- The paper presents a systematic taxonomy classifying intrinsic interpretability designs for LLMs into five principle-based families.
- It details methodologies such as concept alignment, explicit modularization, and latent sparsity induction to embed transparency directly into model architectures.
- The study highlights challenges like the trade-off between expressivity and interpretability, and suggests future research directions for scalable, transparent LLMs.
Intrinsic Interpretability in LLMs: Design Principles and Architectural Taxonomy
Introduction
The survey "Towards Intrinsic Interpretability of LLMs: A Survey of Design Principles and Architectures" (2604.16042) systematically reviews the field of interpretability for LLMs, emphasizing approaches that build transparency into the models' computational graph, as opposed to traditional post-hoc explanation strategies. The paper provides a conceptual framework distinguishing post-hoc and intrinsic paradigms, develops a taxonomy over intrinsic interpretability designs, and summarizes architectural developments according to five organizing principles: functional transparency, concept alignment, representational decomposability, explicit modularization, and latent sparsity induction. The survey further discusses unresolved challenges and potential research trajectories for scalable, interpretable LLMs.
Interpretability Paradigms: Post-hoc vs. Intrinsic
The dichotomy between post-hoc and intrinsic interpretability is established operationally by the point of intervention: post-hoc techniques explain fixed, trained models using external tools, while intrinsic approaches embed interpretability as a consequence of the model’s architecture and training dynamics. The survey notes that post-hoc methods, such as LIME and SHAP, commonly operate at the behavioral or representational level, yielding explanations that often lack causal faithfulness and global clarity. Intrinsic interpretability, conversely, mandates that interpretable units—modules, concepts, or sparse pathways—are causally pivotal to model predictions.
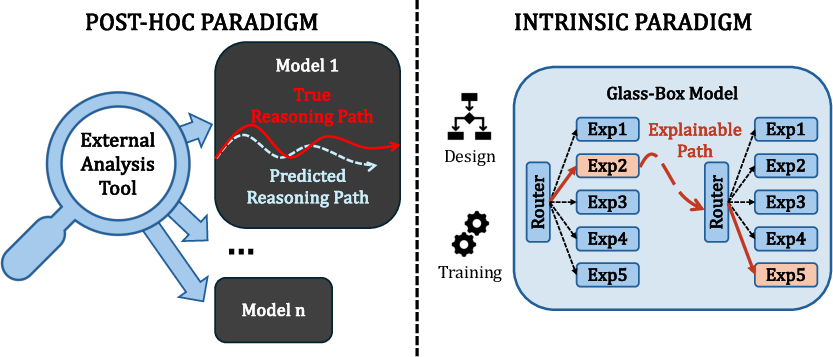
Figure 1: Comparison of post-hoc analysis and intrinsic design in LLM interpretability, highlighting fundamental architectural and methodological distinctions.
Taxonomy of Intrinsic Interpretability: Five Architectural Families
The heart of the survey is a taxonomy dividing intrinsic approaches into five distinct but sometimes overlapping design principles.
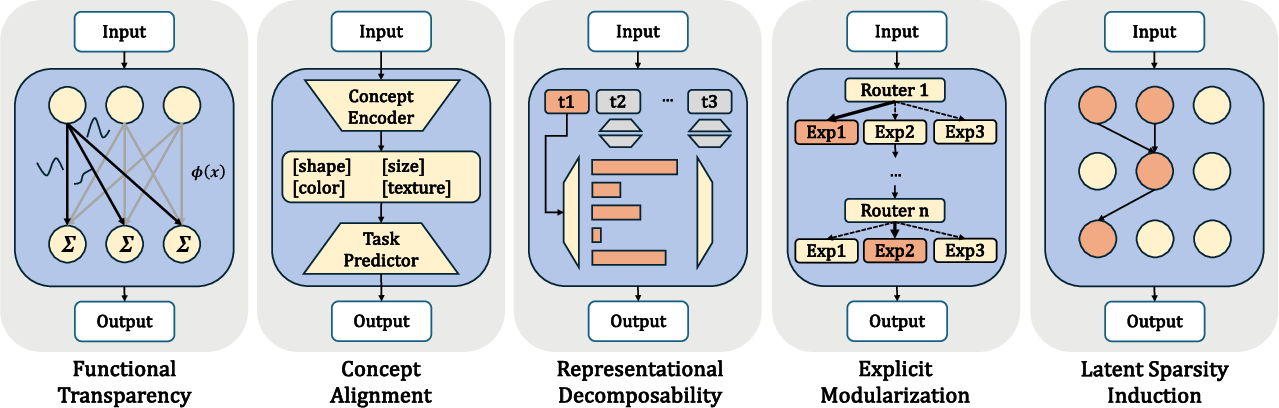
Figure 2: Taxonomy of intrinsic interpretability, organizing existing architectures into five primary principles based on the core transparency mechanism employed.
