- The paper introduces an adaptive, semantically aware patch compression technique (SEPatch3D) that balances computational speed and detection accuracy in sparse multi-view 3D object detection.
- It employs a Spatiotemporal-aware Patch Size Selection module along with Informative Patch Selection and Cross-Granularity Feature Enhancement to maintain fine detail and semantic consistency.
- Empirical evaluations on large-scale benchmarks like nuScenes and Argoverse 2 show up to 57% latency reduction with less than 0.5% accuracy drop, validating its compute-accuracy trade-off.
Accelerating ViT-Based Sparse Multi-View 3D Object Detectors via Adaptive Patch Compression
Motivation and Limitations of Token Compression in Sparse 3D Detection
ViT-based architectures have become central in sparse multi-view 3D object detection due to their representational capacity and natural compatibility with query-based detection schemes. However, the dense token representation intrinsic to ViTs incurs high computational overhead during inference, particularly problematic for real-time applications such as autonomous driving. Token compression strategies—pruning, merging, and patch size enlargement—have been explored to mitigate this, yet each carries deficiencies that are exacerbated in the 3D detection context. Token pruning can discard semantically relevant background information, which is critical for hard negative mining (Figure 1), while token merging disrupts contextual consistency, leading to semantic information loss. Patch size enlargement, although computationally attractive, sacrifices fine-grained cues vital for precise object localization when used naively (Figure 2).




Figure 1: Token pruning may remove background cues crucial for hard negatives, negatively affecting detection robustness.
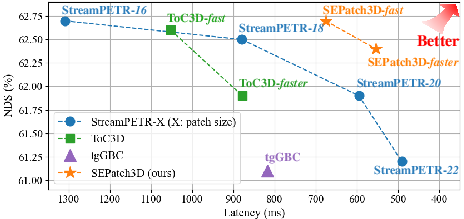
Figure 2: Increasing patch size in StreamPETR consistently reduces latency, but excessive enlargement causes severe accuracy drop. SEPatch3D-faster retains high accuracy with 57% latency reduction.
The SEPatch3D Framework: Dynamic and Semantically Aware Patch Compression
SEPatch3D introduces a framework that adaptively adjusts patch granularity in ViT-based backbones, guiding patch size selection using object-centric scene understanding. The approach uses a Spatiotemporal-aware Patch Size Selection (SPSS) module, which computes the average scene depth and its temporal variation from object queries, assigning small patches to near-object scenes and large patches to background-dominated scenes, thus balancing computational cost and necessary detail (Figure 3).
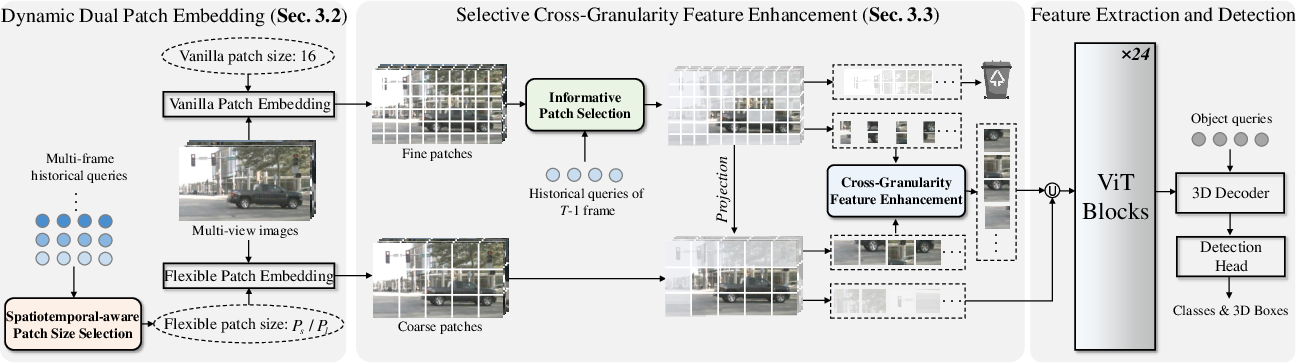
Figure 3: The SEPatch3D pipeline leverages dynamic dual patch embedding via SPSS, and uses IPS and CGFE to preserve salient semantics during aggressive token compression.
