Published 16 Apr 2026 in stat.ML and cs.LG | (2604.14621v1)
Abstract: Conformal prediction (CP) has attracted broad attention as a simple and flexible framework for uncertainty quantification through prediction sets. In this work, we study how to deploy CP under differential privacy (DP) in a statistically efficient manner. We first introduce differential CP, a non-splitting conformal procedure that avoids the efficiency loss caused by data splitting and serves as a bridge between oracle CP and private conformal inference. By exploiting the stability properties of DP mechanisms, differential CP establishes a direct connection to oracle CP and inherits corresponding validity behavior. Building on this idea, we develop Differentially Private Conformal Prediction (DPCP), a fully private procedure that combines DP model training with a private quantile mechanism for calibration. We establish the end-to-end privacy guarantee of DPCP and investigate its coverage properties under additional regularity conditions. We further study the efficiency of both differential CP and DPCP under empirical risk minimization and general regression models, showing that DPCP can produce tighter prediction sets than existing private split conformal approaches under the same privacy budget. Numerical experiments on synthetic and real datasets demonstrate the practical effectiveness of the proposed methods.
The paper presents a novel DPCP framework that integrates conformal calibration with differential privacy to achieve finite-sample coverage while preserving privacy.
It introduces a two-level method, combining DP-trained models with a differentially private quantile calibration using an exponential mechanism for efficient uncertainty quantification.
Empirical results show that DPCP produces shorter prediction intervals and maintains nominal coverage compared to traditional private split conformal prediction methods.
Differentially Private Conformal Prediction: A Formal Synthesis of Distribution-Free Uncertainty Quantification and Privacy Guarantees
Introduction and Problem Formulation
The intersection of distribution-free predictive inference and formal privacy guarantees presents unique statistical and algorithmic challenges. "Differentially Private Conformal Prediction" (2604.14621) develops a rigorous framework for constructing conformal prediction (CP) sets under differential privacy (DP), termed Differentially Private Conformal Prediction (DPCP). The methodological core is an overview of conformal calibration with algorithmic stability due to DP mechanisms, yielding prediction sets that retain finite-sample coverage while satisfying stringent privacy criteria.
The paper problematizes the incompatibility between classic CP—which produces predictive sets with marginal frequentist validity under exchangeability—and DP, whose randomness and sensitivity constraints disrupt the conditional exchangeability pivotal for CP's guarantees. Prior approaches, especially split conformal frameworks combined with private quantile mechanisms [e.g., Angelopoulos et al., 2022], incur significant efficiency and coverage penalties under strong privacy regimes. The proposed DPCP framework addresses these drawbacks both theoretically and empirically.
Methodological Innovations
The authors introduce a two-level construction:
Differential CP (dCP): A bridge between non-private oracle CP and end-to-end private procedures. dCP eschews data splitting; instead, it relies on fitting a DP model on the full sample and directly calibrating prediction sets via the DP mechanism's stability on adjacent datasets (i.e., datasets differing in one entry).
Differentially Private CP (DPCP): Extends dCP to achieve end-to-end DP. Both the fitted model and the calibration quantile are privatized. Model training is performed by a general ε1-DP algorithm, and quantile calibration is implemented via a carefully constructed differentially private exponential mechanism, utilizing the remaining privacy budget ε2.
A mathematically explicit correction for the quantile level is derived: rather than classic split-CP’s O(logn/n) adjustment, DPCP requires only a sharp 2/(nε) correction to the nominal coverage level, reflecting the improved sample and privacy efficiency. This manifests in the formal construction of the DPCP prediction set:
Cαdp(Xn+1)={y:R((Xn+1,y),μn)≤q^}
where μn is the DP-trained model and q^ is the output of the DP quantile selector.
Theoretical Guarantees
A centerpiece of the paper is the derivation of tight formal guarantees for both privacy and coverage.
Privacy: The overall procedure satisfies (ε1+ε2,δ)-DP by composition.