Functional Transparency
Architectures in this category adopt explicit, human-auditable computational structure. Early approaches, such as Generalized Additive Models (GAMs), model outputs as additive combinations of featurewise mappings, ensuring each component is independently inspectable. More sophisticated methods, including Neural Additive Models and Self-Explaining Neural Networks (SENN), augment the expressive power while maintaining explicit attribution pathways. Kolmogorov-Arnold Networks (KANs) offer node-based spline parameterizations for improved symbolic traceability, at the cost of higher computational and optimization complexity. Such designs facilitate direct alignment between model computations and explanatory rationale but often trade off expressivity and training efficiency.
Concept Alignment
The concept alignment principle enforces explicit mapping of latent units to semantically meaningful concepts. Concept Bottleneck Models (CBMs) exemplify this family by constraining predictions to flow through a human-interpretable concept layer. Hybrid variants relax the hard bottleneck at some performance cost, while Concept Embedding Models (CEMs) generalize concepts to higher-dimensional embeddings to mitigate expressivity losses. Recent unsupervised approaches, notably Codebook Features, investigate vector quantization bottlenecks for emergent, annotation-free concepts. Despite enhancing explanation accessibility and actionable intervention, these models risk underfitting complex dependencies not captured by the supplied concepts.
Representational Decomposability
This direction constrains the model’s latent space geometry to disentangle independent semantic factors, often via orthogonal subspaces or additive decompositions. The Backpack LLM constructs context-sensitive predictions from additive mixtures of sense vectors, supporting localized interpretation and targeted behavioral interventions. Extensions to non-alphabetic scripts validate the decomposability approach in morphologically rich environments. Compositional architectures such as CoCoMix combine autoencoding with continuous concept mixing to enforce reasoning over disentangled features. Control and inspection of such models are improved, but may face limitations when semantic factors interact in nonlinear ways.
Explicit Modularization
Modularization techniques utilize architectural decomposition, with Mixture-of-Experts (MoE) as the main instantiation. Advancements focus on enforcing intra-expert sparsity, fine-grained decomposition, or semantically aligned routing policies to enhance transparency. Models such as MONET and MxD maximize monosemantic expert specialization through tensor factorization and routing manifold constraints, while Task-Based and Language-Family MoEs implement context-aligned routing for interpretability gains. This family demonstrates that interpretability and scalability are compatible given architectural innovations, but introduces new optimization and load-balancing complications.
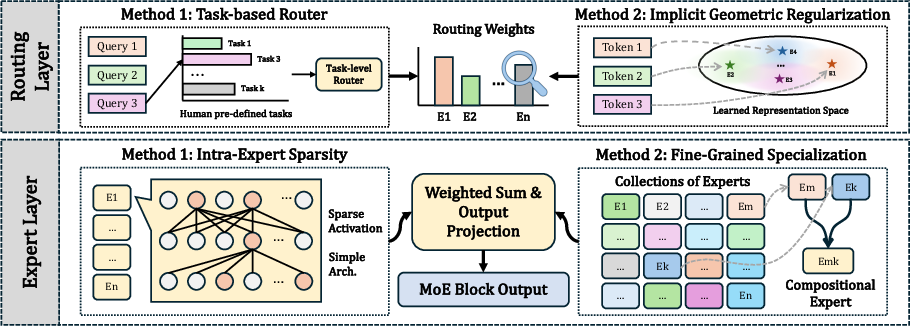
Figure 3: Architectural strategies in interpretable MoEs: sparsity in experts, fine-grained monosemantic decomposition, and semantically guided routing.
