- The paper shows that Brain Score does not capture language-specific processing, revealing similar activation patterns in LMs trained on various natural and structured datasets.
- It employs a GPT-2 style model with an embedding adaptation phase to isolate the effects of training data structure from lexical content.
- The findings suggest that universal structural properties drive high Brain Scores, cautioning against equating BS improvements with human-like language comprehension.
Brain Score Tracks Shared Properties of Languages: Evidence from Many Natural Languages and Structured Sequences
Introduction
The paper "Brain Score Tracks Shared Properties of Languages: Evidence from Many Natural Languages and Structured Sequences" (2604.15503) interrogates the interpretative validity of using Brain Score (BS)—a metric quantifying the similarity of LM activations to human fMRI data—as a proxy for human-like language processing in neural LMs. By evaluating LMs trained on an array of both natural and formal sequence datasets, the study aims to dissect whether high BS is fundamentally language-specific or instead reflects shared, possibly non-language-specific representational structure.
Experimental Design and Methodology
The experimental pipeline consists of training GPT-2-style LMs (12-layer, 117M parameters) from scratch on distinct datasets, including seven natural languages (across diverse language families), formal/semi-formal structures (Python code, nested parentheses/Dyck language, human genome), and unstructured controls (scrambled English, random weights). Post-training, all models underwent an embedding adaptation phase where only English embeddings were further trained on English text (freezing other parameters) to enable evaluation on English fMRI BS tasks. This experimental design allows for clear attribution of BS variance to training data structure distinct from lexical overlap.
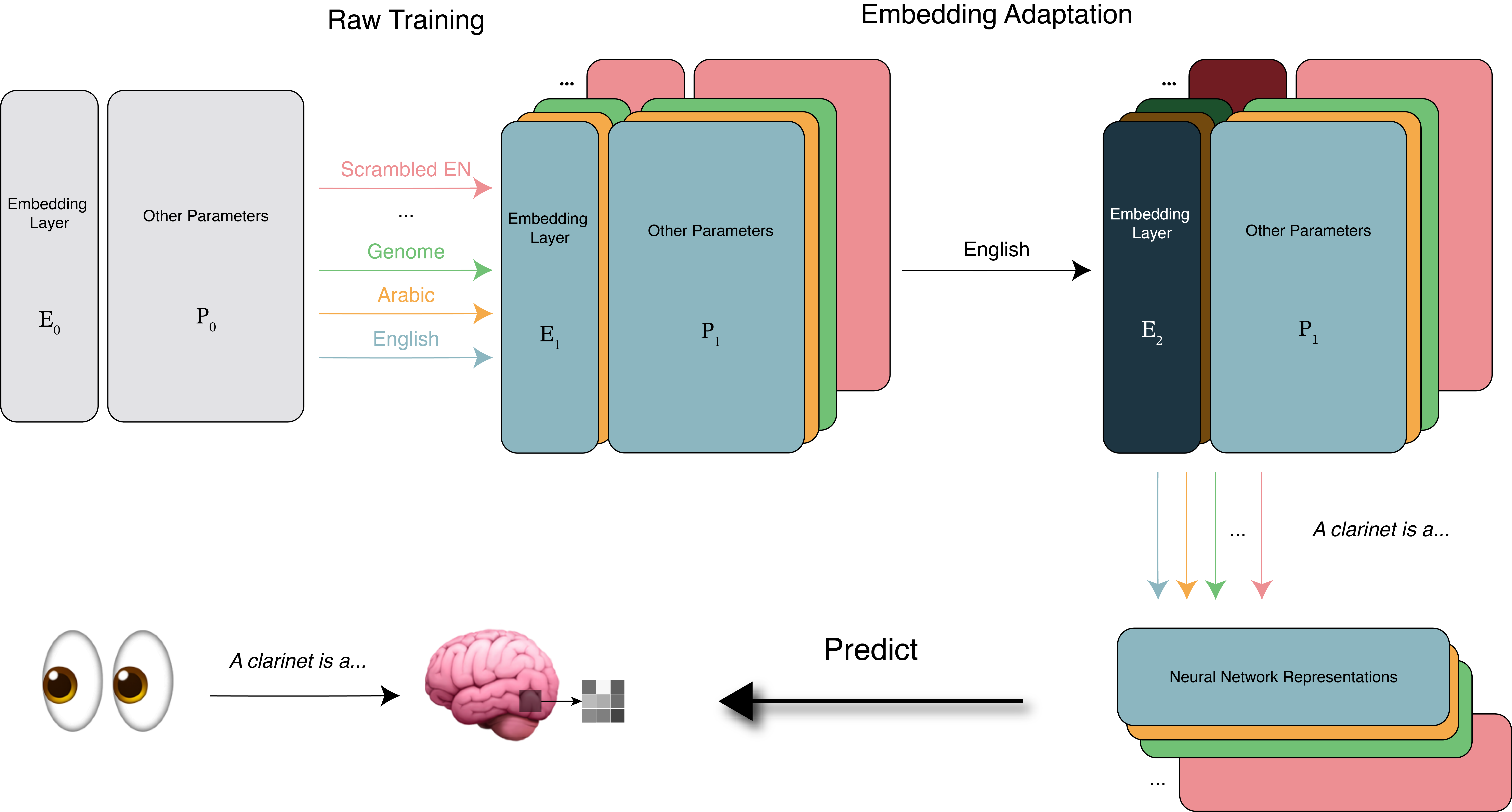
Figure 1: The model training and evaluation pipeline, including pretraining on various datasets, English embedding adaptation, and BS evaluation on English fMRI data.