Coverage: Under mild regularity/local identifiability-type conditions and suitable (data-dependent) calibration, the marginal coverage level of the DPCP sets meets the nominal 1−α target. Notably, the authors also establish conditional coverage with respect to both model randomness and private calibration randomness, under explicit assumptions quantifying the interaction between private thresholding and the underlying exchangeable structure.
The results emphasize that the major loss in split-CP+DP frameworks arises from sample inefficiency: data splitting amplifies the impact of DP noise, particularly when privacy budgets are small.
Empirical Validation
Synthetic and real data experiments—spanning low to high sample sizes and varying privacy constraints—evaluate coverage and efficiency.
The figures below summarize key empirical advancements.
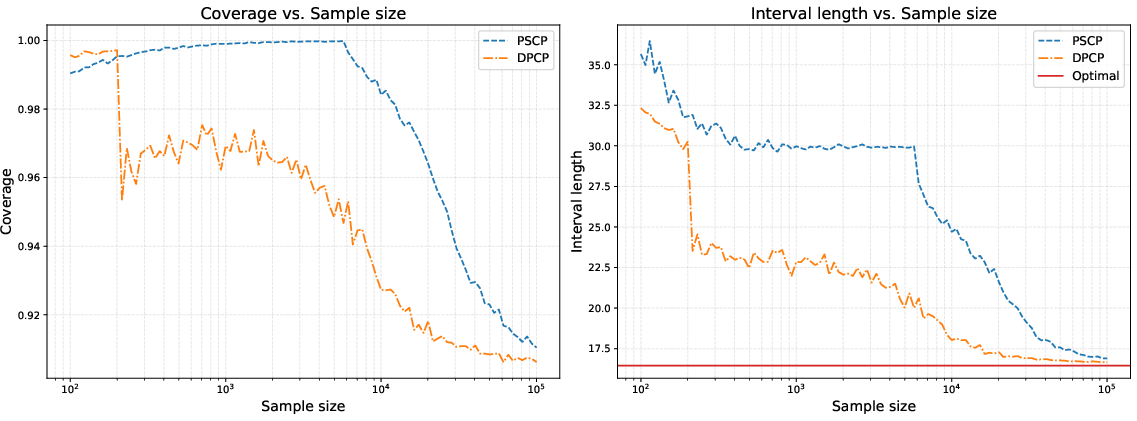
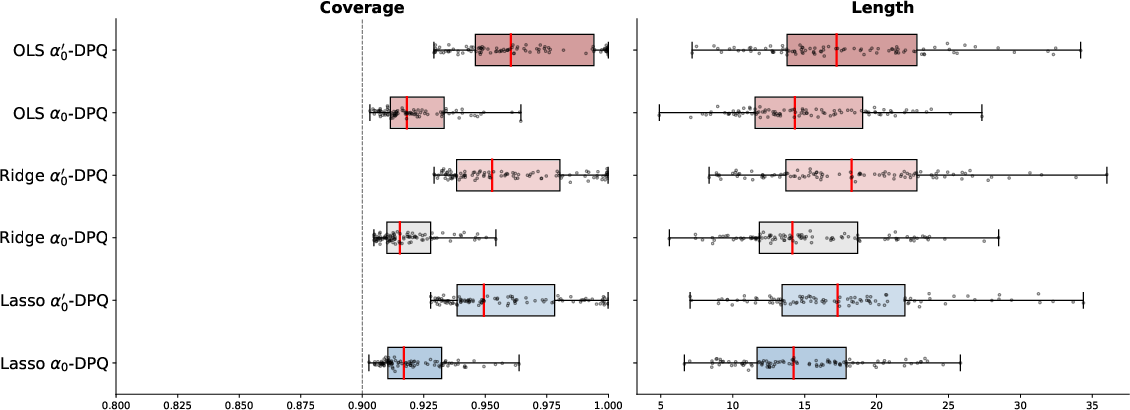
Figure 1: Coverage and length behavior as a function of sample size (n) at fixed ε20, ε21.
