- The paper introduces MemoSight which unifies context compression and multi-token prediction using special tokens and position-aware alignment to enhance reasoning efficiency.
- It demonstrates up to 66% KV cache reduction, 1.56x inference speed improvement, and maintains accuracy within 2% of baseline benchmarks.
- The framework enables scalable deployment in constrained environments without architectural modifications while preserving step-wise reasoning integrity.
MemoSight: A Unified Framework for Reasoning Efficiency in LLMs
Chain-of-Thought (CoT) reasoning underpins advanced performance in LLMs, but the token-dependent KV cache growth imposes severe latency and memory bottlenecks. While context compression and Multi-Token Prediction (MTP) respectively address memory and speed constraints, their integration has proven technically challenging—their optimization and architectural requirements diverge, leading to performance degradation with naive combinations. The MemoSight framework proposes a principled, unified solution that leverages special tokens and position-aware alignment, achieving efficient, scalable reasoning without architectural modifications.
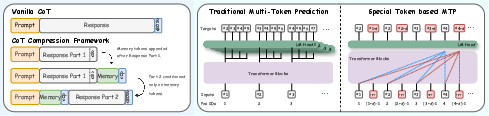
Figure 1: Context compression via memory tokens and multi-token prediction via foresight/register tokens, highlighting unified token handling in MemoSight.
Framework Overview and Technical Design
MemoSight introduces “memory tokens” for step-wise context compression and “foresight tokens” for parallel multi-token prediction, both implemented through sequence augmentation and specialized position ID assignments. Training data is constructed by interleaving foresight tokens before each reasoning token, dynamically assigning memory tokens after reasoning blocks proportional to a configurable compression rate.
Position-aware alignment assigns foresight token PIDs to project d steps ahead (for MTP) and memory token PIDs by interpolating across the reasoning step’s positional span (for context condensation). This design preserves the temporal contiguity required by pre-trained models and provides inductive bias for efficient information aggregation and prediction.

Figure 2: MemoSight data sample illustrating compressed and foresight-token augmented context, and associated training labels and position IDs.
The joint supervised training objective optimizes standard next-token prediction for reasoning tokens, masks memory token loss, and applies an MTP loss for foresight tokens. A specialized attention mask enforces structural isolation for foresight predictions, strict intra-step causality, and compressed history during inter-step transitions.

Figure 3: Comparison of attention masking strategies, with MemoSight enforcing structural isolation for both compression and parallel prediction tokens.
Iterative Inference Pipeline
MemoSight’s inference alternates between “accelerate” and “compress” operations. Each reasoning step is accelerated with parallel prediction of future tokens via foresight tokens—speculative decoding drafts d-token lookaheads and commits verified predictions in a single pass. On completing a reasoning block, memory tokens are generated and raw reasoning tokens are evicted from the cache, with the subsequent steps conditioned solely on compressed memory tokens and prompt, maintaining contiguous PID for coherence and efficiency.
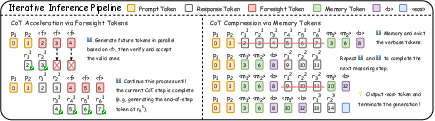
Figure 4: MemoSight inference cycle: parallel foresight token prediction and step-wise context compression, enabling cache eviction and fast reasoning.
Empirical Assessment
Comprehensive experiments on GSM8K, BBH, MMLU, and GPQA demonstrate that MemoSight reduces KV cache footprint by up to 66%, accelerates inference speed by 1.56×, and achieves accuracy within 2% of the upper-bound vanilla baseline. Post-hoc acceleration approaches (H2O, SepLLM) yield inferior speedup and memory reduction and fail to match MemoSight’s accuracy. Ablation confirms that position-aware alignment and constant compression ratio are critical for generalization and stable performance. Notably, aggressive compression (up to 8×) maintains competitive accuracy, but further compression degrades retention capacity.
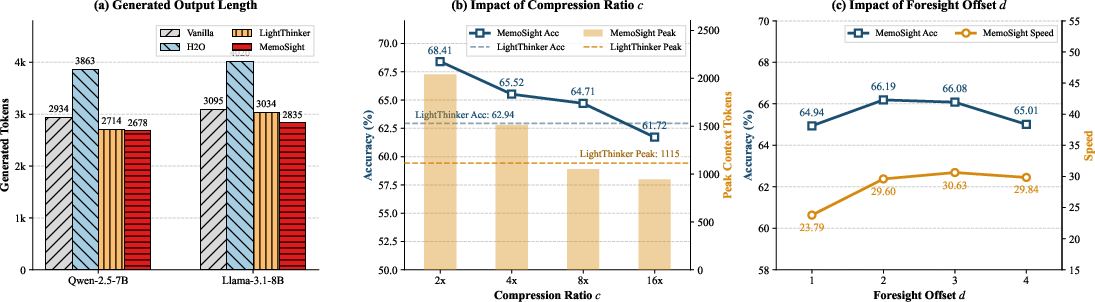
Figure 5: Efficiency analysis showing MemoSight’s lowest generated token count and optimal accuracy-memory trade-off across compression and MTP offset parameters.
Time and memory efficiency evaluation reveals MemoSight maintains bounded peak token usage across varying sequence lengths, with significant speed improvements for long contexts. Loss weight tuning indicates that predominant weighting on the standard LM loss (λ=0.7) optimizes accuracy, while excessive MTP loss weight (λ=0.5) disrupts reasoning stability.
