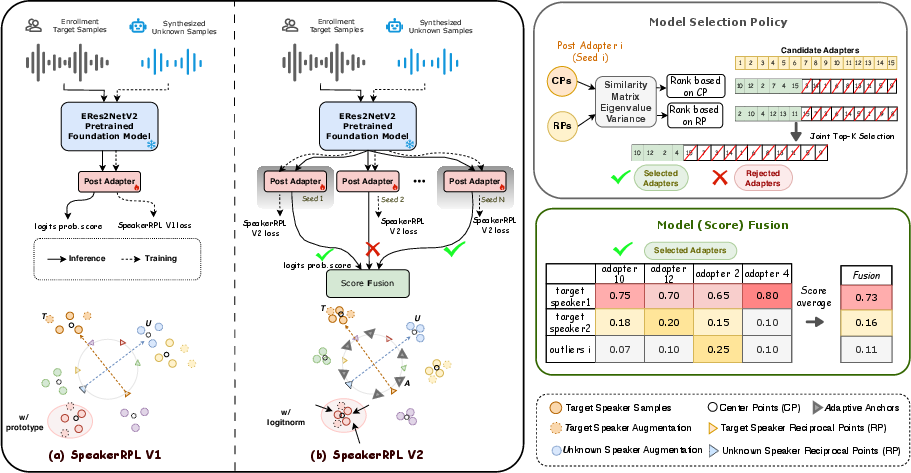
- The paper introduces a robust open-set speaker identification framework that integrates reciprocal points learning with adaptive anchors and LogitNorm.
- It employs an eigenvalue variance-based model fusion scheme to automatically select optimal candidate models, reducing randomness in few-shot tuning.
- Benchmark results on VoxCeleb2, 3D-Speaker, and ESD demonstrate substantial improvements in error rates and identification accuracy.
SpeakerRPL v2: Enhanced Few-shot Foundation Tuning and Model Fusion for Robust Open-set Speaker Identification
Introduction
SpeakerRPL v2 introduces a systematic advancement in open-set speaker identification by leveraging pretrained speaker foundation models and augmenting them with specialized few-shot adaptation techniques and robust model fusion. The core challenge addressed is to accurately distinguish between enrolled target speakers and unseen speakers, especially under resource constraints (limited enrollment) and high open-set variability. The proposed framework integrates reciprocal points learning, logit normalization, and adaptive anchor mechanisms to achieve discriminative and robust speaker embeddings. Furthermore, a model fusion approach based on automatic evaluation of candidate models via eigenvalue analysis is developed to mitigate the randomness of few-shot tuning and improve generalization.
SpeakerRPL v2 Architecture and Methodological Advances
SpeakerRPL v2 is built on the reciprocal points learning (RPL) paradigm, which models speakers in a reciprocal embedding space to maximize open-set discrimination. The methodology incorporates:
The loss functions are defined to optimize both target discrimination and margin constraints:
L=LLogitNorm+LRPL
where LRPL and LLogitNorm enforce reciprocal and normalized logit-based learning. Class extension with adaptive anchors allows dynamic modeling of extra-class space, improving identification performance on unknown speakers.
Model Fusion and Automatic Selection Policy
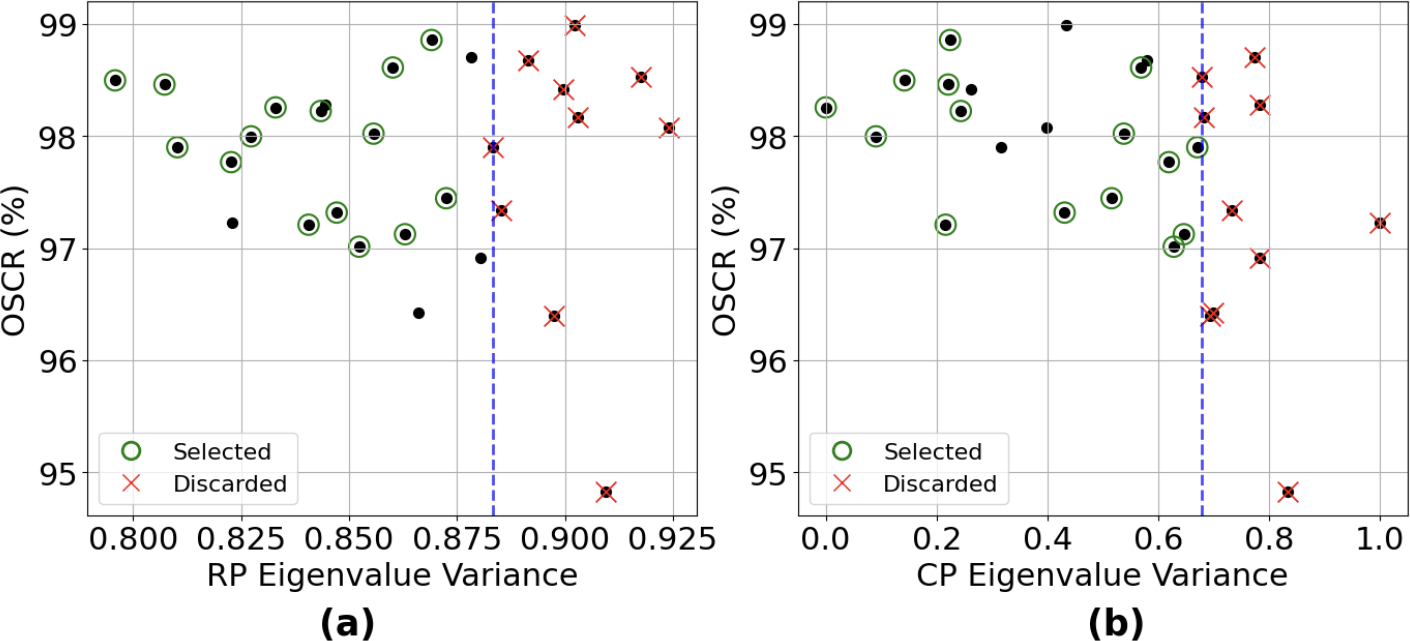
SpeakerRPL v2 addresses inherent instability in few-shot adaptation by introducing a score-level model fusion scheme. Multiple lightweight adapter models, trained under different random seeds, are aggregated. Crucially, the fusion is selectively performed using an automatic model selection policy based on eigenvalue variance analysis of central points (CPs) and reciprocal points (RPs):
This selection strategy ensures that only models with optimal internal representation structure are fused, reducing randomness and reinforcing identification performance.
Experimental Results and Empirical Analysis