DPCP consistently achieves nominal coverage (left panel) while providing noticeably shorter prediction intervals (right panel) than private split CP baselines, especially in low to moderate sample sizes. The conservativeness of prior-private split CP (PSCP) is visible, demonstrating DPCP's statistical efficiency advantage.
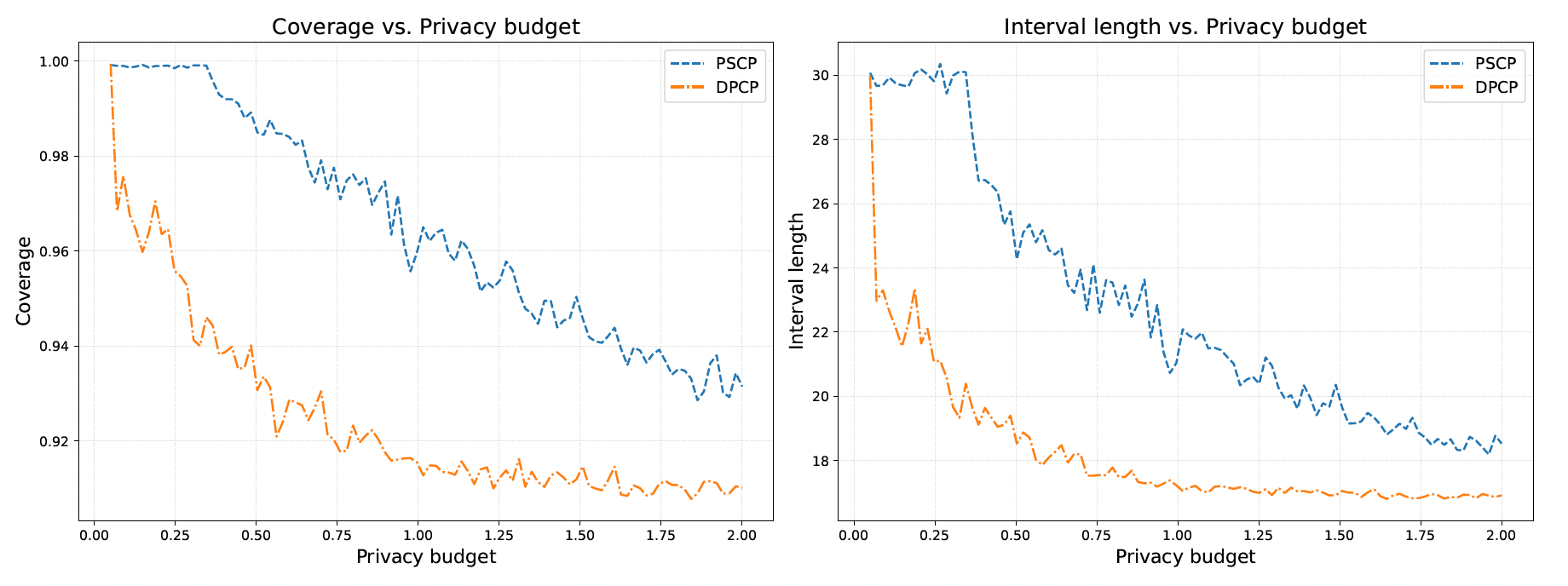
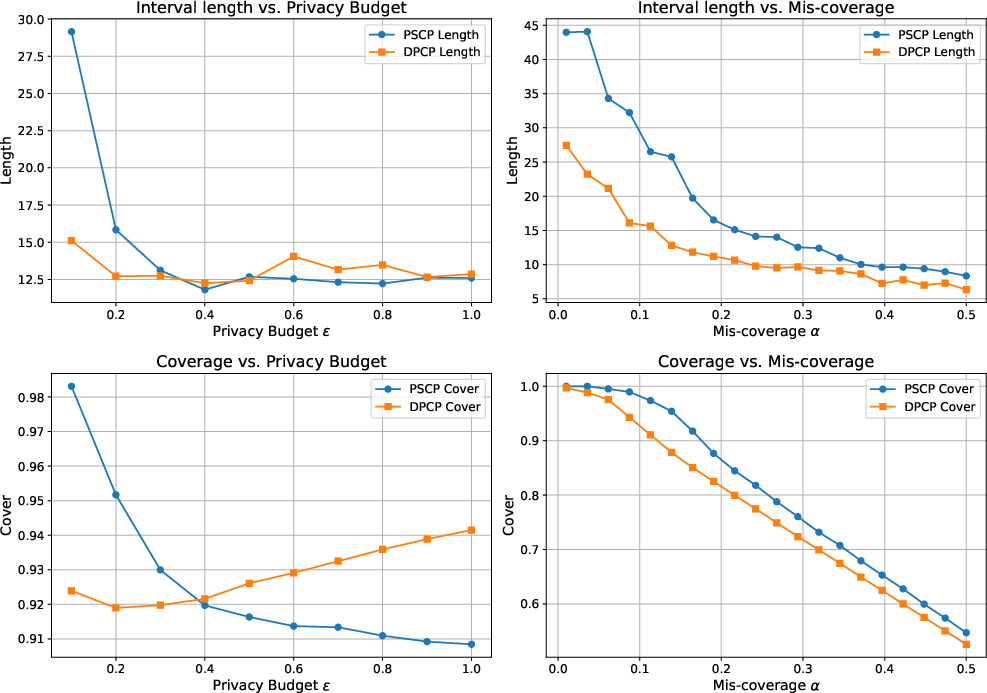
Figure 2: Coverage and length as a function of privacy budget ε22, splitting privacy budget between model training and quantile estimation; ε23, ε24.