Evaluation leverages BS as in [schrimpfNeuralArchitectureLanguage2021]: a linear model is fitted from LM activations to human fMRI responses, and Pearson correlation (normalized by a cross-subject ceiling) forms the BS metric. Two English fMRI datasets—Wikipedia-style and Wikipedia plus narratives—enable testing for both style and domain variance. Five random seeds per run ensure statistical robustness.
Results
A core finding is that LMs pretrained on diverse natural languages and subsequently adapted via English lexical embeddings achieve statistically indistinguishable BS when evaluated on English fMRI datasets. This holds regardless of typological differences in the L1 pretraining languages. Notably, models pretrained on structured sequences like Python code and Dyck language also achieve BS levels approaching those of natural LLMs, especially after embedding adaptation, while scrambled English and random initializations perform substantially worse.
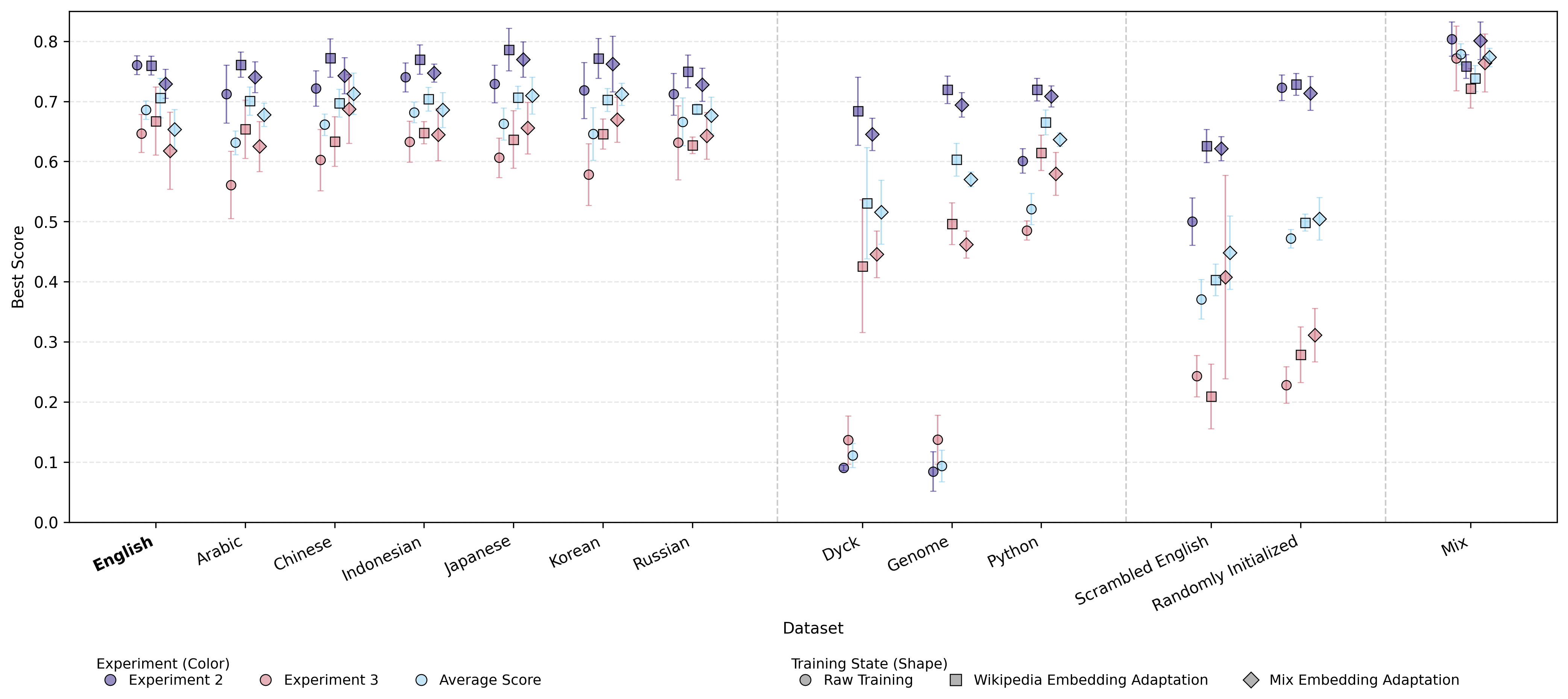
Figure 2: BS results across models pretrained on various datasets and subject to different adaptation regimes, showing minimal differences among natural languages and high BS for structured data like Python.
