- The paper introduces the Deep Heterogeneous Ranking (DHR) model, which separates intrinsic utility from context-driven nonlinear effects using deep neural networks.
- It establishes rigorous theoretical guarantees with minimax non-asymptotic error bounds for both utility and covariate effect estimation.
- Extensive simulation studies and evaluations on ATP tennis data demonstrate DHR's superior forecasting performance over traditional ranking models.
Deep Ranking with Heterogeneous Effects: An Expert Overview
Introduction and Motivation
Classical ranking models, notably the Plackett–Luce (PL) and Bradley–Terry (BT) frameworks, abstract the task of ordering items through object-specific latent utility parameters. However, these models fail to account for contextual covariate effects, leading to confounded utility estimates when data is generated under variable or dynamic conditions. The presented work develops a semiparametric extension of the PL model—the Deep Heterogeneous Ranking (DHR) model—that decomposes an object's log-score into an intrinsic utility and a nonlinear covariate effect, approximated via deep neural networks (DNNs).
This additive framework generalizes approaches such as PlusDC, where the covariate effect is linearly parameterized, and provides the flexibility to capture nonlinear interactions and intransitive structures in observed rankings. The paper demonstrates theoretical advances in identifiability, estimation, and optimality, accompanied by extensive empirical validation.
Semiparametric Ranking Model
The central model posits that, for any comparison (hyperedge) e involving a subset of objects, the log-score of object j is
se,j(u,f)=uj+f(Xe,j),
where uj is the object-specific utility and f(⋅) is an arbitrary function over context features Xe,j. The ranking distribution extends the PL model, with selection probabilities parameterized via scores se,j(u,f).
Key technical considerations include:
- Identifiability: The softmax likelihood is invariant to joint shifts in utilities and covariate effects, requiring centering constraints for uniqueness.
- Model Generality: This formulation strictly contains standard PL, BT, and linear-covariate models as special cases, permitting arbitrary (Hölder-smooth) nonlinearities.
- Contextual Intransitivity: The model can encode context-driven cyclic preferences that are unrepresentable in classical transitive stochastic models.
Estimation via Deep Neural Networks
Given the intractability of classical nonparametric estimation in high dimensions, the DHR framework employs a DNN to approximate f∗. The maximum likelihood estimator (MLE) jointly optimizes u and the DNN weights ϕ with a projected SGD algorithm, enforcing utility identifiability by constraining j0.
The existence of the MLE is proven to be equivalent to a strong connectivity (irreducibility) condition on the comparison hypergraph and outcomes, generalizing the requirements known for classical BT/PL models.
Theoretical guarantees are established under realistic regularity and random graph assumptions (nonuniform random hypergraph model, NURHM), ensuring that the utility estimates remain uniformly bounded, which is necessary for non-asymptotic analysis.
Non-Asymptotic Error Bounds and Statistical Optimality
The main theoretical results derive sharp, non-asymptotic bounds for estimation error of both parameters:
- For the utility vector, the error is measured in the graph-Laplacian seminorm j1 induced by the comparison topology.
- For the DNN-approximated covariate effect, the error is measured in the j2 norm over the covariate domain.
Key result: Given j3 observations, j4 objects, covariate dimension j5, and j6 of j7-Hölder smoothness, the minimax estimation rates are
j8
j9
Both rates are minimax optimal up to logarithmic factors, with parametric and nonparametric terms dominating in different sample regimes (Figure 1).