Comprehensive evaluation is conducted across VoxCeleb2, 3D-Speaker, ESD, and the newly introduced Vox1-O*-like test sets. The SpeakerRPL v2 approach, especially with model fusion and adaptive anchors, consistently outperforms baseline and previous state-of-the-art methods across key metrics:
- Vox1-O*-like: SpeakerRPL v2 reduces EER from 1.28% to 0.09%—a substantial relative reduction (~93%).
- Multi-dataset Setting: Across VoxCeleb2, 3D-Speaker, and ESD, SpeakerRPL v2 achieves EER under 0.5%, minDCF ≤0.03, and OSCR/ACC above 98% for all scenarios.
- Scalability: Framework maintains stability and robustness with up to 40 simultaneous target speakers and thousands of unknown/trial utterances.
- Ablation: Increasing the number of adaptive anchors enhances performance, with gains saturating beyond 50 anchors.
The eigenvalue-based model selection directly correlates with improved OSCR and other open-set metrics, validating its efficacy in practical model fusion scenarios.
Theoretical and Practical Implications
The integration of reciprocal points, LogitNorm, and adaptive anchors establishes a robust foundation for open-set speaker modeling, particularly in limited-data scenarios and for applications in interactive agent systems that require reliable speaker identification. The automatic model selection policy offers a principled approach for stabilizing ensemble adaptation, which can generalize to broader few-shot recognition tasks beyond speaker identification.
Practically, SpeakerRPL v2 enables rapid deployment of customized speaker models with minimal computational resources, making it suitable for real-time interaction systems, security applications, and large-scale multi-speaker environments. The framework also bridges open-set identification and verification protocols, leveraging foundation models' strengths and making them more adaptable to dynamic open-set conditions.
Future Directions
Future developments are likely to extend the SpeakerRPL v2 framework to speaker diarization, emotion-adaptive identification, audio-visual fusion, and cross-lingual open-set setups. The combination of analytic model selection, dynamic anchor assignment, and robust ensemble adaptation may catalyze progress in many open-set recognition domains.
Conclusion
SpeakerRPL v2 offers a rigorous advancement in open-set speaker identification, marrying foundation model fine-tuning, adaptive anchor learning, and eigenvalue-guided model fusion. Strong empirical results across multiple benchmarks demonstrate robust improvements in accuracy, error rates, and stability, particularly in high-variability and large-target scenarios. The methodological innovations are theoretically sound, practically efficient, and set a solid basis for further research and deployment in open-set recognition tasks.