Exascale Multi-Task Graph Foundation Models for Imbalanced, Multi-Fidelity Atomistic Data
Abstract: We present an exascale workflow for materials discovery using atomistic graph foundation models built on HydraGNN. We jointly train on 16 open first-principles datasets (544+ million structures covering 85+ elements) using a multi-task architecture with per-dataset heads and a scalable ADIOS2/DDStore data pipeline. On Frontier, we execute six large-scale DeepHyper hyperparameter optimization campaigns in FP64 and promote the top-performing message-passing models to sustained 2,048-node training, yielding a PaiNN-based lead model. The resulting model enables billion-scale screening, evaluating 1.1 billion atomistic structures in 50 seconds, compressing a workload that would require years of first-principles computation, and supports data-scarce fine-tuning across diverse downstream tasks. We quantify precision-performance tradeoffs (BF16/FP32/FP64), demonstrate transfer across twelve chemically diverse downstream tasks, and establish seamless strong- and weak-scaling across Frontier, Aurora, and Perlmutter. This work allows fast and reliable exploration of vast chemical design spaces that are otherwise inaccessible to first-principles methods.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper is about building a very large “foundation” AI model that understands how atoms interact in materials and molecules. The goal is to speed up the search for new materials (like better batteries, catalysts, or semiconductors) by replacing many super-slow physics calculations with fast AI predictions after one big training step on a supercomputer.
What questions the researchers asked
The team set out to answer a few practical questions:
- Can one model learn from many different collections of atomic data (from different sources and with different accuracy levels) all at once, even if some datasets are huge and others are small?
- Which model design works best when you care about both accuracy and speed on giant computers?
- Can the whole workflow run efficiently on different supercomputers without rewriting everything?
- After pretraining, can the model be quickly adapted (fine-tuned) to new tasks that have only a small amount of training data?
- How fast and how reliably can this model screen (check) massive numbers of candidate materials?
- Does the “precision” of the math (like the number of decimal places the computer uses) change accuracy or speed in a noticeable way?
How they did it (in everyday terms)
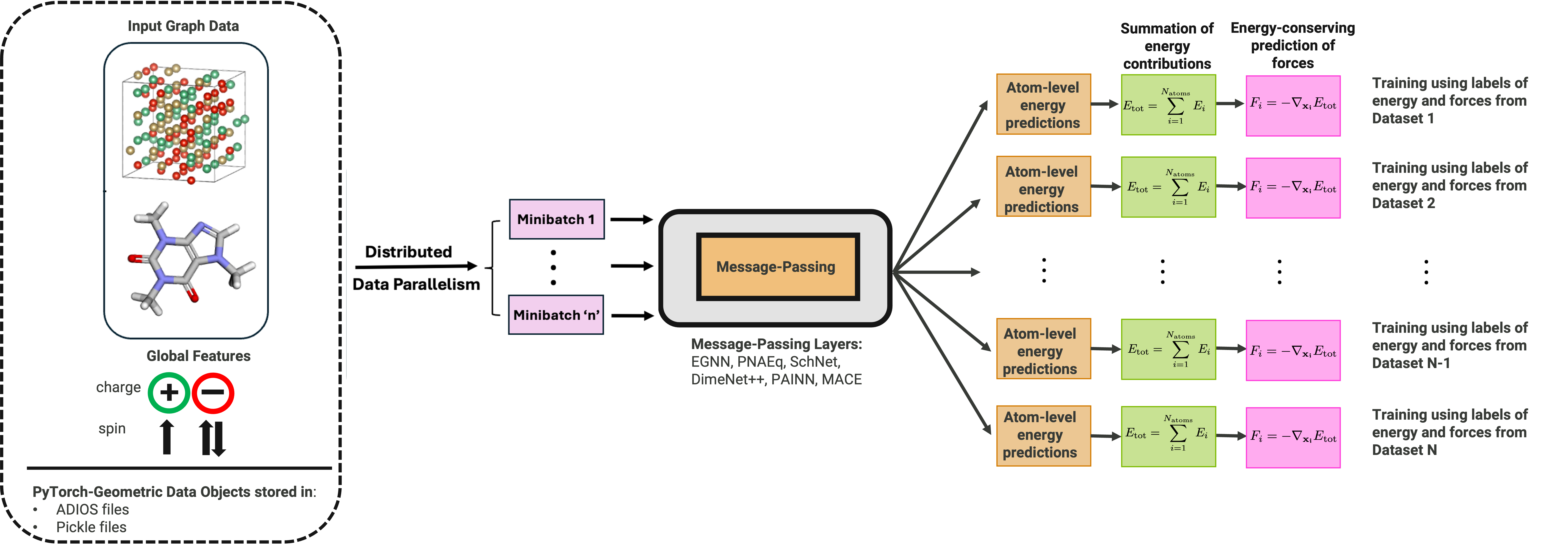
Think of each material or molecule as a network (graph) where atoms are dots and connections between nearby atoms are lines. The model they use is a graph neural network that passes messages along these connections—kind of like a whisper game where each atom talks to its neighbors to figure out the overall energy and forces in the structure.