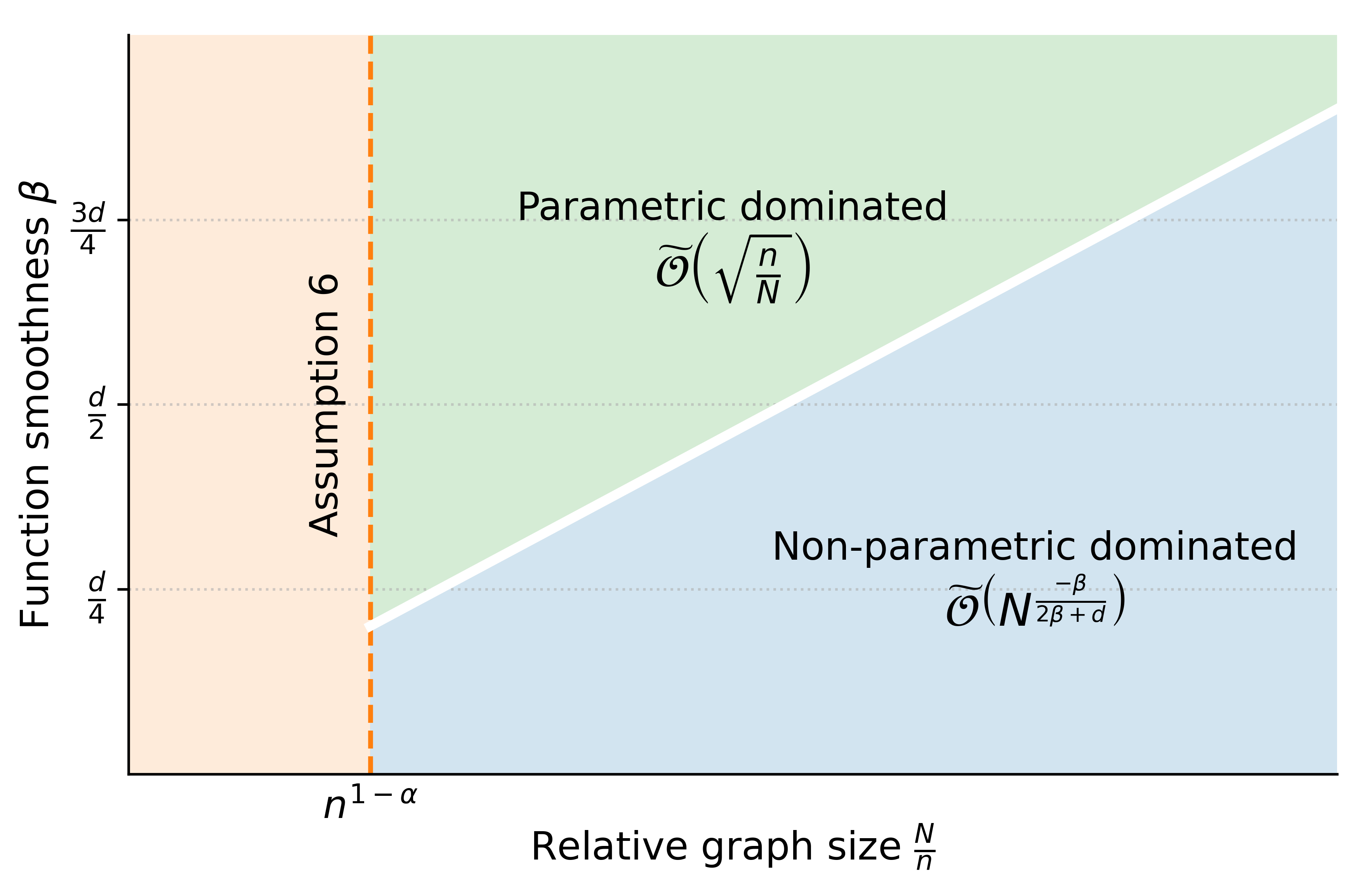
Figure 1: Regimes of error dominance in estimation: the relative scale of parametric and nonparametric components is determined by the ratio se,j(u,f)=uj+f(Xe,j),0 and the true function's smoothness se,j(u,f)=uj+f(Xe,j),1.
The architecture design of DNNs (depth, width, parameter bounds) for achieving these rates is explicitly characterized as a function of se,j(u,f)=uj+f(Xe,j),2, se,j(u,f)=uj+f(Xe,j),3, and se,j(u,f)=uj+f(Xe,j),4.
Empirical Evaluation
Simulation Studies
On synthetic data generated by the NURHM, DHR demonstrates convergence rates for utility and covariate effect estimation consistent with theoretical predictions. Estimation error decreases with increased graph density and function smoothness. For low se,j(u,f)=uj+f(Xe,j),5 (denser comparison graphs), convergence is accelerated, and marginal improvement saturates for highly smooth functions, reflecting transition of the rate-determining term.
