- The paper introduces CoCoDiff, which co-optimizes communication scheduling and application semantics to address performance bottlenecks in distributed Diffusion Transformer inference.
- It details novel mechanisms including TAPA, V-First Scheduling, and V-Major Selective Communication that leverage hardware heterogeneity and temporal redundancy.
- Empirical results on models like Qwen-Image demonstrate an average speedup of 3.6× and up to 8.4× at high-resolution, while preserving output quality.
Introduction and Motivation
Diffusion Transformers (DiTs) have become standard in high-resolution generative modeling, both in industrial and scientific domains. Scaling DiT inference to larger resolutions and models necessitates distributed multi-GPU execution. Ulysses sequence parallelism is the de facto approach for distributing the token sequence among compute devices; however, this paradigm introduces a critical performance bottleneck: frequent and high-volume all-to-all collective communications for the Q/K/V tensors in attention layers. Profiling large models such as Qwen-Image (20B) on the Aurora supercomputer reveals that all-to-all collectives can account for 64–96% of total inference time, especially as image resolution increases.
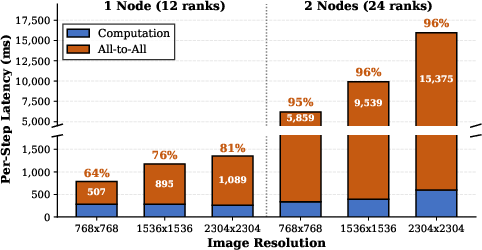
Figure 1: Communication overhead in Qwen-Image (20B) inference on Aurora, showing all-to-all collectives dominate inference time as resolution scales.
Conventional strategies to overlap communication with computation are hampered by tight intra-layer and inter-layer dependencies, asynchronous compute/comm progression mismatches, and constrained memory hierarchies. These challenges motivate the design of CoCoDiff, a distributed inference engine for DiTs that explicitly co-optimizes communication scheduling and application semantics to minimize latency under Ulysses sequence parallelism (2604.14561).
CoCoDiff Design: Principles and Mechanisms
CoCoDiff’s approach is predicated on two domain-specific insights:
- QKV Asymmetry in Attention: Only the value projection (V) is a pure linear mapping, while the queries (Q) and keys (K) incur extra computational steps (normalization and rotary position encoding). This enables early initiation and possible overlapping of V communication with Q/K computation.
- Temporal Redundancy in Diffusion Denoising: Consecutive denoising steps often yield similar intermediate representations, creating opportunities for selective communication—only transmitting those projections that have significantly changed.
Building on these, CoCoDiff implements three core mechanisms:
Tile-Aware Parallel All-to-All (TAPA)
Standard collective libraries fail to exploit the non-uniform, hierarchical bandwidths of contemporary supercomputers (e.g., Intel Aurora’s tile, GPU, and interconnect bandwidths). TAPA decomposes the all-to-all into two explicit phases: (i) intra-GPU (high bandwidth, fully parallel tile exchanges), and (ii) inter-GPU (lower bandwidth, parallel group communications aligned with the physical topology).
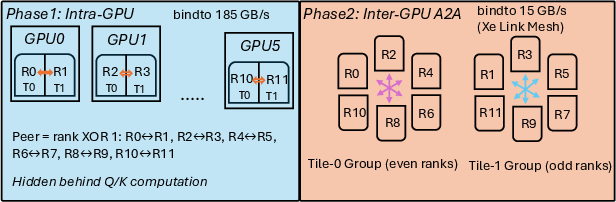
Figure 2: Tile-aware parallel all-to-all: Phase separation exploits Aurora’s bandwidth hierarchy for maximal throughput.
V-First Scheduling
CoCoDiff leverages the QKV computation asymmetry to commence communication of V as soon as its projection is complete, overlapping V’s Phase 1 communication (intra-GPU) with the subsequent Q/K normalization and RoPE operations. The scheduling is proved beneficial whenever the Q/K computation exceeds the intra-GPU comm time—a property that holds across current DiT architectures and working batch sizes.