Here are the main ideas behind their approach:
- Multi-task learning (MTL): The model has one shared “brain” that learns general atomic physics, plus separate “heads” for each dataset. This is like a student with one set of core skills who takes different tests in different subjects. Sharing the core knowledge helps the model learn more robustly from many sources at once.
- Multi-fidelity and imbalanced data: The datasets came from different physics settings and vary a lot in size and quality (some are small/high-precision, others are large/mixed). The model and training pipeline are designed to handle this uneven mix without letting the big datasets drown out the small but important ones.
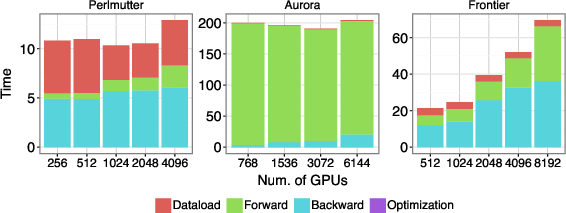
- Supercomputer-scale training: They used exascale-class systems (thousands of GPUs on machines like Frontier, Aurora, and Perlmutter). To keep the flow of data smooth, they built a fast “data logistics” system (ADIOS2/DDStore) that acts like a warehouse with conveyor belts, making sure each compute “worker” always has the next batch ready.
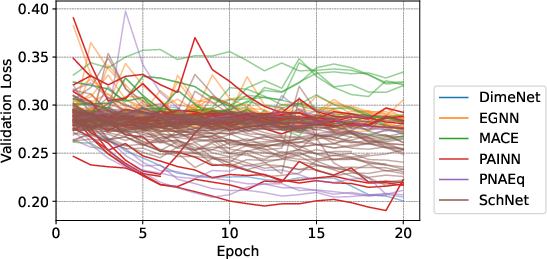
- Trying many designs automatically: They ran large hyperparameter optimization (HPO) campaigns—think of this as trying lots of recipes to find the best combination of model size, layer counts, and other settings. They tested several popular graph model backbones and picked the best performer under real training time limits.
- Blending heads at prediction time: After training, a tiny helper network looks at a material’s chemical makeup and decides how to blend the different dataset-specific heads to get the best single prediction. It’s like consulting several experts and weighting their opinions based on what the material looks like.
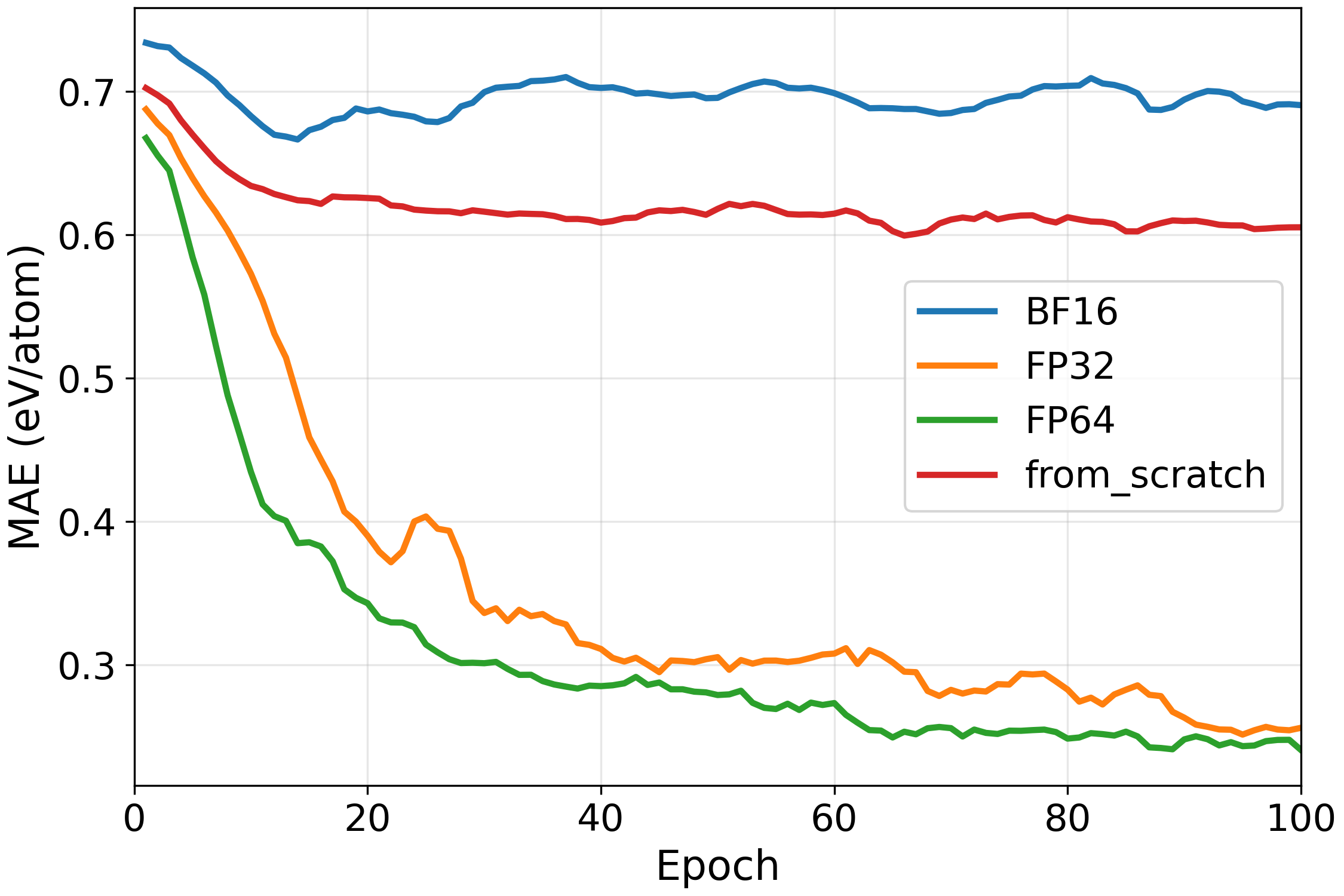
- Precision studies: They tested different numerical precisions (BF16, FP32, FP64). You can think of this as measuring with a coarse ruler vs. a fine ruler. Coarser precision is faster but can be less stable or less accurate for sensitive physics quantities.
What they found and why it matters
Below are the main results in simple terms:
- One model for many kinds of chemistry: They successfully trained a single foundation model on 16 different open datasets, covering over 544 million atomic structures and 85+ elements. This breadth makes the model more general and useful across different materials.