The framework incorporates two modules to mitigate fine-detail loss from coarse partitioning. The Informative Patch Selection (IPS) module evaluates patch “informativeness” via entropy measurements applied to features that have been temporally enhanced with motion-aligned query context, adaptively selecting regions above a data-driven threshold. The Cross-Granularity Feature Enhancement (CGFE) module then uses cross-attention from fine-grained to coarse patches, injecting local details critical for discrimination back into the compressed representation (Figure 4).
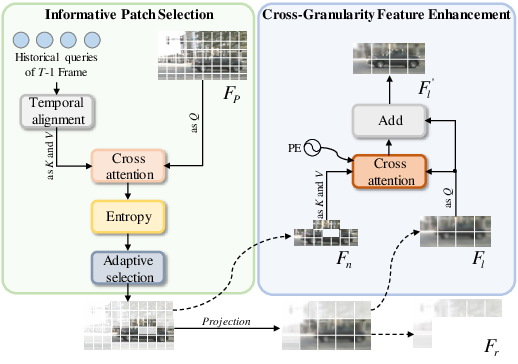
Figure 4: IPS identifies entropy-rich (informative) patches while CGFE fuses fine and coarse patches, enhancing semantic detail in selected regions.
Empirical Results Across Large-Scale Benchmarks
SEPatch3D demonstrates considerable acceleration and minimal accuracy degradation on the nuScenes and Argoverse 2 validation sets, evaluated against strong ViT-based baselines and SOTA approaches. For example, under high-resolution input (640×1600), SEPatch3D-faster achieves a 57% reduction in inference time and a nearly 50% reduction in backbone computation compared to StreamPETR, with less than 0.5% absolute drop in detection accuracy by NDS or mAP metrics (Table 1, illustrated in Figure 2). The architecture generalizes robustly across different ViT variants and sparse query-based detectors, making its improvements largely architecture-agnostic.
Qualitative analyses confirm that the IPS module robustly tracks informative regions (e.g., vehicles, pedestrians), and CGFE meaningfully amplifies local representation power within these regions (Figure 5). Additional ablations demonstrate that adaptive patch size selection sharply optimizes the compute-accuracy trade-off: fixed coarse partitioning increases efficiency but at a substantial loss in accuracy, while the addition of IPS and CGFE modules recovers nearly all accuracy with only a marginal parameter increase.

Figure 5: IPS selects informative regions in blue (foreground objects), CGFE amplifies feature responses corresponding to these patches.
Ablation studies confirm that two-level patch size selection is optimal; introducing more granular diversity leads to head specialization breakdown and accuracy degradation, supporting the use of a restricted set of patch sizes for adaptive selection (Figure 6).
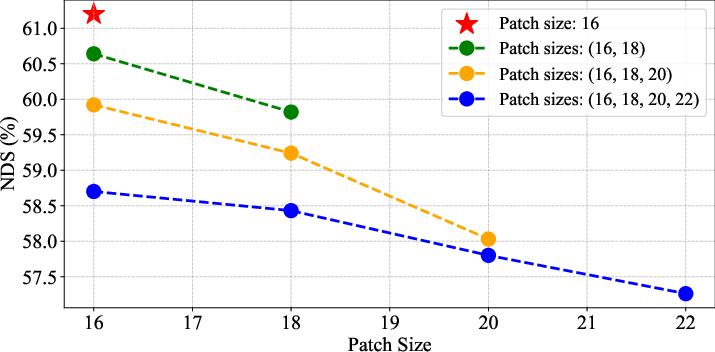
Figure 6: Higher patch size diversity leads to performance degradation, motivating SEPatch3D’s design choice of two patch sizes.
