- The paper shows that linear probe accuracy scales logarithmically with model size, achieving around a 5% AUROC improvement per 10× increase in parameters.
- It demonstrates that single-layer probes are brittle due to non-universal layer localization, while multi-layer ensembling via stacking logistic regression significantly improves detection performance.
- The geometric analysis reveals that deception representations gradually rotate across layers, validating the use of ensembling as a robust mechanism for detecting explicit deception.
Linear Probe Accuracy Scaling and Multi-Layer Ensembling for Deception Detection
Overview
The paper "Linear Probe Accuracy Scales with Model Size and Benefits from Multi-Layer Ensembling" (2604.13386) investigates how linear probes can detect deception-related activations in LLMs, with an emphasis on scaling trends and methodological robustness. The authors systematically analyze probe performance across twelve open-weight models (spanning Llama, Qwen, Mistral/Mixtral) and five deception tasks drawn from the Liars' Bench benchmark. The study demonstrates: (i) probe accuracy strongly scales with model size; (ii) single-layer probes suffer brittle performance due to non-universal layer localization of deceptive directions; (iii) multi-layer ensembling, especially stacking over 5 layers using logistic regression, yields strong improvements (up to +78% AUROC) in scenarios where single-layer methods fail. Through geometric analysis, it is shown that deception is encoded as a gradually-rotating direction in activation space, validating ensembling as a principled solution.
The central result is a robust log-linear scaling relationship between model parameter count and probe AUROC: approximately 5% AUROC improvement per 10× increase in parameters (R=0.81, p<0.001, n=60 model-task pairs). Larger models (e.g., Llama-70B, Qwen-72B) clearly develop more linearly accessible deception representations. Task-specific scaling is pronounced: explicit deception tasks (Convincing Game, Instructed Deception) scale most rapidly, reaching near-ceiling AUROC in frontier models, while implicit deception tasks (Harm-Pressure Choice/Knowledge) remain challenging.
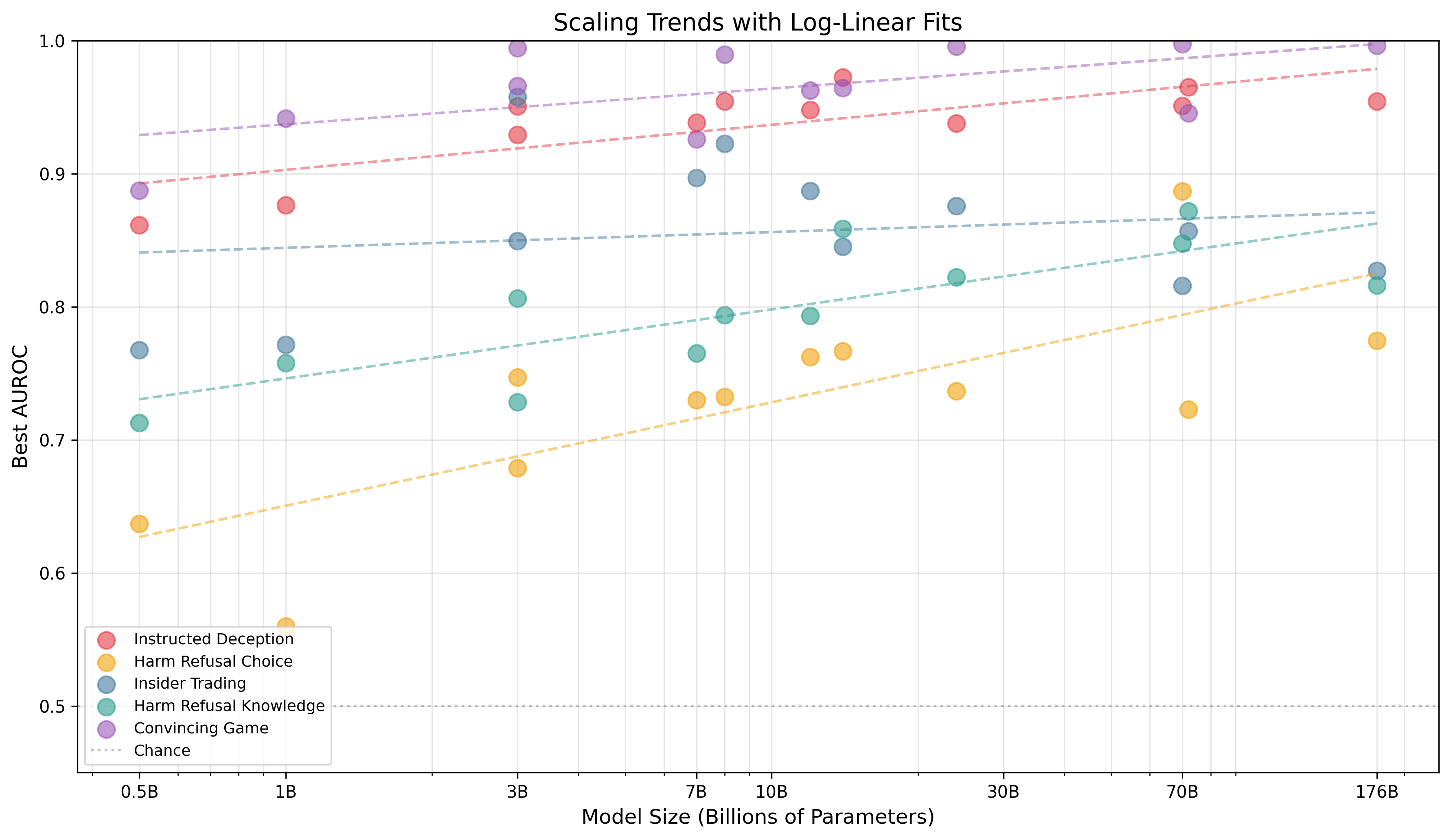