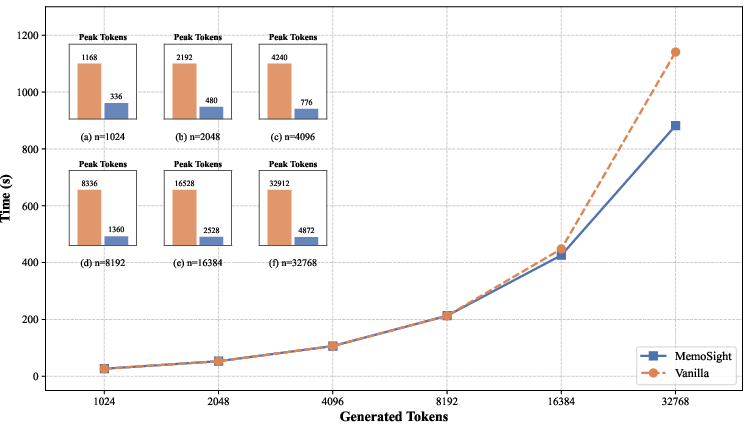
Figure 6: Inference time and memory footprint as a function of generated sequence length; MemoSight achieves sustainable context compression and scalable throughput.
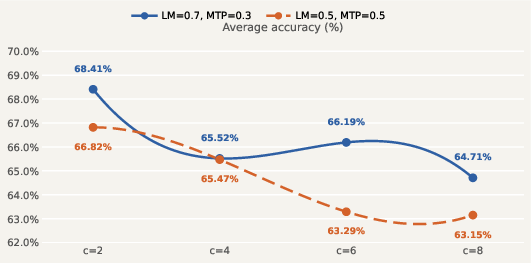
Figure 7: Loss weight configuration impact on accuracy under varying compression ratios, highlighting the benefit of moderate planning signal.
Comparison and Ablation
Ablation studies demonstrate substantial performance degradation when removing position-aware alignment, constant compression ratio, or foresight-token MTP. Traditional MTP variants requiring additional architectural heads result in parameter overhead and fail to complement context compression, whereas special-token-based MTP in MemoSight facilitates joint optimization and reasoning stability.
Interpretability and Reasoning Trajectory
Case studies highlight MemoSight’s robust step-wise intermediate state preservation, mitigating error propagation and enabling consistent logical progression across multi-step reasoning tasks.
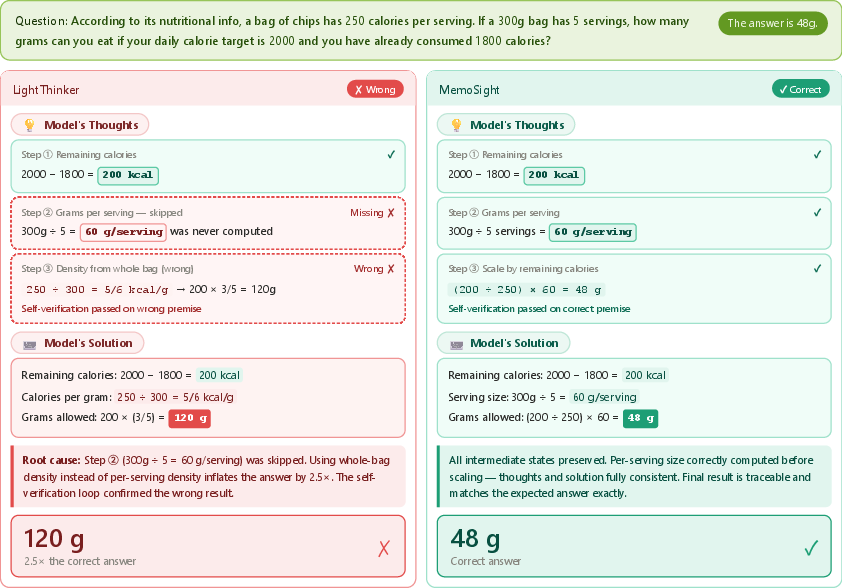
Figure 8: Comparison of reasoning trajectories: MemoSight preserves intermediate calculations while LightThinker exhibits error cascades.
Practical and Theoretical Implications
MemoSight’s unified framework delivers improved efficiency-performance tradeoffs, offering practical deployment benefits for LLMs in constrained environments and scalable interactive contexts. The token-centric, data-driven architecture supports integration with wide model classes and incentivizes deeper exploration of hybrid compression-planning inductive biases. Theoretical implications concern the interplay between token-level memory condensation and parallel prediction—MemoSight suggests that architectural modularity is not a prerequisite for enhanced efficiency, but position-aware organization and task-centric alignment are critical.
Future work should focus on dynamic adaptation of compression ratios and foresight offsets, hybrid integration with latent reasoning methods, and exploration of fine-grained token selection strategies for general-purpose memory and planning representations. Expanding the approach to multi-modal and cross-domain reasoning stands to further improve real-world applicability.
Conclusion
MemoSight provides a principled, unified solution for efficient CoT reasoning in LLMs, jointly optimizing context compression and multi-token prediction via special tokens and position-aware alignment. This approach achieves substantial reductions in memory usage and inference time without architectural changes, maintaining high accuracy and enabling scalable deployment for complex reasoning tasks (2604.14889).