Budget-Aware and Context-Adaptive Design
A polynomial regression-based budget-aware analysis (Figure 7) enables efficient traversal of the patch size/accuracy/runtime trade-off space without exhaustive retraining. This provides practical value for system deployment, where resource and latency budgets are hardware-specific.
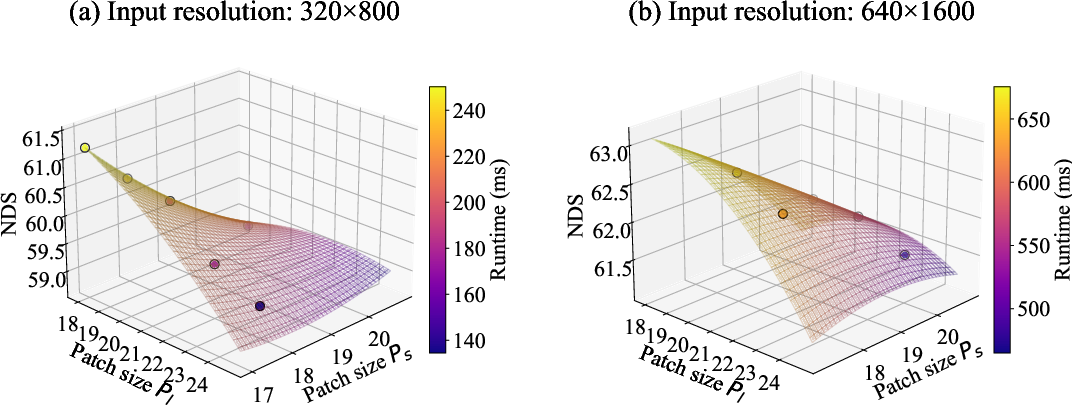
Figure 7: Surface plot linking accuracy, latency, and patch sizes, supporting optimal configuration search under compute constraints.
Further, SEPatch3D leverages a robust, dataset-agnostic threshold (θ) for object depth distribution in patch size assignment, supporting generalization across different driving datasets and scenarios (Figure 8).
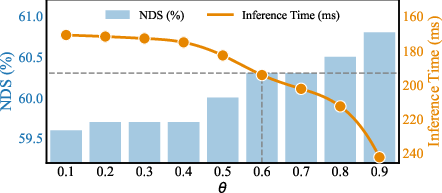
Figure 8: Threshold θ provides cost/accuracy flexibility; moderate values deliver the optimal trade-off.
Practical and Theoretical Implications
SEPatch3D’s methodology overcomes limitations present in both 2D token pruning and prior 3D detection token compression approaches. By strictly avoiding the pruning of background regions, the framework maintains a low false-positive rate on hard negatives, substantiated by improved performance metrics over ablation and prior art. Its spatiotemporal control mechanism, applied at the patch embedding stage, acts orthogonally to classical attention pruning and merging, and could potentially be extended to various query-based spatiotemporal scene understanding tasks (e.g., BEV occupancy, physical world modeling).
On the theoretical side, the entropy-based selection supports more meaningful adaptivity in stiff, shallow ViT layers compared to learned or attention-weight rankings, which lack sufficient abstraction in these contexts. The design also highlights the importance of stable temporal dynamics in patch assignment—sudden changes degrade performance—which corresponds with requirements in other real-time perception domains.
Future Directions
Key future avenues include fully learnable patch size selection, which could decouple the system from hand-tuned depth thresholds and allow for context-dependent granularity learning. Additionally, integration with quantization or binarization techniques, as well as application to broader spatiotemporal transformer-based reasoning, may yield further improvements in efficiency and generalization. Extensions to occupancy prediction and world modeling are natural next steps given the architectural abstraction employed here.
Conclusion
SEPatch3D delivers an adaptive, entropy- and spatiotemporally driven alternative to standard token compression for ViT-based sparse multi-view 3D detectors. It demonstrates substantial inference acceleration (up to 57%) while incurring negligible decreases in detection quality under diverse, large-scale datasets. This approach both expands practical deployment possibilities for 3D perception systems and informs principled adaptive token compression research for ViTs in dynamic visual contexts.