- A practical “best” model: Among the model designs they tried, a PaiNN-based model performed best under fixed time budgets on thousands of GPUs. It struck a good balance between accuracy, speed, and memory use (about 12 million parameters—small enough to deploy widely).
- Extreme speed for screening: The trained model can evaluate about 1.1 billion structures in around 50 seconds on a supercomputer. That compresses what would normally take years of traditional physics calculations into less than a minute, making huge material searches actually doable.
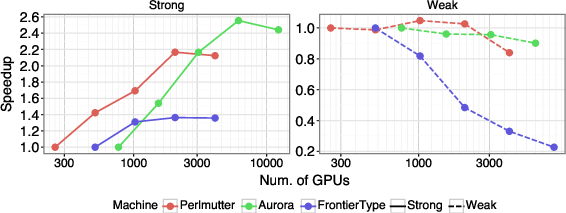
- Works across different supercomputers: The training and inference scaled well on three different large machines (Frontier, Aurora, Perlmutter) without major rework. That means the approach is portable and practical for many labs.
- Fine-tuning helps most when the task matches the physics: When adapting the model to new tasks that predict energies and forces (the same kind of physics it learned during pretraining), fine-tuning gave much better results than training from scratch—often by a large margin. For tasks that aren’t directly tied to those physics (like simple classification), the benefit was smaller.
- Precision matters for stability and accuracy: Using higher precision (FP32 or FP64) generally gave more stable and accurate fine-tuning than very low precision (BF16), especially for tasks sensitive to small numerical differences.
- A robust data pipeline: Their ADIOS2/DDStore pipeline and training strategies kept data moving fast enough to feed thousands of GPUs, enabling long, large-scale training runs and the massive HPO searches.
Why this work is important
This research shows that we can build and deploy a general-purpose AI model for atomic-scale science that:
- Dramatically accelerates the exploration of huge chemical design spaces, making it realistic to find rare, high-performance materials.
- Reduces the need for extremely expensive physics calculations (like DFT) for every candidate, saving time, energy, and money.
- Transfers well to new problems even when there isn’t much data, which is common in real scientific settings.
- Runs efficiently on different top-tier supercomputers, helping government labs, universities, and industry share methods and results more easily.
