- The paper introduces CANVAS, a novel framework that uses explicit world-state modeling and persistent memory to enforce narrative continuity in multi-shot visual storyboarding.
- It integrates global story planning, memory-guided sequential generation, and QA-based candidate selection to maintain consistent character, background, and prop states.
- Quantitative benchmarks, including ContinuityEval and HardContinuityBench, show significant performance gains with up to +21.6% improvement in background continuity over baselines.
Continuity-Aware Narratives via Visual Agentic Storyboarding: An Expert Essay
Motivation and Challenges in Visual Storyboard Generation
Long-form visual storytelling demands stable narrative coherence across sequences of images: character identity must persist, environments should remain geometrically and visually consistent, and objects must evolve in accordance with narrative events. Existing generative models, including autoregressive and reference-based pipelines, produce plausible individual or short-range frames but lack mechanisms for explicit narrative continuity. Failure modes include character appearance drift, unstable environments on location recurrence, and incorrect object state tracking. These are exacerbated over long narrative spans, as shown by frequent inconsistencies in baselines such as AutoStudio and Story-Iter.
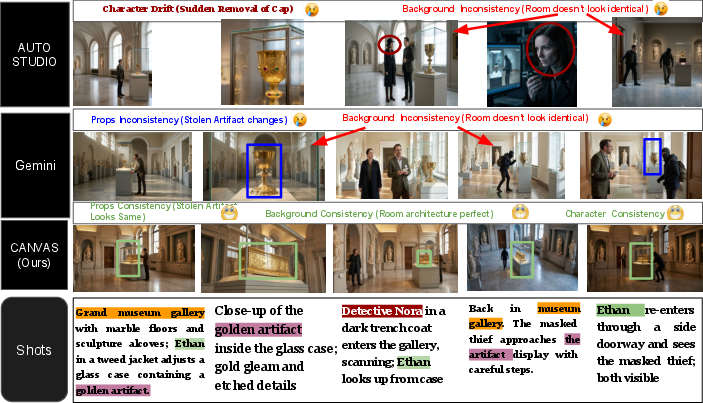
Figure 1: Visual storyboards generated by baseline methods and CANVAS for a multi-shot museum heist story illustrate CANVAS's superior persistence of character identity, artifact state, and spatial layout.
The absence of explicit world-state modeling prevents prior approaches from enforcing global constraints on physical continuity, logical object state, or spatial arrangement. This motivates the CANVAS framework, which formulates storyboard generation as structured world modeling with persistent memory for characters, background anchors, and object states.
CANVAS Architecture: World-State Modeling and Agentic Storyboarding
CANVAS operationalizes visual consistency by integrating three core processes:
- Global Story Planning: Shot descriptions are parsed to generate structured continuity plans—character appearance timelines, location clustering, and prop/object state trajectories—informing state transitions and constraints across the narrative.
- Memory-Guided Sequential Generation: Anchors for characters, environments, and objects are dynamically retrieved or initialized from persistent memory. The system conditions each generation step on these anchors, allowing continuity enforcement across shot boundaries, non-consecutive scenes, and object state changes.
- QA-Based Candidate Selection: Multiple candidate frames are generated per shot using the Gemini backbone. Each is evaluated through targeted VLM prompts on character, background, and prop continuity. The most consistent candidate is selected for further memory updates.
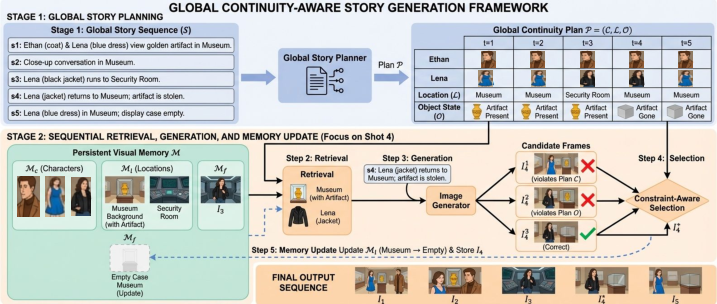
Figure 2: Overview of CANVAS pipeline with global planning, anchor retrieval, memory-guided generation, and QA-based candidate selection.
This multi-agent framework is architecturally agnostic and training-free, enabling compatibility with modern vision-language generative models. The explicit state tracking mechanism ensures that even in complex scenarios—e.g., recurring locations after temporal gaps, object disappearance and reappearance, and character attire changes—the generated storyboards maintain a logically evolving world.
ContinuityEval and HardContinuityBench: Fine-Grained Metrics and Benchmarking
CANVAS introduces two critical tools for systematic evaluation:
- ContinuityEval: A VLM-driven framework measuring continuity along three axes: character identity (face/clothing/body attributes), environment geometry (background structure across consecutive and non-consecutive shots), and prop-state recoverability. These metrics are strongly correlated with human judgements (Pearson r≈0.7 across dimensions).
- HardContinuityBench: Designed via GPT-based narratives, this benchmark stresses long-range continuity with frequent location recurrence, extended temporal gaps between reappearances, deliberate prop-state changes, and complex scene occlusions. It exposes weaknesses of short-range-conditioned generators and enables robust evaluation of continuity modeling.
Empirical Results: Strong Numerical Gains and Human Preference
CANVAS yields consistently superior quantitative performance. On ViStoryBench and ST-Bench, CANVAS achieves background continuity scores of $4.83$ (consecutive) and $4.83$ (non-consecutive), with character consistency averaging $4.30$—representing improvements of +21.6% (background), +9.6% (character), and +7.6% (prop) over the best baseline. HardContinuityBench further accentuates gains (+14.0% in long-range background consistency; character identity ↑11.8%).
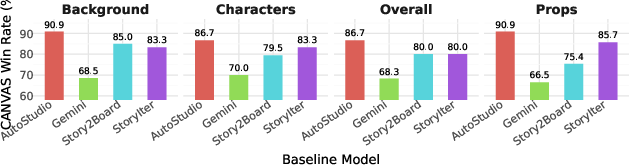
Figure 3: Human pairwise preference win-rates show CANVAS outperforming baselines in background, prop, and character continuity, as well as overall coherence.
Human annotators substantially prefer CANVAS-generated storyboards: up to 90.9% win-rate for background and prop consistency, and $4.83$0 for character and overall coherence vs. AutoStudio.
CANVAS maintains or improves prompt alignment, visual quality, and style diversity (see Table~\ref{tab:vistorybench_results}). Ablations show that canonical character anchors and background memory modules are critical—removal causes $4.83$1 identity degradation and $4.83$2 scene inconsistency (see Figure 4 and 5).