As privacy constraints tighten (ε25 decreases), both methods see widening intervals and slightly more conservative coverage. However, DPCP intervals remain substantially shorter for all practical privacy levels, with less overconservatism even as ε26.
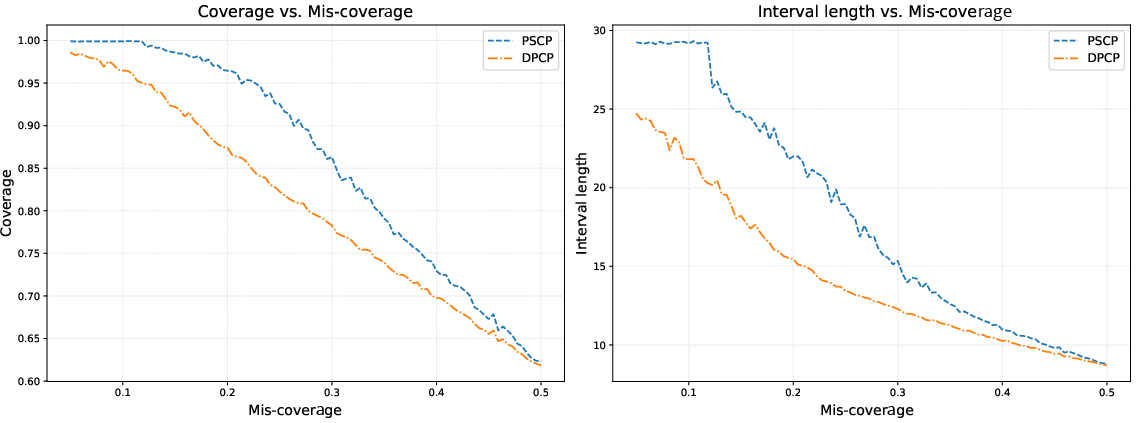
Figure 3: Coverage and interval length versus the miscoverage level ε27, with fixed privacy budget ε28, ε29.
DPCP tracks the nominal coverage level robustly across a wide range of O(logn/n)0, avoiding the dramatic overcoverage (and associated inefficiency) prevalent in PSCP.