Figure 1: Log-linear scaling of probe AUROC: deception representations become more linearly accessible with increased model size, showing approximately 5% AUROC gain per 10× parameters.
Model family effects are evident—Llama outperforms on Insider Trading and Convincing Game, while Qwen exhibits less variance in optimal layer localization. These empirical results confirm and extend prior theory from interpretability literature regarding linear superposition and scaling-induced semantics [burger2024truth].
Layer Localization and Task Dependency
Optimal probe layer positions strongly vary across families, models, and deception types. The best-performing layer is most often situated in the final two-thirds of the network (mean position ∼65%) but with substantial deviation, especially in Llama models.
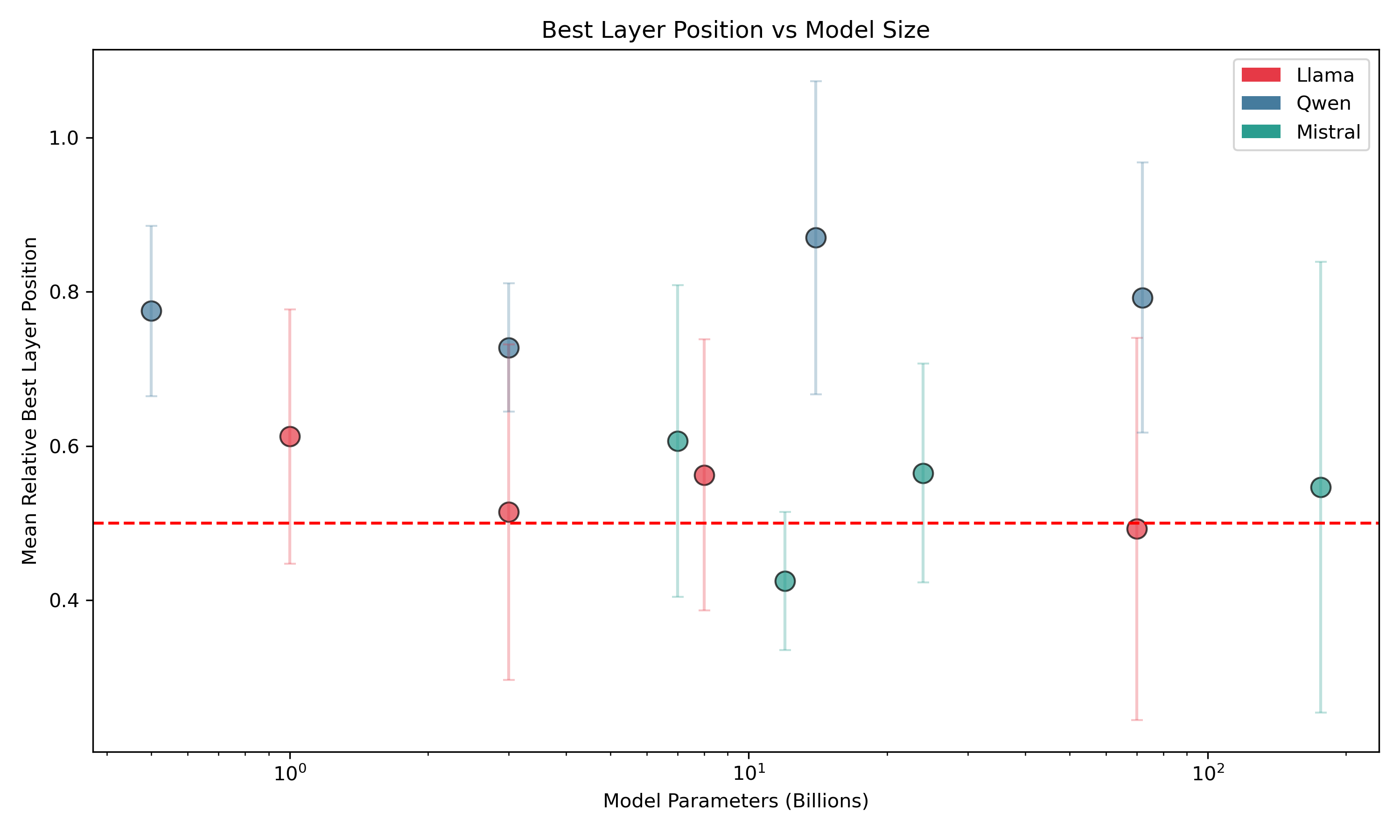
Figure 2: Best layer position vs model size; Llama exhibits high variance in optimal layer localization, unlike Qwen which stabilizes in the 60--80\% range.