In short, this work turns the dream of “rapid materials discovery” into something practical: a reusable, fast, and accurate AI tool that can search billions of possibilities and guide scientists toward the most promising materials much faster than before.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper makes significant advances, but it leaves several concrete gaps and questions that future work can address:
- Multi-fidelity alignment across datasets remains heuristic. The use of per-dataset heads sidesteps inconsistent energy references and label noise, but the paper does not provide a principled, quantitative calibration of energies/forces across functionals (e.g., PBE vs. ωB97X, PBE+U), nor an explicit cross-fidelity mapping or hierarchical model to reconcile systematic offsets.
- Lack of uncertainty quantification for billion-scale screening. The workflow reports extreme-throughput inference but provides no calibrated prediction uncertainties, confidence intervals, or out-of-distribution (OOD) detection to manage false positives/negatives when triaging candidates for expensive validation.
- OOD and domain-shift robustness is uncharacterized. There is no explicit evaluation of generalization to chemistries or conditions far from the training set (e.g., unusual bonding motifs, extreme geometries, high pressures/strains, novel compositions), nor a strategy for flagging low-confidence predictions.
- Charged and spin-polarized systems are under-evaluated. Although global charge and spin are included as inputs and OMol25 contains non-neutral, non-singlet subsets, no fine-tuning or validation tasks probe charged species, open-shell radicals, or diverse spin states—leaving performance on these regimes uncertain.
- Long-range physics is not explicitly modeled. The lead PaiNN model uses a 5 Å cutoff and 20 neighbors without explicit long-range electrostatics or dispersion terms; the impact on systems where long-range interactions are crucial (e.g., ionic solids, polar materials, dielectric interfaces) is not assessed.
- Stress/virials are omitted. The pretraining objective covers energies and forces but not stresses, limiting immediate fidelity for crystalline materials under strain/deformation and hindering deployment in NPT/elastic-property workflows without additional training.
- Stability in molecular dynamics (MD) is not demonstrated. There is no assessment of energy conservation, long-horizon stability, or drift in MD using the pretrained model, nor a quantification of how reduced precision affects MD stability.
- Reduced-precision training remains unexplored. While BF16/FP32/FP64 are studied for inference and fine-tuning, there is no attempt to pretrain with mixed/reduced precision (e.g., BF16+loss scaling) at scale, nor guidance on stabilizing lower-precision training for energy/force consistency.
- Fine-tuning benefits do not extend to non-PES tasks. The model yields strong gains on potential-energy-surface (PES) tasks but shows little advantage on non-PES targets (e.g., exfoliation energy, metal classification). How to design pretraining objectives that also benefit non-PES properties (e.g., bandgap, magnetic moments) is unresolved.
- No ablations on multi-task design choices. The paper does not quantify the effect of per-dataset heads vs. a shared head, the impact of dataset-specific loss weights, or the role of oversampling on transferability and gradient interference across tasks.
- Branch-weight MLP routing remains minimally validated. The composition-conditioned blending uses a teacher signal tied to dataset-of-origin and ignores structural geometry; there is no ablation showing its impact on accuracy, no test on truly unseen domains, and no comparison to chemistry-aware MoE routing or structure-conditioned gating.
- Energy scale consistency under branch blending is unclear. Because different datasets have incompatible energy zeros/functionals, it is not demonstrated that the softmax blend of per-dataset heads preserves a consistent absolute energy scale for unseen inputs.
- Negative transfer and gradient interference are not analyzed. The work proposes MTL to mitigate interference but does not provide metrics (e.g., conflict angles, PCGrad/GradNorm/DWA comparisons) or experiments quantifying when/where negative transfer occurs and how to mitigate it.
- HPO selection may be biased by subsampling. Architecture choice is based on 10% per-dataset sampling and backbone-specific hidden-dimension ranges constrained by memory budgets; there is no study of how these constraints bias selection or whether rankings persist at full data scale.
- Limited architectural breadth. Transformers/equivariant-transformers (e.g., EquiformerV2), higher-order equivariant models, and modern scalable MoE backbones are not included in HPO, leaving open whether newer architectures could dominate under the same constraints.
- Communication bottlenecks at extreme scale are unresolved. Strong-scaling efficiency degrades due to gradient-aggregation saturation; gradient compression, overlap strategies, or optimizer/state sharding (e.g., ZeRO/FSDP variants) are not explored.
- Data-label noise is unmodeled. The workflow acknowledges heterogeneous label noise across sources but does not implement noise-aware loss functions, per-dataset noise models, or robust estimators to prevent overfitting spurious labels.
- Dataset weighting and curriculum are ad hoc. Beyond oversampling, there is no adaptive dataset/task weighting based on gradient variance, loss curvature, or uncertainty; the effects of more principled schedulers or curricula (e.g., multi-fidelity annealing) remain unexplored.
- Cross-dataset unit and target normalization are under-specified. The paper does not detail how per-atom vs per-cell energies or unit conventions are harmonized across datasets, nor how normalization interacts with head specialization and branch blending.