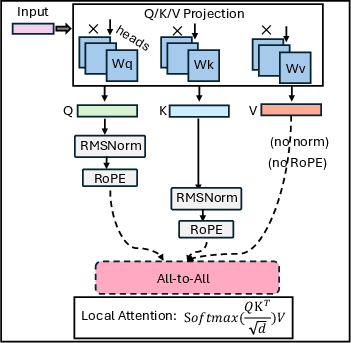
Figure 3: QKV processing in attention; only Q/K undergo extra normalization and RoPE.
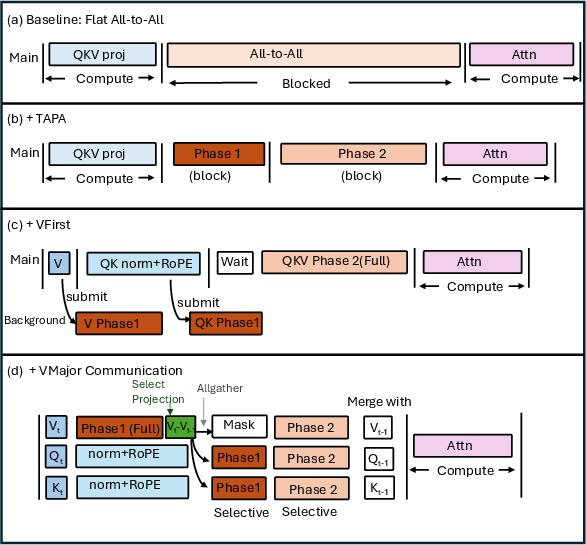
Figure 4: Execution timeline comparison—(c) V-first scheduling allows hiding of Phase~1 comm within Q/K’s normalization and RoPE.
V-Major Selective Communication
Exploiting temporal redundancy, V-Major identifies stable tokens by comparing value projections sequentially across denoising steps. Only “active” projections (determined using the L1 norm difference and a dynamic cache ratio) are communicated in the inter-GPU phase; the rest are cached and reused. This selective strategy drastically reduces bandwidth requirements without introducing material accuracy regression.
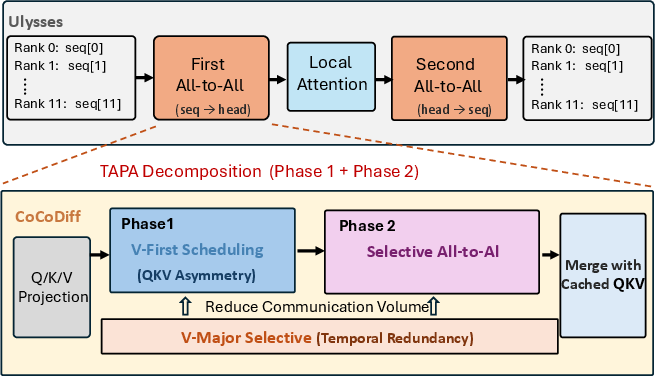
Figure 5: CoCoDiff overview, showing joint design of TAPA, V-First, and V-Major components.
Evaluation and Strong Numerical Results
Empirical analysis on the Aurora supercomputer using FLUX, SD3.5, Qwen-Image, and FLUX.2-dev models demonstrates that CoCoDiff outperforms flat baselines—delivering a mean end-to-end speedup of 3.6×, with a maximum of 8.4× at high-resolution, large-node configurations. TAPA alone yields 2.3×–2.5×, but the incremental benefit of V-First and V-Major only manifests at multi-node scales due to increased relative all-to-all overhead.