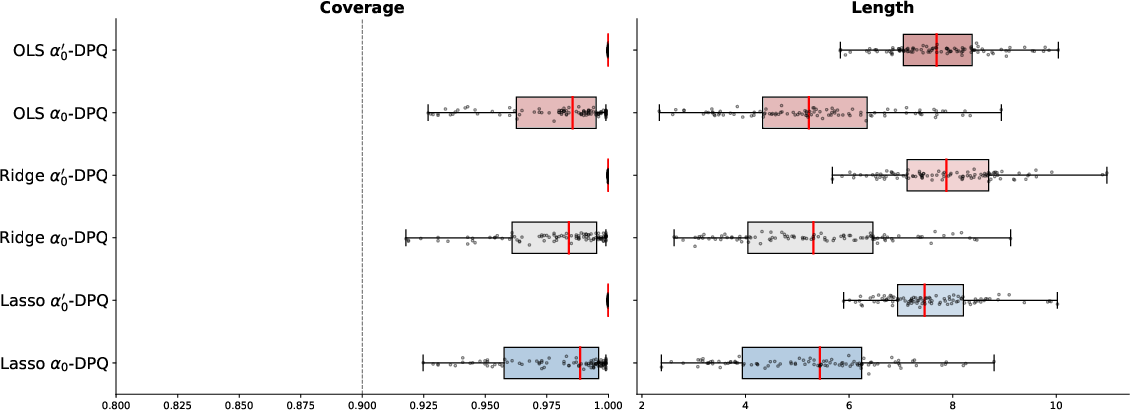
Figure 4: Marginal coverage and length for private prediction intervals on real datasets: upper—communities and crime (sample size 1994); lower—power consumption (sample size 52416).
On real datasets, DPCP achieves substantial gains in interval length without sacrificing empirical coverage.
Figure 5: Private prediction interval length and coverage as functions of privacy budget (O(logn/n)1) (left) and miscoverage (O(logn/n)2) (right) on the power consumption data.
DPCP is markedly less sensitive to privacy and coverage level variations, exhibiting more stable and less inflated intervals.
Analysis and Practical Implications
The theoretical efficiency analysis demonstrates that, under mild regularity, the Lebesgue measure of the symmetric set difference between DPCP and oracle intervals decays at a rate governed by the privacy split and sample size, i.e., O(logn/n)3. This convergence ensures that as O(logn/n)4 increases and the privacy loss per individual decreases (O(logn/n)5 increases), DPCP rapidly approaches the efficiency of non-private oracle CP.
The practical import is profound in privacy-sensitive applications (e.g., health, finance, criminal justice) where data owners are unwilling to sacrifice privacy for uncertainty quantification. The DPCP construction enables valid, efficient uncertainty estimates without access to the raw data or requiring generative modeling assumptions.
Implications for Future AI Uncertainty Quantification
The compositional structure of DPCP accommodates arbitrary DP learning mechanisms. Thus, DPCP can be applied to complex function classes, including linear models, deep neural networks (via DP-SGD), and Bayesian predictors (via DP posterior sampling). The authors note the natural extension of this framework to weighted CP, distribution shift, and more, provided an oracle conformal procedure is available.
Further implications:
Sharpness of Correction: The explicit quantile correction offers clear guidance for privacy-budget allocation between model and quantile phases, suggesting optimal allocations for given privacy-level targets.
Conditional Validity: By leveraging local/conditional arguments, it is possible to extend DPCP to settings with non-exchangeable data, adaptive data analysis, or streaming scenarios.
Extension to Advanced DP Notions: DPCP admits adaptation to concentrated, R\'enyi, and Gaussian DP, potentially improving oracle-to-private approximation fidelity.
Conclusion
This work delivers a foundational framework for conformal prediction under differential privacy, characterizing the statistical and privacy cost of uncertainty quantification in private learning. DPCP achieves formal, end-to-end DP with provably valid coverage and improved statistical efficiency relative to existing approaches. The results are of direct consequence for reliable uncertainty quantification in privacy-critical AI deployments and offer a blueprint for further algorithmic and theoretical advances in private distribution-free inference.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.