- Generalization to kinetics and barriers is not tested. Apart from a small MS25 reaction set, there is no evaluation on reaction barrier prediction (e.g., NEB pathways), which is central for catalysis discovery.
- Screening outcome quality is unvalidated. The 1.1B-structure screening throughput is impressive, but there is no closed-loop validation (e.g., DFT re-ranking) to report hit rates, enrichment factors, or downstream success metrics.
- Incremental onboarding of new datasets is untested. While the framework supports modular heads, the practical procedure and stability for adding new datasets/functionals (without retraining from scratch or catastrophic interference) are not demonstrated.
- Representation interpretability is absent. There is no analysis of what features are learned, how they correlate with chemical intuition, or how interpretability could guide error diagnosis and dataset acquisition.
- Energy/computational cost and carbon footprint are unreported. The end-to-end energy usage of HPO and pretraining campaigns is not measured, leaving open how to trade off accuracy, throughput, and sustainability.
- Reproducibility at exascale is not characterized. Determinism across 10k+ GPUs, sensitivity to MPI/NCCL ordering, and seed management are not evaluated, complicating exact replication and debugging at production scale.
- Scaling of model capacity vs. accuracy is not charted. The chosen lead model is moderate (≈12M params); the Pareto frontier between capacity, accuracy, and throughput remains unmapped, limiting guidance for task-specific deployments.
- Periodic-boundary handling details are incomplete. Although PBCs are used in some fine-tuning tasks, the pretraining regime’s PBC treatment, neighbor-list policies, and their influence on transfer to periodic systems are not fully documented.
- Lack of benchmarking against contemporary foundation MLIPs. There is no head-to-head, protocol-matched comparison to models such as MACE-MP-0/OMAT-1, UMA, CHGNet, or DPA-2 on shared downstream tasks and identical training budgets.
- No pathway to incorporate electronic descriptors. Pretraining targets are energies/forces only; integrating electronic properties (e.g., partial charges, spin densities, DOS) as auxiliary tasks to improve transfer to non-PES targets is not investigated.
Practical Applications
Immediate Applications
The paper delivers an exascale, multi-task atomistic graph foundation model and a portable HPC workflow (HydraGNN + ADIOS2/DDStore + DeepHyper + Omnistat) that can be used today to accelerate PES-aligned tasks (energies/forces). The following use cases are deployable now:
- Fast virtual screening of candidate materials and surfaces
- Sectors: energy, chemicals, catalysis, carbon management
- What: Prioritize large libraries of catalysts (e.g., OC20/OC22/OC25 surfaces), direct-air-capture sorbents (ODAC23), 2D materials (MB-jdft2d), perovskites (ABX3), alloys, and polymers by predicted energies to triage compounds for DFT/experimental follow-up.
- Tools/workflows: Pretrained PaiNN checkpoint + HydraGNN inference; ADIOS2/DDStore-backed data loading; composition-conditioned branch MLP for routing; integration with ASE for batch evaluation; on-prem clusters for million- to billion-scale triage (exascale delivers 1.1B in ~50 s; enterprise clusters deliver millions–tens of millions per day).
- Assumptions/dependencies: Targets align with PES; candidate chemistries are within the training set’s coverage (85+ elements but not universal); FP32/FP64 recommended for stability; screening outputs still require higher-fidelity validation.
- Rapid fine-tuning of MLIPs in low-data regimes
- Sectors: academia, materials R&D (industrial and academic), software
- What: Fine-tune the pretrained backbone on limited, system-specific PES data (e.g., MD17, MS25, OQMD, ABX3) to obtain high-accuracy MLIPs with far fewer labels than training from scratch.
- Tools/workflows: HydraGNN fine-tuning utilities (unfrozen backbone + new head); FP32/FP64 training; small-domain curation to include energies/forces; validation against DFT trajectories.
- Assumptions/dependencies: Clear gains demonstrated only for PES tasks; non-PES targets show limited benefit; adequate coverage of local chemistry/structures in fine-tuning data.
- Drop-in MLIP for molecular dynamics and structure optimization
- Sectors: software (MD/DFT ecosystems), energy, chemicals
- What: Use the pretrained/fine-tuned model as an interatomic potential for energy/force evaluation in ASE/LAMMPS to accelerate MD, geometry optimization, and reaction path exploration.
- Tools/workflows: ASE calculator integration; LAMMPS hooks to PyTorch models; precision set to FP32/FP64; periodic boundary support for condensed-phase tasks.
- Assumptions/dependencies: Stability must be validated for target thermodynamic/kinetic regimes; cutoffs/neighbor lists require tuning per system; out-of-distribution (OOD) behavior should be monitored.