The Python-pretrained model exhibits only a marginal deficit compared to natural language baselines in Experiment 2 (Wikipedia stimuli) and, in some cases, is statistically indistinguishable from natural LLMs in Experiment 3 (Wikipedia + narratives). Conversely, training on scrambled/unstructured data demonstrably impairs the ability to achieve high BS, even after embedding adaptation.
The embedding adaptation phase confers the most gain for models originally trained on highly non-semantic data (Dyck, genome, Python), less so for natural LLMs, and virtually no effect for untrained/random baseline models. Adapting via domain-matched data (Mix: English Wikipedia + Project Gutenberg) rather than Wikipedia alone does not close domain-induced BS gaps in non-native models, highlighting limitations in domain transfer via shallow lexical adaptation.
Analytical Discussion
These results directly challenge the notion that high BS is evidence of human-like, language-specific computations in LMs. Two points emerge:
- Lack of language-specificity: The inability of BS to distinguish among models trained on typologically distinct languages implies that the metric is tracking language-general properties—likely including statistical or syntactic regularities common to all natural languages—rather than language-specific mapping from form to meaning.
- Sensitivity to structural, not semantic, information: The high BS achieved by Python and Dyck-trained models suggests that hierarchical or compositional structure, even in non-linguistic domains, is sufficient for LMs to produce activations mapping onto neural correlates of English comprehension. This supports views from previous studies that lexical-semantic content drives much of BS [kaufLexicalSemanticContentNot2024], but also that non-lexical, non-semantic structure plays a significant role.
The strong effect of embedding adaptation for models lacking natural language semantics, but not for natural LLMs, further supports the hypothesis that BS measures the presence of shared structural priors more than nuanced, language-/task-specific grounding.
Theoretical and Practical Implications
The findings necessitate caution in interpreting high BS as evidence for human-like or language-specific processing in current LMs. The metric as formulated is not sensitive to the encoding of semantic content specific to English or, more broadly, to the full range of processes underpinning human language comprehension.
Practically, this indicates that improvements in BS should not be straightforwardly equated with progress toward brain-like language processing. For downstream applications, reliance on BS as an evaluation metric should be accompanied by more stringent, task- and content-specific probes, especially when evaluating alignment with human neural computation.
Theoretically, these results support the notion that certain aspects of neural processing during language comprehension reflect domain-general hierarchical and sequential structure representation, positing a shared substrate between natural and some artificial languages—albeit at a possibly superficial or formal level. Future work should explore cross-linguistic neural data collection as well as refinements of similarity metrics to distinguish between language-general, language-specific, and structure-general representational content.
Directions for Future Work
Potential avenues to address BS's insensitivity to fine-grained language-specific content include:
- Collecting cross-linguistic neural data to establish a cross-lingual BS "noise ceiling" and enable direct testing of structure- versus content-sensitivity.
- Investigating alternative adaptation mechanisms (e.g., Procrustes alignment, non-parametric transformation) that more directly transfer deep structure rather than superficial lexical mapping.
- Developing new metrics targeting semantic and pragmatic processing in context-sensitive and typologically diverse setups.
Conclusion
This research demonstrates that BS, as a measure of brain-LM similarity in language processing, largely reflects representations of structure and regularity shared across languages—natural or otherwise—rather than language-specific mechanisms. High BS scores for models trained on non-linguistic but structured data (Python, Dyck) reinforce that BS evaluates universal computational capacity for sequence structure rather than English-specific semantic processing. Accordingly, claims linking high BS in LMs to their human-likeness or language understanding should be qualified and supplemented with more fine-grained, language-specific neural probes.