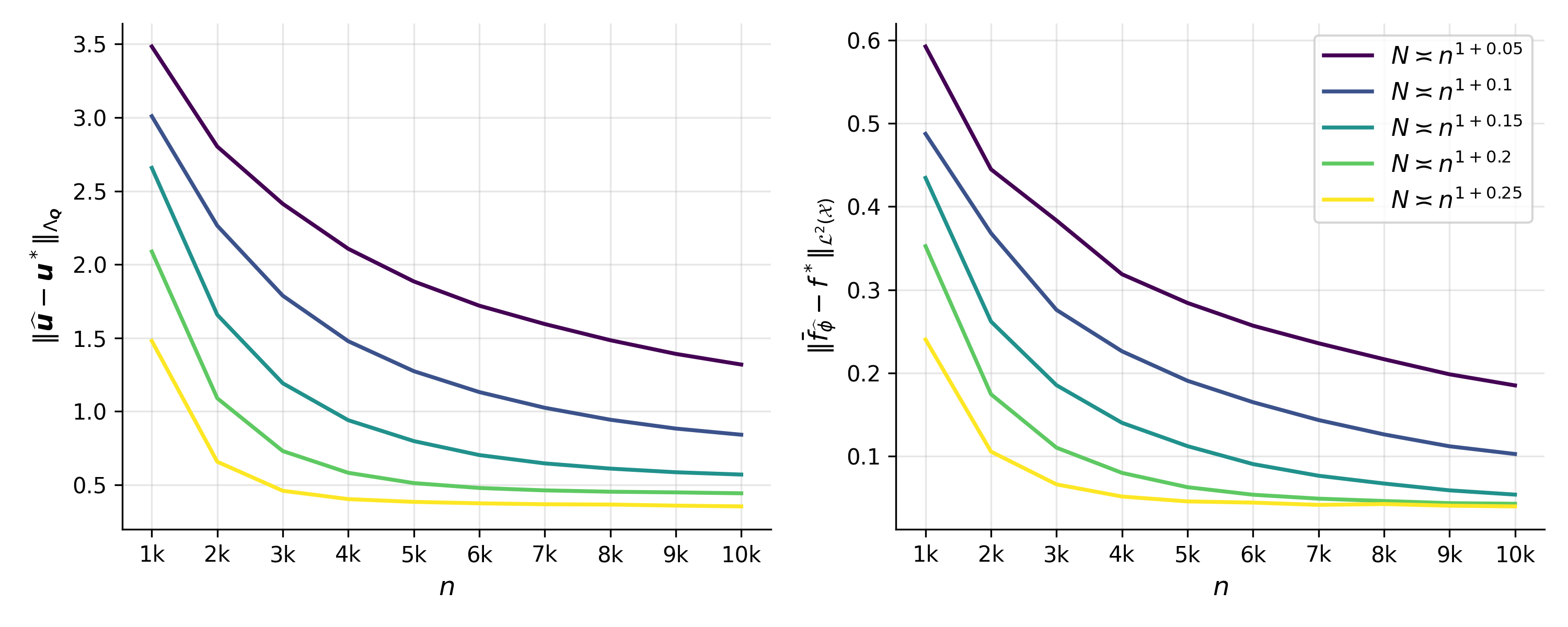
Figure 2: Trace plot of se,j(u,f)=uj+f(Xe,j),6 and se,j(u,f)=uj+f(Xe,j),7 as se,j(u,f)=uj+f(Xe,j),8 grows in different graph density regimes.
Figure 3: Estimated utility se,j(u,f)=uj+f(Xe,j),9 vs. ground truth (left), and surface plots of estimated vs. true uj0 (middle and right) for synthetic data.
ATP Tennis Dataset
The practical utility is evidenced on a large-scale professional tennis match corpus. The DHR model with full (nonlinear) covariate effects achieves superior out-of-sample accuracy (64.6%), log-likelihood, and Brier score compared to BT, PlusDC (linear), and ablated DNN-only baselines. The improvement over the ablated model quantifies the impact of explicitly modeling individual utility heterogeneity.