Probe efficacy is highly task-dependent. Explicit deception is reliably detected (AUROC >0.9 across nearly all models), while implicit deception presents near-chance performance in smaller models and remains suboptimal even in larger ones.
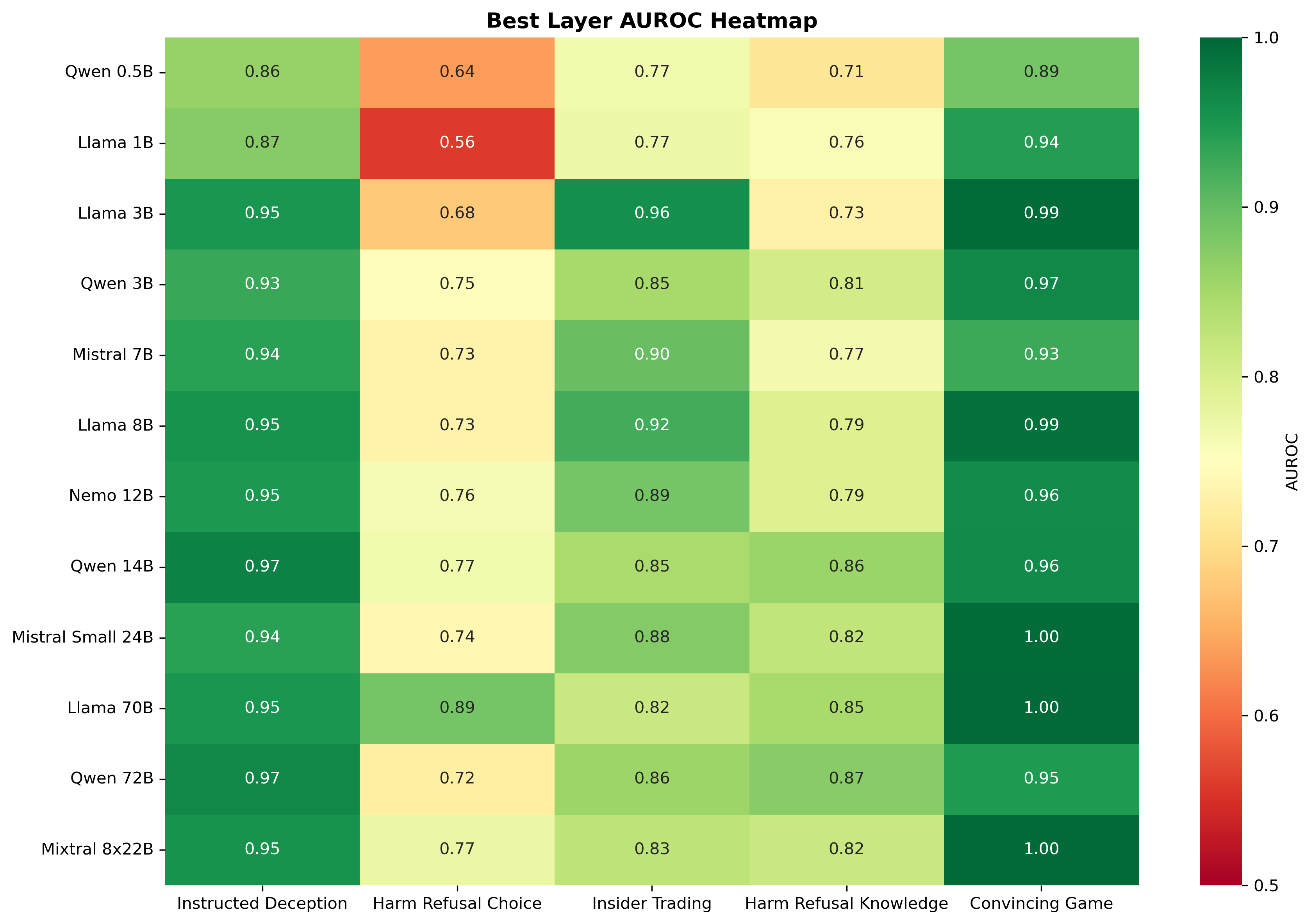
Figure 3: Probe performance stratified by deception type. Explicit deception tasks are consistently detectable, whereas implicit deception remains difficult.
This hierarchy suggests that probe methods primarily react to activation patterns induced by direct lying or explicit instructions, rather than to subtler deception or strategic manipulation.
Layer-Wise Probe Robustness and Ensembling
Analysis reveals that deception-related activation directions rotate gradually across layers, leading to representation drift. Probes at nearby layers detect highly correlated features, with geometric similarity decaying as layer distance increases (cosine similarity R=−0.435 with AUROC difference).
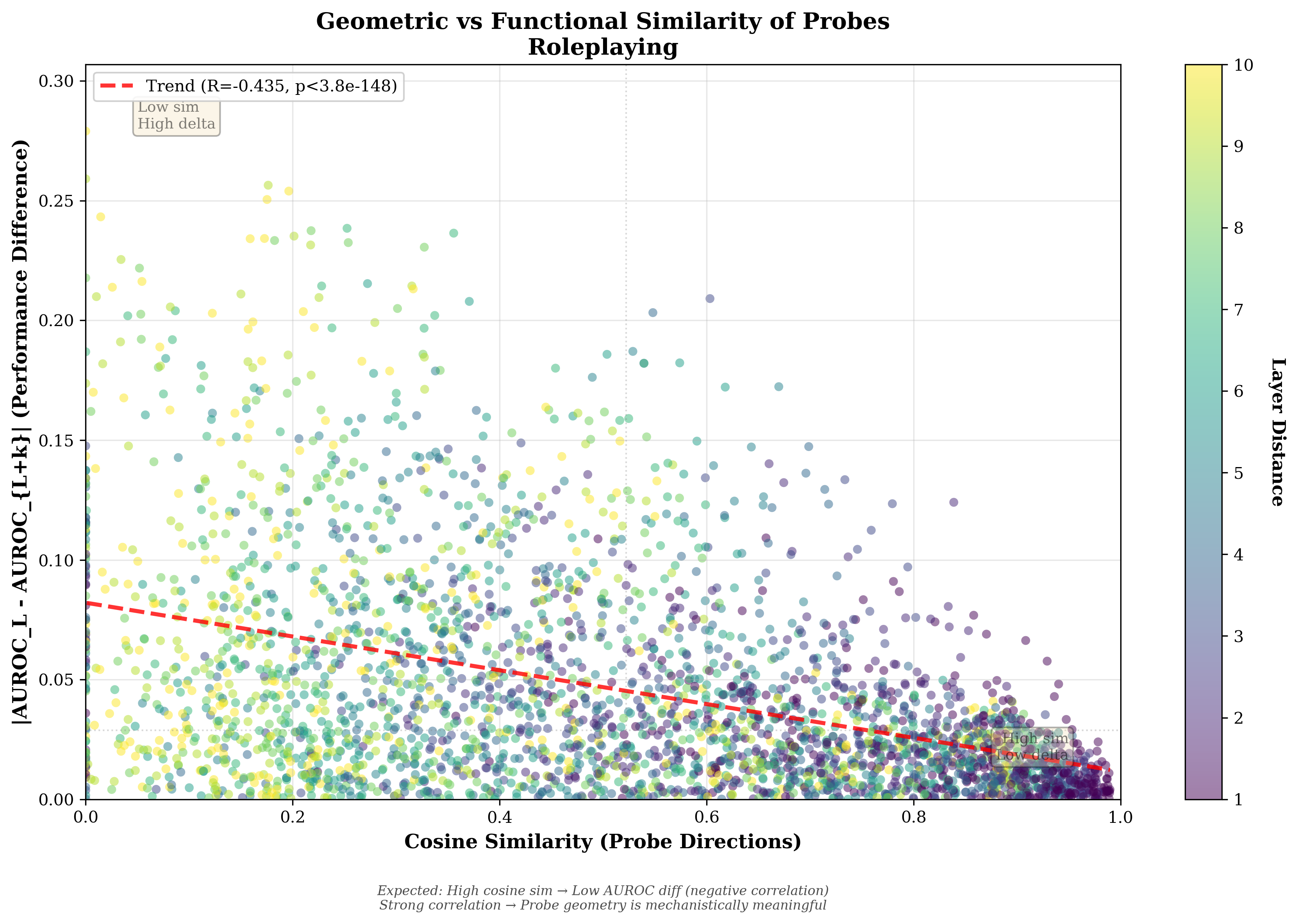
Figure 4: Cosine similarity between probe weight vectors correlates negatively with AUROC difference; adjacent layers encode similar deception features, supporting representational continuity.