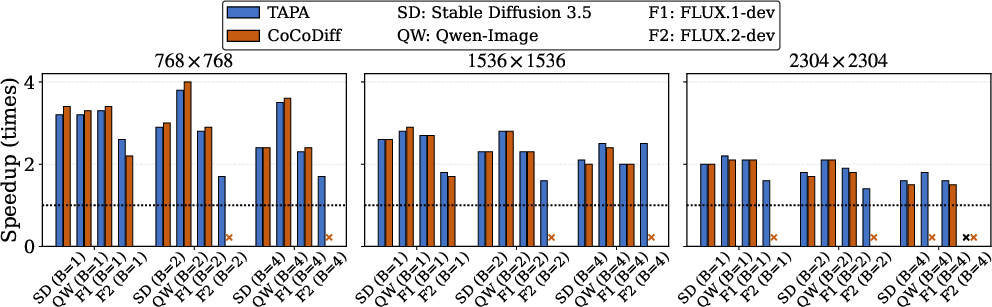
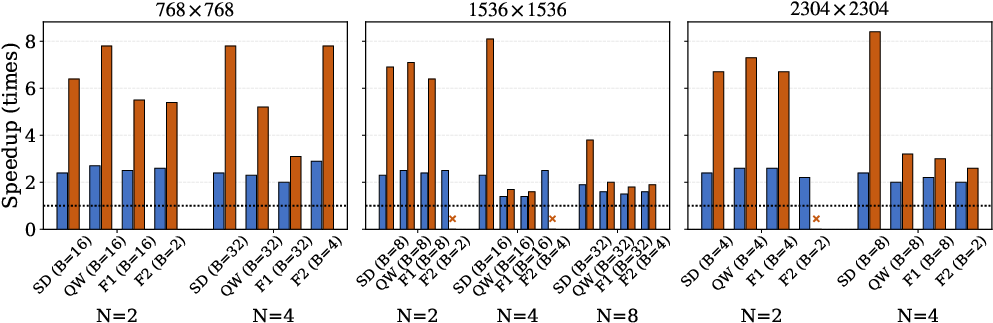
Figure 6: End-to-end speedups of TAPA and CoCoDiff for various models and resolutions. Substantial and scalable gains inherent to CoCoDiff’s selectivity at scale.
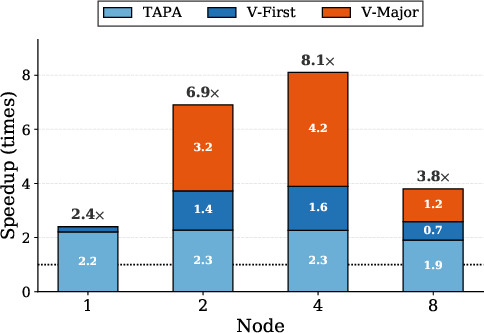
Figure 7: Component ablation on SD3.5: gain from each CoCoDiff subsystem (TAPA, V-First, V-Major) at different scales.
Crucially, the quality of model outputs (e.g., inpainting PSNR and SSIM) is statistically indistinguishable between the flat, TAPA, and CoCoDiff variants. This is further visualized on large-scale medical and scientific datasets, confirming negligible degradation from projection caching.

Figure 8: Example inpainting outputs from FLUX.1-dev, showing original, masked, restored, and error-mapped images.
Trade-off curves further illustrate that adaptive, time-varying cache ratios strictly outperform fixed policies in communication/quality space: aggressive caching can be safely scheduled in late denoising steps to maximize speedup without observable accuracy loss.
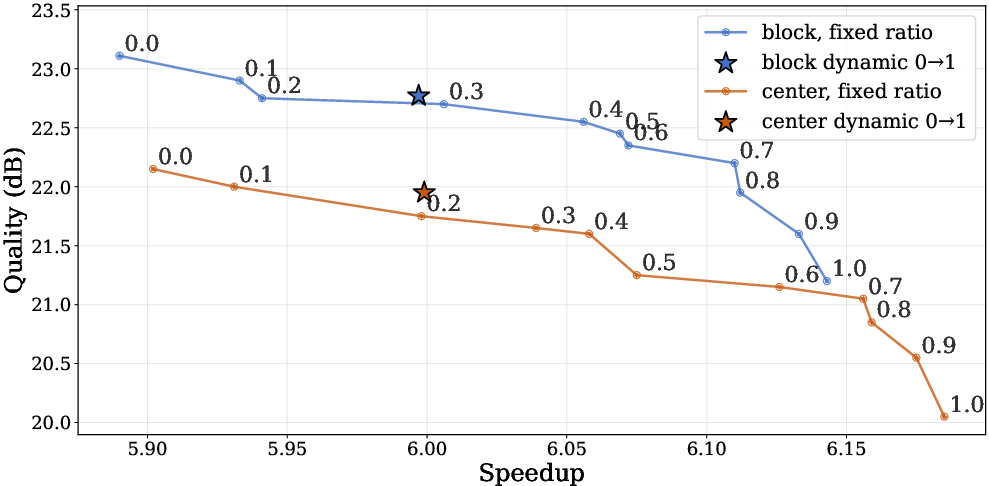
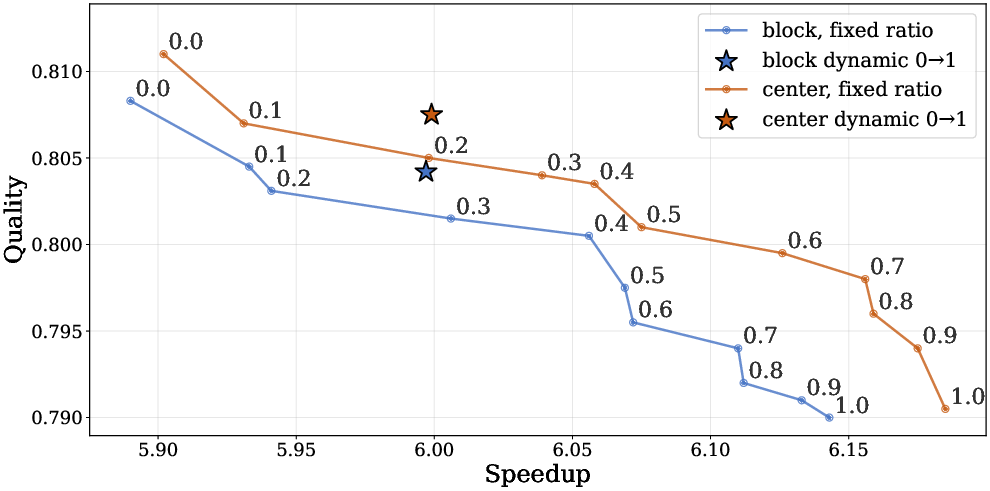
Figure 9: Inpainting quality (PSNR/SSIM) vs. speedup: time-varying cache ratio dominates the Pareto frontier.
Communication Microbenchmarks
TAPA’s hierarchical scheduling alone reduces all-to-all latency over oneCCL or flat baselines by up to 3.9× for large messages. Hierarchy-aligned execution consistently realizes higher observed effective bandwidths, especially as token sequence lengths scale quadratically with resolution.
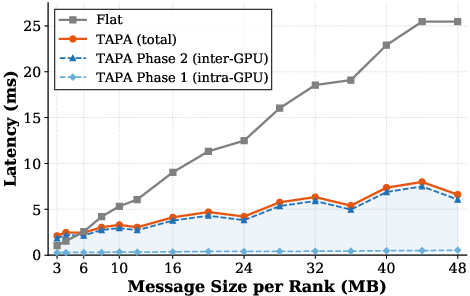
Figure 10: All-to-all communication latency per TAPA phase versus standard oneCCL/flat collectives on a 12-tile Aurora node.
Implications and Prospects
