 real-world episodes across ten tasks, structurally partitioned as follows.

Figure 1: Overview of the 10 LongBench tasks, divided into Context-Independent and Context-Dependent regimes. Context-Independent tasks test sustained execution under full observability; Context-Dependent tasks require historical context for disambiguation.
Context-Independent Long-Horizon Tasks are characterized by four orthogonal structural capabilities:
- Phase Dependence (PD): Strict staging with precondition logic; early mistakes cascade.
- Iterative Progress (IP): Repetitive goal achievement sequences necessitating precise progress tracking.
- Error Accumulation (EA): Long rollouts magnify micro-errors leading to late-stage failure.
- Temporal Windows (TW): Time-critical action opportunities; delayed actions become irrevocable.
Context-Dependent Long-Horizon Tasks are organized by four ambiguity patterns:
- Completion Ambiguity (CP): Observations ambiguous with respect to termination status.
- Count Ambiguity (CT): Required action count is not observable; history tracking is needed.
- Subtask-Branch Ambiguity (SB): Branch selection requires prior context due to visually aliased states.
- Cross-Episode Ambiguity (CE): Latent context from earlier or prior episodes is essential for disambiguation.
This decomposition allows precise attribution of failure to the relevant underlying challenge.
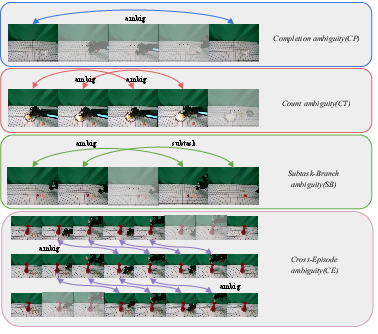
Figure 3: Visualization of representative ambiguity mechanisms in Context-Dependent tasks, highlighting completion, count, subtask-branch, and cross-episode ambiguity.
Experimental Protocol
Evaluation is standardized via a tabletop apparatus with dual RGB streams and precise robot state logging. Policies are separated into single-frame architectures (e.g., π0, OpenVLA-OFT, SmolVLA, Diffusion Policy) and history-conditioned models (MemoryVLA, CronusVLA), providing coverage across the spectrum of temporal modeling approaches. All policies execute open-loop action chunks under strict protocol controls, ensuring comparability.
A stage-wise scoring metric decomposes tasks into atomic sub-steps, yielding granular progress signals. Mechanism-level and regime-level aggregations precisely isolate capabilities and ambiguity phenomena.
Evaluation: Diagnosis of Failure Mechanisms
Results on Context-Independent Tasks
Despite full observability, task performance is not governed by a single axis; capabilities display heterogenous difficulty. Notably, π0 significantly surpasses other methods in the execution-centric regime, but all models except π0 collapse on Temporal Windows tasks due to inability to robustly handle time-critical interventions. Error accumulation remains a strong weakness, even among top-performing models.
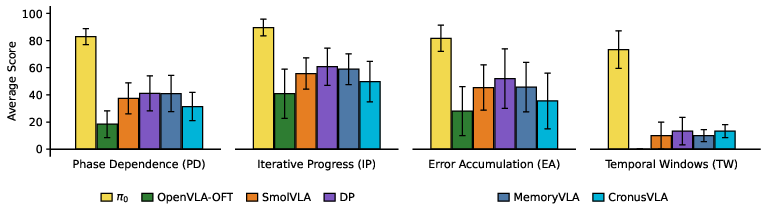
Figure 4: Performance by structural capability on Context-Independent tasks; only π0 is competitive on all axes, especially for Temporal Windows. Error bars indicate SEM.
Results on Context-Dependent Tasks
Task-induced ambiguity in the Context-Dependent regime produces marked variance across policies and ambiguity type. Memory-based approaches (MemoryVLA, CronusVLA) only partially succeed in Count Ambiguity (CT), with gains not propagating to more structurally complex ambiguities such as SB and CE. In SB tasks, all models—regardless of memory—exhibit near-zero scores, highlighting a failure to condition on the full relevant context for latent branch identification.
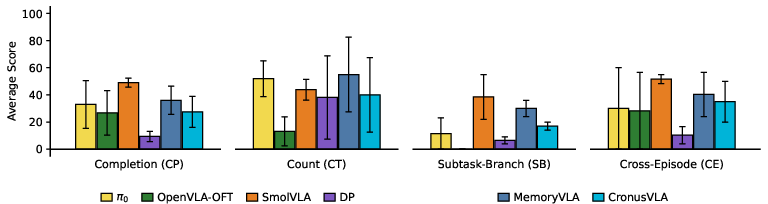
Figure 5: Ambiguity-pattern-aligned performance for Context-Dependent tasks. Gains from memory are inconsistent and highly pattern-dependent.
Regime-Level and Cross-Model Synthesis
Strong performance in execution regimes (Context-Independent) does not transfer to ambiguity-laden regimes (Context-Dependent), nor does access to explicit memory yield robust gains across all task types. SmolVLA—a model without explicit temporal structure—outperforms several history-conditioned models on average in some ambiguous tasks, indicating that naive memory integration is insufficient.