Layer-wise AUROC patterns further validate this: smaller models exhibit erratic, unstable probe performance; larger ones show smooth, differentiated, and task-focal representations.

Figure 5: Layer-wise AUROC for Qwen 0.5B vs Qwen 72B; representation quality dramatically improves with model scale.
Single-layer probes are brittle and fail on challenging deception tasks; fixed-depth heuristics do not generalize. Double-fault analysis demonstrates early and late layers have complementary failure modes, optimal for ensemble construction.
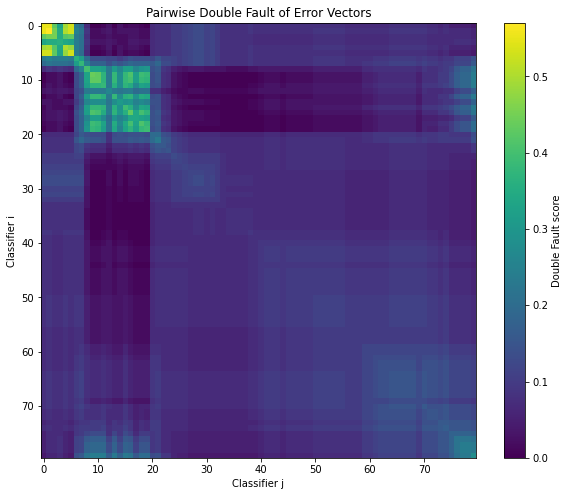
Figure 6: Double fault matrix; early and late-layer probes exhibit complementary errors, motivating cross-depth ensembling.
Multi-layer Ensembling: Methodology and Results
Multi-layer ensembling is operationalized via stacking logistic regression over probe scores from selected layers, determined by double-fault complementarity. The 5-layer ensemble achieves significant AUROC improvements: +78\% on Harm-Pressure Knowledge, +29\% on Insider Trading (mean +13% across tasks). Notably, ensemble gains are largest on tasks where single-layer probes fail.