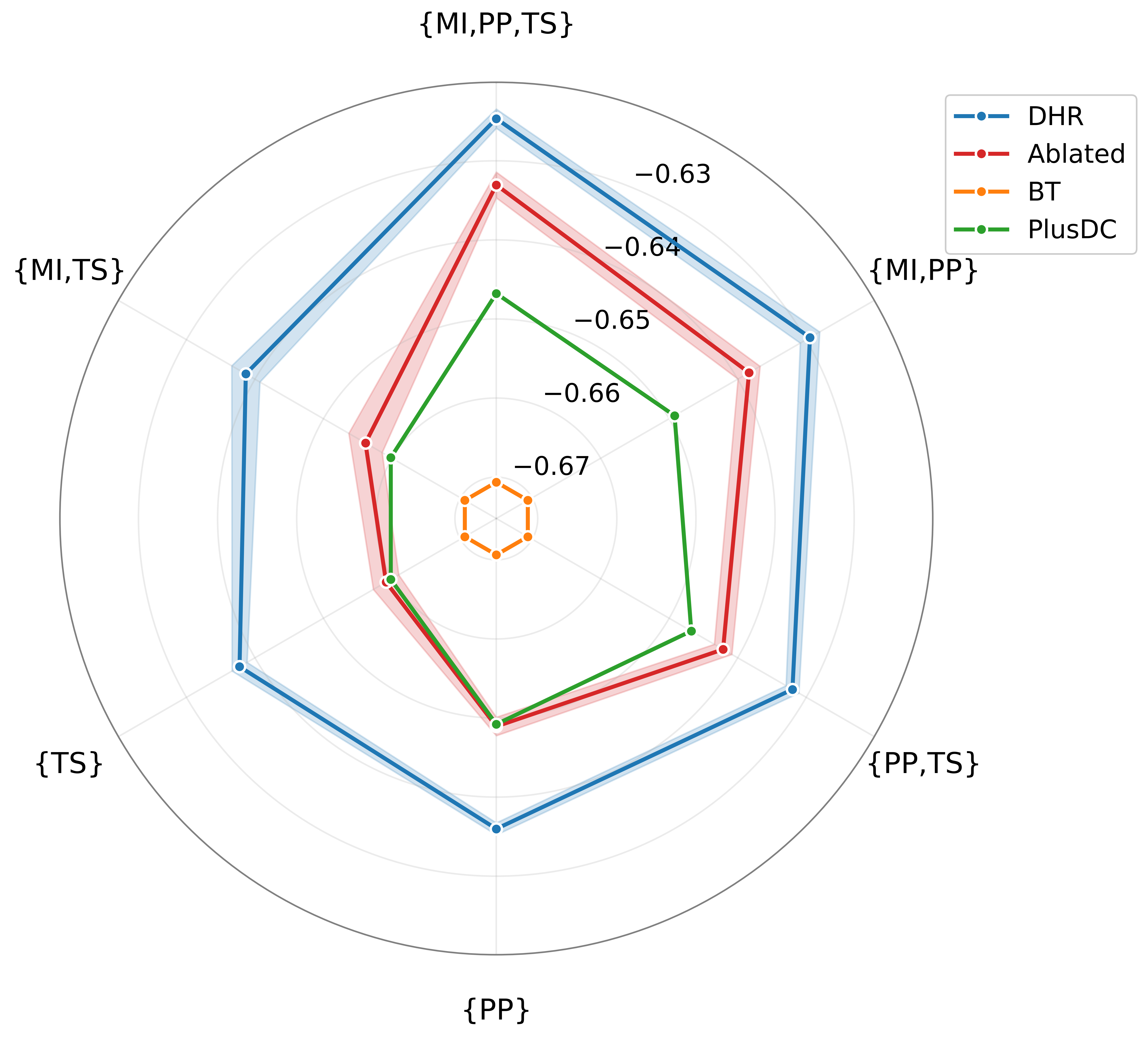
Figure 4: Out-of-sample forecasting performance (accuracy, log-likelihood, Brier score) for DHR and baselines on the ATP dataset; DHR consistently outperforms all alternatives.
Temporal analysis of player estimates via DHR reveals evolution consistent with expert knowledge and observed real-world dynamics: the decline of the "Big Three," and emergence of a new cohort occupying top estimated utility trajectories.
Theoretical and Practical Implications
This work advances ranking methodology in several foundational and practical dimensions:
- Provides a flexible and identifiable semiparametric model for complex, covariate-driven ranking data.
- Establishes joint optimality of utility and nonlinear covariate estimation in high dimensions, resolving the confounding issue inherent in classical models.
- Lays groundwork for adapting ranking models to RLHF and other ML applications where context and individual heterogeneity play critical roles.
Further research directions include deriving uj1-norm error bounds for the utility vector (potentially requiring novel DNN theory), establishing asymptotic normality and confidence intervals for inference, and extending to richer, multi-valued outcome types. From a methodological perspective, the framework can be generalized using alternative nonparametric architectures (e.g., neural additive models, transformers) or for more structured, complex comparison data.
Conclusion
The Deep Heterogeneous Ranking framework resolves key limitations of classical ranking models by separating intrinsic utility from nonlinear covariate effects, equipped with rigorous minimax-optimal estimation theory and state-of-the-art empirical performance. This work marks a substantive advancement in the principled analysis and deployment of ranking models in high-dimensional, context-rich environments.