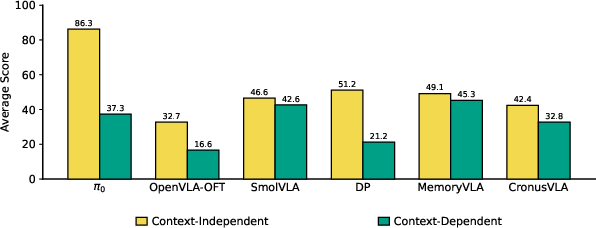
Figure 2: Regime-level scores. Gap between Context-Independent and Context-Dependent regimes is consistent; memory reduces gap but does not improve peak performance.
Diagnostic Visualizations
Inspection of representative failures (Figure 6) and completed-phase statistics (Figure 7) elucidates the qualitative nature of failure: in Context-Independent tasks, execution errors compound or timing is consistently mismanaged; in Context-Dependent settings, policies typically misinterpret key ambiguities early, often by prematurely committing to an incorrect hidden state or losing track of required context.

Figure 7: Representative failures by task; left: execution breakdowns in Context-Independent tasks, right: context inference failures in Context-Dependent tasks.
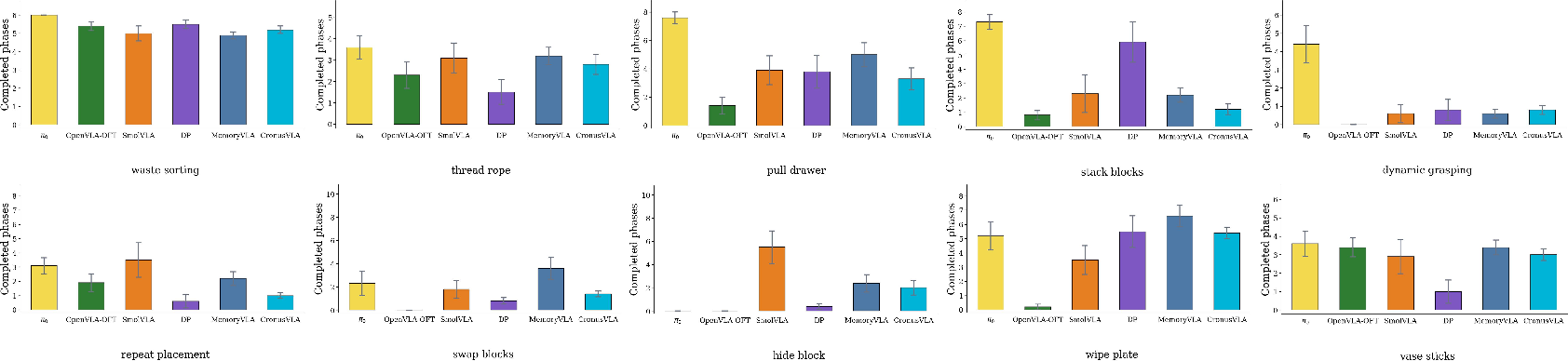
Figure 6: Mean completed-phase counts per policy and task. Multi-frame policies do not consistently fail later than single-frame policies, underscoring that context retention is non-trivial.
Theoretical and Practical Implications
LongBench empirically and structurally demonstrates that:
- Execution robustness and context-dependent reasoning constitute orthogonal axes of long-horizon difficulty. Progress on one does not guarantee progress on the other.
- Memory as implemented in current architectures is neither necessary nor sufficient for consistent gains in resolving contextual ambiguity.
- Policy design must attend not only to horizon extension and memory augmentation, but also to mechanisms for cue selection, context binding, and dynamic re-grounding on ambiguous observations.
For method development, this implies that future advances in long-horizon manipulation must integrate context-sensitive reasoning modules that can both store and appropriately retrieve/correct historical information. Policies must prioritize not just access to history, but mechanisms for structured context interpretation and error recovery. Benchmarks aggregating over task classes lacking in such diverse diagnostics will necessarily obscure real-world deficiencies.
Outlook and Future Directions
LongBench introduces a new standard for mechanism-aware benchmarking in long-horizon real-world manipulation, enabling fine-grained evaluation and diagnosis for both execution and context challenges. This is a precondition for driving the development of fundamentally more robust and contextually aware robot control architectures—be they via enhanced cognitive memory, latent state inference, or other innovative mechanism design.
Critical open problems for the field include: designing historiographic modules capable of handling multiscale context dependencies, developing more sophisticated failure-recovery and ambiguity-resolution operators, and expanding diagnostic benchmarks to capture yet-unstudied regimes of real-world difficulty such as dynamic non-stationarity and multi-agent interaction.
Conclusion
LongBench establishes itself as a diagnostic, real-world, and mechanism-aware benchmark for long-horizon robotic manipulation (2604.16788). It demonstrates that neither execution competency under full observability nor access to historical memory alone suffice for robust long-horizon performance. By highlighting distinct and non-overlapping failure modes through a task-regime decomposition, it provides both practitioners and theoreticians a framework for evaluating and driving the next-generation advances in autonomous manipulation systems.