Figure 4: Train story ablation visualizes the effect of disabling background/character memory updates, resulting in spatial drift and identity mismatches.
Figure 5: Zoomed-in examples reinforce the essential role of persistent memory updates for visual continuity.
Ablation on prop-state tracking demonstrates that explicit object memory is necessary for maintaining logical narrative evolution, especially when objects are removed, carried, or reappear in altered states.

Figure 6: Qualitative ablation highlights failures in prop-state recoverability without explicit tracking in CANVAS.
Qualitative Analysis and Comparison with Baselines
When benchmarked against contemporary training-free methods (AutoStudio, Story2Board, Gemini-CT, Story-Iter), CANVAS produces storyboards that exhibit strong long-range coherence—consistent spatial layouts for recurring locations, stable object placements, and character identity persistence.

Figure 7: CANVAS preserves long-range coherence across multi-shot narratives with consistent character appearance, stable environments, and logical object-state transitions; baselines suffer identity drift and layout inconsistencies.
Qualitative comparison of cross-shot continuity with and without background planning illustrates structured planning’s necessity for spatial canonicalization and prop forecasting (Figure 8).




Figure 8: Structured background planning in CANVAS ensures environment and prop continuity across non-consecutive shots, avoiding spatial drift.
Implications, Limitations, and Future Directions
Practically, CANVAS establishes new standards in multi-shot visual storytelling with agentic consistency. This continuity-aware generation is critical for downstream tasks—automated movie generation, coherent video synthesis, and interactive narrative systems—where logical preservation of world-state is essential. The explicitly modeled state space could be combined with editable interactive pipelines and used for controllable narrative editing.
Theoretically, CANVAS advances the field by demonstrating the necessity and effectiveness of explicit world modeling for causally structured visual narratives. Future work could extend the framework to fine-grained physical interactions, complex motion dynamics, and larger-scale multi-agent reasoning. Interactive human-in-the-loop dialogue systems could be leveraged for real-time continuity edits and personalized storyline development.
Limitations include dependence on robust entity extraction from text, computational overhead for multi-candidate QA selection, and restrictions in modeling ambiguous narratives. HardContinuityBench remains limited in scale but is effective for exposing continuity weaknesses.
Conclusion
CANVAS presents a rigorously architected, training-free storyboard generation framework grounded in explicit world-state modeling and persistent memory. It outperforms contemporary baselines in both numerical continuity metrics and human preference, addressing longstanding challenges in coherent long-form visual storytelling. The methodology and benchmarks set a new trajectory for narrative-aware generative modeling and open avenues for interactive and controllable multi-shot generation in advanced AI systems.