- Catalyst surface workflows for adsorbate screening
- Sectors: energy (green ammonia, e-fuels), chemicals (CO₂ reduction), process R&D
- What: Enumerate adsorbate–surface configurations at scale, compute relative PES-based metrics to rank candidates before expensive DFT campaigns.
- Tools/workflows: OC datasets + HydraGNN inference; automated generation of slab/adsorbate geometries; branch MLP for cross-dataset blending; feedback loop to DFT for top-N validation.
- Assumptions/dependencies: PES-accuracy dependence; surface reconstructions or strongly correlated systems may require additional fine-tuning.
- Materials triage for batteries and devices
- Sectors: energy storage, semiconductors
- What: Pre-screen perovskites, 2D layered materials, and polymer electrolytes by formation energy proxies to accelerate downselection for synthesis and device prototyping.
- Tools/workflows: Bulk/2D structure libraries + HydraGNN predictions; automated ranking dashboards; targeted experimental validation.
- Assumptions/dependencies: Non-PES properties (e.g., band gaps, ionic conductivity) not directly predicted; requires property-to-PES proxy logic; additional models needed for electronic/transport properties.
- Precision-aware deployment and reproducible HPC training
- Sectors: HPC/ML engineering (academia and industry), national labs
- What: Adopt the paper’s guidance to use FP32/FP64 for fine-tuning/inference in PES tasks; instrument runs with Omnistat for utilization/telemetry; follow provided installation scripts for Frontier/Aurora/Perlmutter-class systems.
- Tools/workflows: HydraGNN scripts; Omnistat; ADIOS2/DDStore for I/O; sbcast+NVMe staging on applicable systems.
- Assumptions/dependencies: Access to GPU-enabled HPC resources; facility-specific module stacks (ROCm/oneAPI/CUDA).
- Resource-aware HPO for architecture selection
- Sectors: software/MLOps, academia
- What: Use DeepHyper + Omnistat to explore architecture/backbone choices (e.g., PaiNN vs. MACE/SchNet/DimeNet) under fixed budgets, leveraging oversampling to balance imbalanced datasets during HPO.
- Tools/workflows: DeepHyper driver; HydraGNN HPO search spaces; telemetry-guided pruning.
- Assumptions/dependencies: Requires moderate HPC allocation; results depend on the representative subsample quality.
- Multi-source model maintenance with dataset-specific heads
- Sectors: academia, industry consortia
- What: Add new datasets/fidelity levels via additional task-specific heads while keeping a shared backbone to mitigate gradient interference and fidelity offsets.
- Tools/workflows: HydraGNN multi-task heads; composition-conditioned blending at inference; CI pipelines to integrate new sources.
- Assumptions/dependencies: New data must be labeled consistently (energies/forces) and curated for noise; branch assignment or blending should be validated.
Long-Term Applications
The workflow and results open pathways that need further research, validation, scaling, or ecosystem development before broad deployment:
- Autonomous, closed-loop materials discovery
- Sectors: energy, chemicals, advanced manufacturing, robotics
- What: Integrate exascale screening with robotic synthesis and active learning to iteratively propose, synthesize, test, and retrain—minimizing human-in-the-loop.
- Tools/products: Orchestration platforms (e.g., with Bayesian optimization), lab robots, LIMS integration; real-time retraining using HydraGNN.
- Assumptions/dependencies: Reliable uncertainty estimates; robust OOD detection; standardized lab interfaces and data schemas.
- Universal MLIPs as DFT surrogates for production MD
- Sectors: software, process engineering, energy devices
- What: Replace significant fractions of DFT-based MD in R&D pipelines for surfaces, interfaces, and condensed phases with validated universal MLIPs, enabling orders-of-magnitude longer time/length scales.
- Tools/products: Certified MLIP packages; MD engines with MLIP-first backends; validation suites for stability/accuracy.
- Assumptions/dependencies: Extensive cross-domain validation, especially for reactive events; stability under diverse thermodynamic conditions; governance for model updates.
- Multi-objective property optimization beyond PES
- Sectors: semiconductors, energy, chemicals
- What: Extend multi-task training to incorporate labels for electronic, optical, and transport properties (e.g., band gaps, dielectric constants) for joint screening across stability, performance, cost, and safety.
- Tools/products: Expanded multi-fidelity datasets; physics-informed heads; multi-objective optimizers.
- Assumptions/dependencies: High-quality labels for non-PES properties; careful handling of conflicting objectives and fidelity mismatches.
- Materials screening platforms (“Materials GPT”)
- Sectors: software/SaaS, enterprise R&D
- What: Cloud/on-prem services offering API-based screening, fine-tuning, and triage dashboards with governance, versioning, and audit trails.
- Tools/products: Hosted HydraGNN inference; user-facing portals; billing and quota management.