Latent Sparsity Induction
Rather than explicit modular architecture, latent sparsity induction introduces regularizers or activations that promote conditional sparsity and superposition reduction within otherwise standard architectures. Weight-sparse Transformers, enforced via L0 regularization or structured gating (e.g., GLU, SwiGLU), exhibit emergent interpretable circuits but at the expense of optimization stability and sometimes raw downstream performance. Linking sparse and dense models by coupling representations aids transfer of interpretable features. These approaches highlight the performance-interpretability trade-off and the necessity for more hardware-aligned implementations.
Evolution of Intrinsic Interpretability
The evolution of intrinsically interpretable architectures is traced from rigid, low-capacity models such as GAMs to contemporary modular, sparse designs capable of scaling to high-dimensional tasks without sacrificing transparency. This trajectory underscores a shift toward architectures that simultaneously enable high fidelity explanations and competitive accuracy.
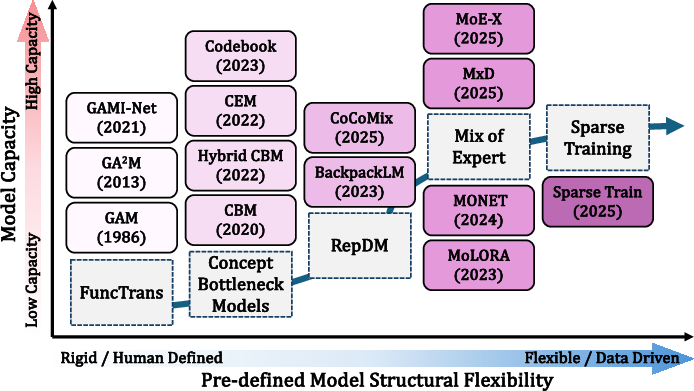
Figure 4: Historical progression from simple, hand-crafted interpretable models to scalable, data-driven modular and sparse architectures balancing interpretability and performance.
Open Challenges and Theoretical Implications
The survey identifies outstanding issues critical to the maturation of this field:
- Definitional Rigor and Evaluation: Consensus is lacking for what constitutes intrinsic interpretability, or how to evaluate faithfulness, completeness, and utility of explanations without resorting to opaque proxies.
- Interpretability-Expressivity Trade-off: Despite recent evidence that interpretability can co-exist with high task performance, imposing intrinsic constraints often limits expressivity, especially in high-complexity language tasks.
- Scalability: Demonstrations at billion-parameter scale remain nascent, with unresolved optimization, routing, and computational efficiency barriers.
- Training Dynamics: The addition of modular constraints or sparsifying dynamics frequently disrupts optimization and complicates large-scale training.
- Integration with Post-hoc Analysis: The complementarity of intrinsic design and post-hoc diagnostic tools is not fully exploited; hybrid strategies are an open promising direction.
Theoretical implications of this review include a reframing of LLM interpretability research as a problem that should prioritize faithfulness and structural causal intervention alongside human accessibility. The taxonomy provides actionable guidance for architecture designers, offering points of intervention to align with targeted interpretability desiderata.
Future Prospects
Ongoing trends suggest increasing sophistication in architectural mechanisms that embed interpretability while preserving scalability and task performance. Hybridization of intrinsic mechanisms with advanced post-hoc analysis is likely, especially for applications in high-risk domains. Realizing robustly interpretable, trustworthy LLMs will necessitate progress in formalizing interpretability metrics, improving sparse and modular training algorithms, and demonstrating solutions at production scale.
Conclusion
The survey delivers an authoritative synthesis of intrinsic interpretability in LLMs, offering a comprehensive taxonomy, theoretical framing, and mapping of recent advances within five design paradigms. The authors critically delineate capabilities and limitations of each architectural principle and chart key challenges as focal points for future research. Their work provides a blueprint for structuring future development and evaluation of transparent LLMs, with implications for both model safety and the scientific understanding of high-dimensional neural representations.