CoCoDiff marks a shift from protocol-agnostic collectives to application-semantics-aware distributed inference. Its explicit co-design of scheduling, selection, and hardware topology is particularly salient for hardware with significant interconnect heterogeneity; similar optimizations could be extended to other hierarchical-GPU clusters (e.g., upcoming datacenter fabrics with CXL, NVLink).
The selective caching principle, proven effective for inference, may generalize to other iterative, temporally coherent workloads (e.g., video diffusion, sequential RL). The demonstrated decoupling of runtime communication costs from full model size removes key barriers to scaling next-generation DiT-based synthesis and analysis pipelines in science and industry.
Theoretical Grounding
- Communication complexity under Ulysses/SP increases as O(N2), where N is the token sequence length; computation grows only linearly. CoCoDiff’s selective step transforms this to O(rN2), where r is the cache ratio, yielding order-of-magnitude theoretical bandwidth savings in late-stage denoising.
- The approach leverages cross-step representation similarity, orthogonal to single-device compute caching [ma2024deepcache, chen2024deltadit], yet uniquely adapted to reduce inter-device traffic under global layout constraints.
Conclusion
CoCoDiff establishes that coordinated enhancements across the communication stack and inference schedule can fundamentally shift the cost profiles of distributed diffusion model inference under sequence parallelism. The strong speedups, coupled with preserved output fidelity and hardware-agnostic adaptability, point to its viability as a foundational layer for future extreme-scale generative AI deployments.
Reference: (2604.14561)