- Assumptions/dependencies: IP protection and data residency; cost control for large-scale runs; robust SLAs and reproducibility guarantees.
- Federated, privacy-preserving multi-source training
- Sectors: industry consortia (chemicals, battery, pharma), government
- What: Train shared backbones across institutions while keeping dataset-specific heads private to each partner, enabling cross-organization generalization without data sharing.
- Tools/products: Federated learning frameworks; secure aggregation; per-branch MTL design tailored for privacy.
- Assumptions/dependencies: Legal frameworks for collaboration; communication-efficient protocols; harmonized metadata.
- Digital twins coupling atomistic MLIPs with continuum/device models
- Sectors: energy devices (batteries, fuel cells, electrolyzers), manufacturing
- What: Embed MLIP-based microscale physics in multi-scale digital twins for process optimization, failure analysis, and predictive maintenance.
- Tools/products: Co-simulation frameworks; reduced-order models; data assimilation pipelines.
- Assumptions/dependencies: Verified cross-scale coupling; efficient inference at runtime; uncertainty propagation across scales.
- Regulatory and policy pre-screening for sustainable materials
- Sectors: policy, procurement, ESG
- What: Use fast PES-based stability screens to shortlist greener alternatives and reduce reliance on critical/regulated materials before commissioning costly studies.
- Tools/products: Government-operated screening services; standardized reporting on uncertainty and validation; integration with LCA and toxicity databases.
- Assumptions/dependencies: Formal validation protocols; traceable uncertainty estimates; updates as datasets/models evolve.
- In-situ/edge deployment in scientific instruments
- Sectors: instrumentation, advanced characterization
- What: Deploy compact models (~92 MB) on instrument-adjacent hardware (SEM/TEM/STM or catalysis rigs) to guide sampling, scan parameters, and in-situ optimization.
- Tools/products: Edge inference runtimes; instrument control software plugins; low-latency pipelines.
- Assumptions/dependencies: Deterministic latency; robust operation in limited-resource environments; safety/override mechanisms.
- Education and workforce development in exascale scientific ML
- Sectors: academia, national labs
- What: Curricula and training programs around multi-fidelity MTL, HPO at scale, precision sensitivity, and reproducible HPC workflows across heterogeneous architectures.
- Tools/products: Open courseware; training clusters; hands-on labs using the paper’s scripts and datasets.
- Assumptions/dependencies: Access to shared compute; sustained funding and community support.
- Finance-informed R&D portfolio optimization
- Sectors: finance, corporate R&D strategy
- What: Couple screening outputs with techno-economic models to prioritize projects with best risk-adjusted promise (e.g., catalysts/battery materials pipelines).
- Tools/products: Decision-support dashboards; pipeline analytics combining ML predictions, cost, supply-chain, and ESG metrics.
- Assumptions/dependencies: Calibrated mapping from PES proxies to product-relevant KPIs; treatment of uncertainty in investment decisions.
Glossary
- ADIOS2: A high-performance, scalable I/O framework for data movement in HPC workflows. "ADIOS2/DDStore data pipeline"
- AdamW: An optimizer that decouples weight decay from the gradient-based update to improve generalization. "with an AdamW optimizer initialized at a learning rate of "
- Aurora: A leadership-class supercomputer at the Argonne Leadership Computing Facility (ALCF). "ALCF Aurora"
- BF16: Brain floating point 16-bit precision format used to accelerate training/inference with reduced precision. "BF16/FP32/FP64"
- Burst buffer: Fast, node-local storage used to stage data and environments close to compute resources. "each node's burst buffer"
- Catastrophic forgetting: The tendency of a model to forget previously learned knowledge when trained on new data. "to limit catastrophic forgetting"
- CUDA: NVIDIA’s parallel computing platform for GPU programming. "targets CUDA/A100 execution"
- DDStore: A distributed data store used to stage and cache dataset shards near compute to reduce I/O bottlenecks. "DDStore-based workflows"
- DeepHyper: A scalable hyperparameter optimization framework for large HPC systems. "DeepHyper hyperparameter optimization campaigns"
- Density functional theory (DFT): An ab initio electronic-structure method widely used to compute energies and forces of materials and molecules. "density functional theory (DFT)"
- Device mesh: A parallel execution layout that maps computation across multiple devices in a structured topology. "task-parallel/device-mesh paths"
- DimeNet: A message-passing neural network architecture that uses directional information via angular basis functions. "DimeNet"
- Distributed data parallelism: A training strategy that replicates models across devices and aggregates gradients to scale learning. "distributed data parallelism"
- EGNN: An equivariant graph neural network that preserves geometric symmetries in its message passing. "EGNN"