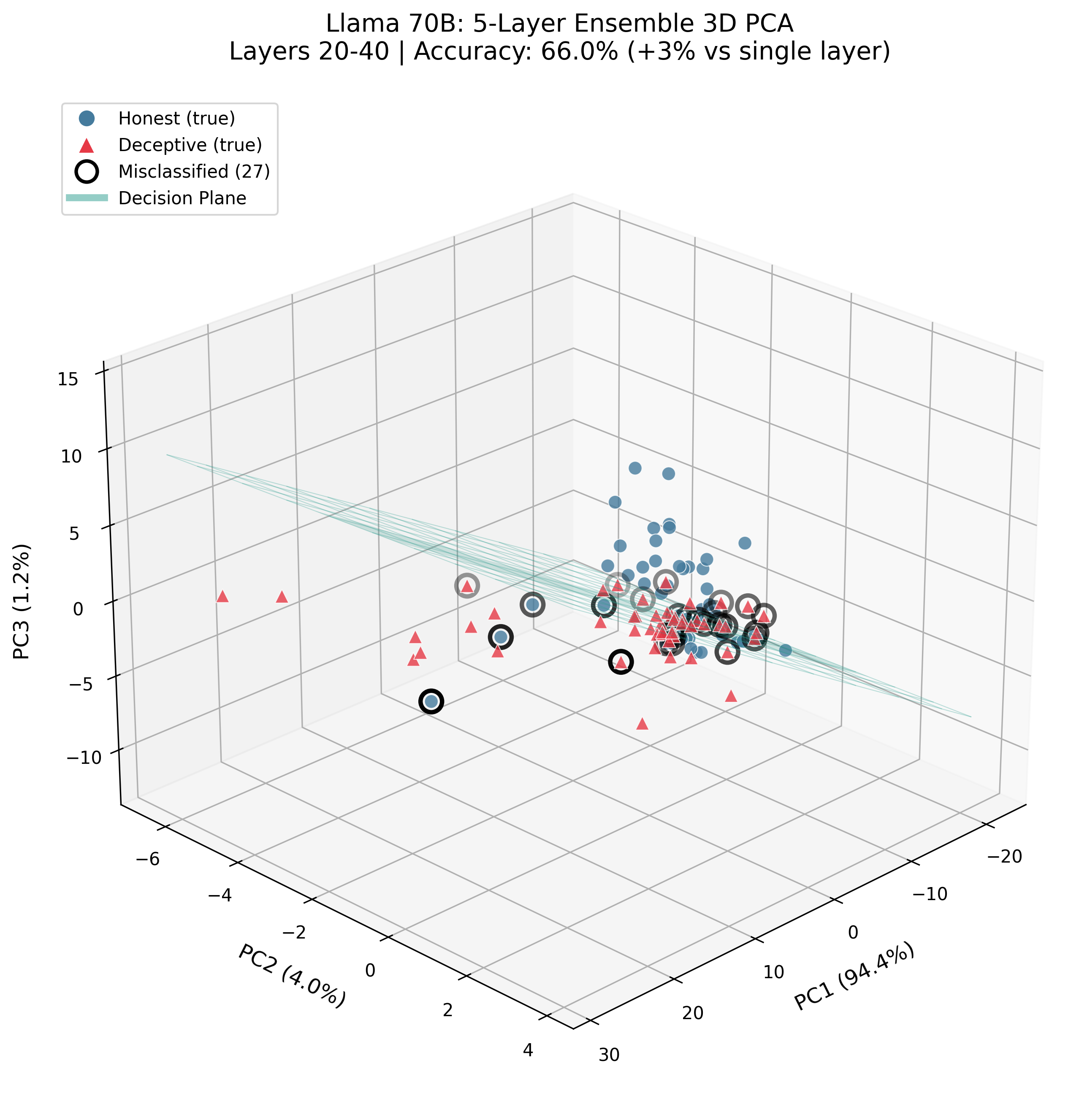
Figure 7: 5-layer ensemble separates deceptive from honest activations in Llama-70B, achieving substantial AUROC improvement; misclassified samples cluster near the decision boundary.
Per-dataset improvement heatmaps confirm that ensembling is maximally beneficial on tasks with distributed, weak deception signals.