- Equivariant: Property of a model whose outputs transform consistently with inputs under symmetry operations (e.g., rotations). "equivariant graph models"
- Exascale: Computing at or beyond 1018 floating-point operations per second, enabling extremely large-scale simulations and learning. "exascale workflow"
- Fine-tuning: Adapting a pretrained model to a new task or dataset, often with limited labeled data. "data-scarce fine-tuning across diverse downstream tasks"
- First-principles: Methods that compute material properties directly from fundamental physics without empirical parameters. "first-principles methods"
- Frontier: A leadership-class exascale supercomputer at OLCF used for large-scale training and inference. "On Frontier"
- GPTL: An HPC timing library for instrumenting applications to measure runtime performance. "timers (GPTL)"
- Graph foundation model (GFM): A broadly pretrained graph-based model designed to transfer across many downstream tasks and domains. "atomistic graph foundation models (GFMs)"
- Gradient aggregation: The cross-device reduction step that combines gradients during distributed training. "gradient aggregation"
- HydraGNN: A scalable graph neural network framework for atomistic modeling with multi-task and distributed training support. "HydraGNN"
- Hyperparameter optimization (HPO: The automated search over training and architecture settings to improve model performance. "HPO campaigns"
- Lustre: A high-performance parallel file system commonly used on supercomputers. "shared Lustre file system"
- MAE: Mean Absolute Error, a common metric for regression accuracy. "Validation MAE"
- MACE: An equivariant message-passing architecture for accurate atomistic potentials. "MACE"
- Message-passing neural network (MPNN): A GNN class where nodes exchange information via edges to learn from graph structure and geometry. "message-passing neural network (MPNN) backbones"
- Mixture of Experts (MoE): An architecture that routes inputs to specialized expert modules to improve capacity-efficiency. "mixture of experts (MoE)-style design"
- Mixed precision: Using multiple numeric precisions in a single workflow to trade off accuracy and speed. "mixed precision"
- MPI: The Message Passing Interface, a standard for distributed-memory parallel programming. "MPI-enabled"
- Multi-fidelity: Combining data generated at different levels of accuracy or approximation in a single training corpus. "multi-fidelity datasets"
- Multi-task learning (MTL): Training a shared model to solve multiple tasks jointly, often with task-specific heads. "Multi-task learning training"
- NVMe: Non-Volatile Memory Express; high-throughput, low-latency SSD storage used for node-local staging. "non-volatile memory (NVMe) storage"
- Omnistat: A monitoring tool that captures utilization and telemetry for HPC applications. "Omnistat telemetry"
- PAW: Projector Augmented-Wave method used in DFT to treat core electrons efficiently. "DFT (RPBE/PAW)"
- PBE(+U): A DFT exchange–correlation functional (PBE) with an added Hubbard U correction for strongly correlated systems. "DFT (PBE(+U)/PAW)"
- Perlmutter: A leadership-class supercomputer at NERSC used for training and scaling studies. "Perlmutter"
- Periodic boundary conditions: A modeling technique that treats a finite cell as repeating infinitely to mimic bulk materials. "periodic boundary conditions"
- PaiNN: An equivariant message-passing architecture using scalar and vector features for atomistic modeling. "PaiNN-based lead model"
- PNAEq: An equivariant adaptation of Principal Neighbourhood Aggregation used as an MPNN backbone. "PNAEq"
- Potential energy surface (PES): The energy landscape as a function of atomic positions that governs molecular and materials behavior. "potential energy surface (PES)"
- ReduceLROnPlateau: A learning-rate scheduler that lowers the rate when a metric has stopped improving. "ReduceLROnPlateau"
- ROCm: AMD’s open software stack for GPU computing. "ROCm-based"
- ROCAUC: Receiver Operating Characteristic Area Under the Curve; a metric for binary classification performance. "ROCAUC"
- SchNet: A continuous-filter convolutional MPNN designed for molecules and materials. "SchNet"
- sbcast: A parallel broadcast utility used to copy files to compute nodes at job launch. "multi-threaded sbcast"
- Sharded distributed execution: Splitting model/state across devices to reduce memory per device and improve scalability. "sharded distributed execution"
- Strong scaling: Measuring performance as more resources are applied to a fixed-size problem. "Strong-scaling and weak-scaling experiments"
- Synthetic oversampling: Increasing representation of minority datasets by resampling to balance training. "synthetic oversampling"
- Time-to-solution: Total wall-clock time required to complete a full application workflow or job. "time-to-solution"
- Weak scaling: Measuring performance as problem size grows proportionally with resources. "For weak scaling, the number of samples per GPU is kept constant"
- XPU: A generic term at ALCF for heterogeneous accelerator platforms supported by a common software module. "XPU frameworks module"
Collections
Sign up for free to add this paper to one or more collections.