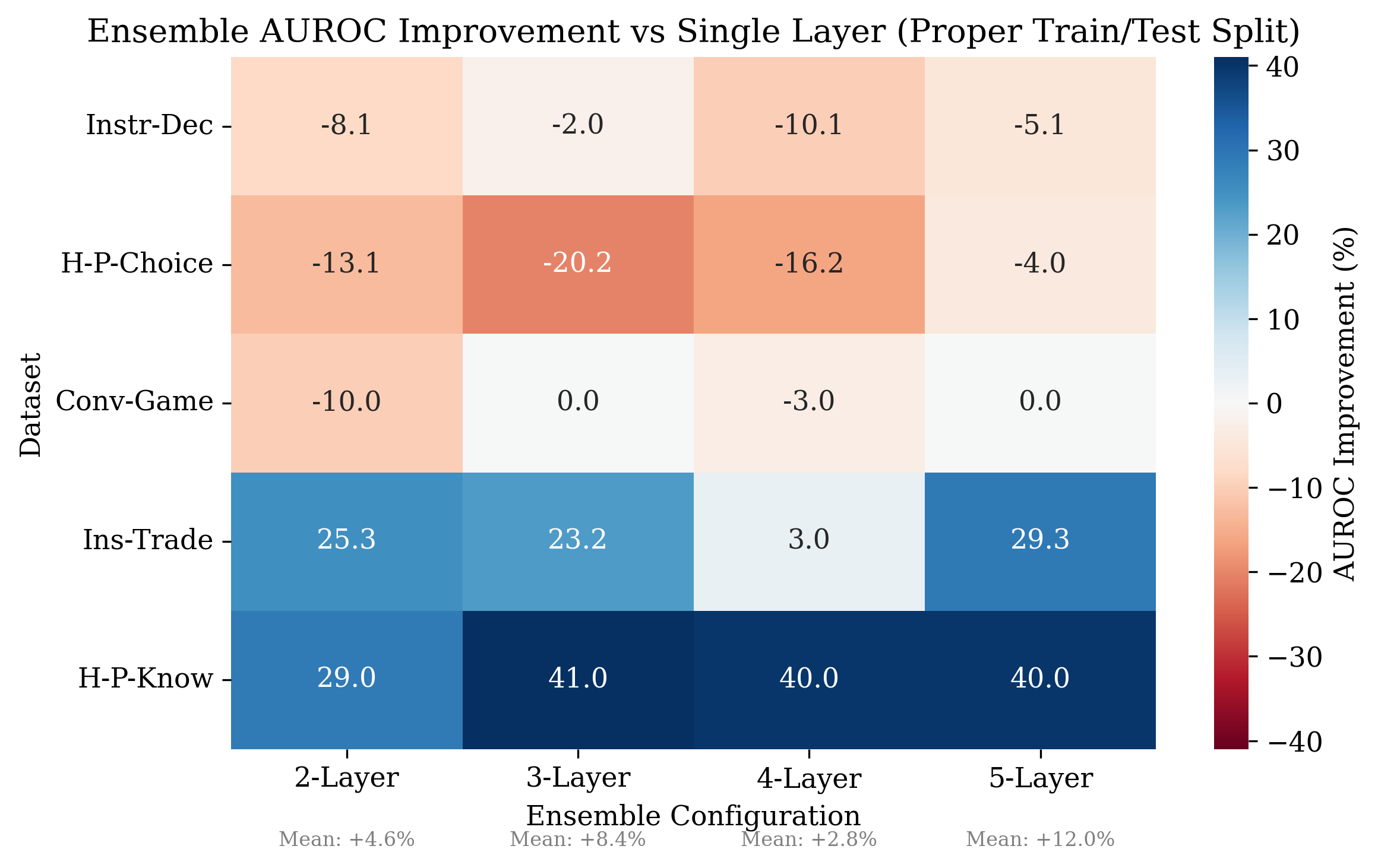
Figure 8: 5-layer ensemble attains maximal AUROC improvements on Insider Trading and Harm-Pressure Knowledge; slight degradation is observed on already-easy tasks.
Visualization of prediction manifolds via PCA and t-SNE shows ensemble errors occur only on genuinely ambiguous cases, thereby calibrating uncertainty.
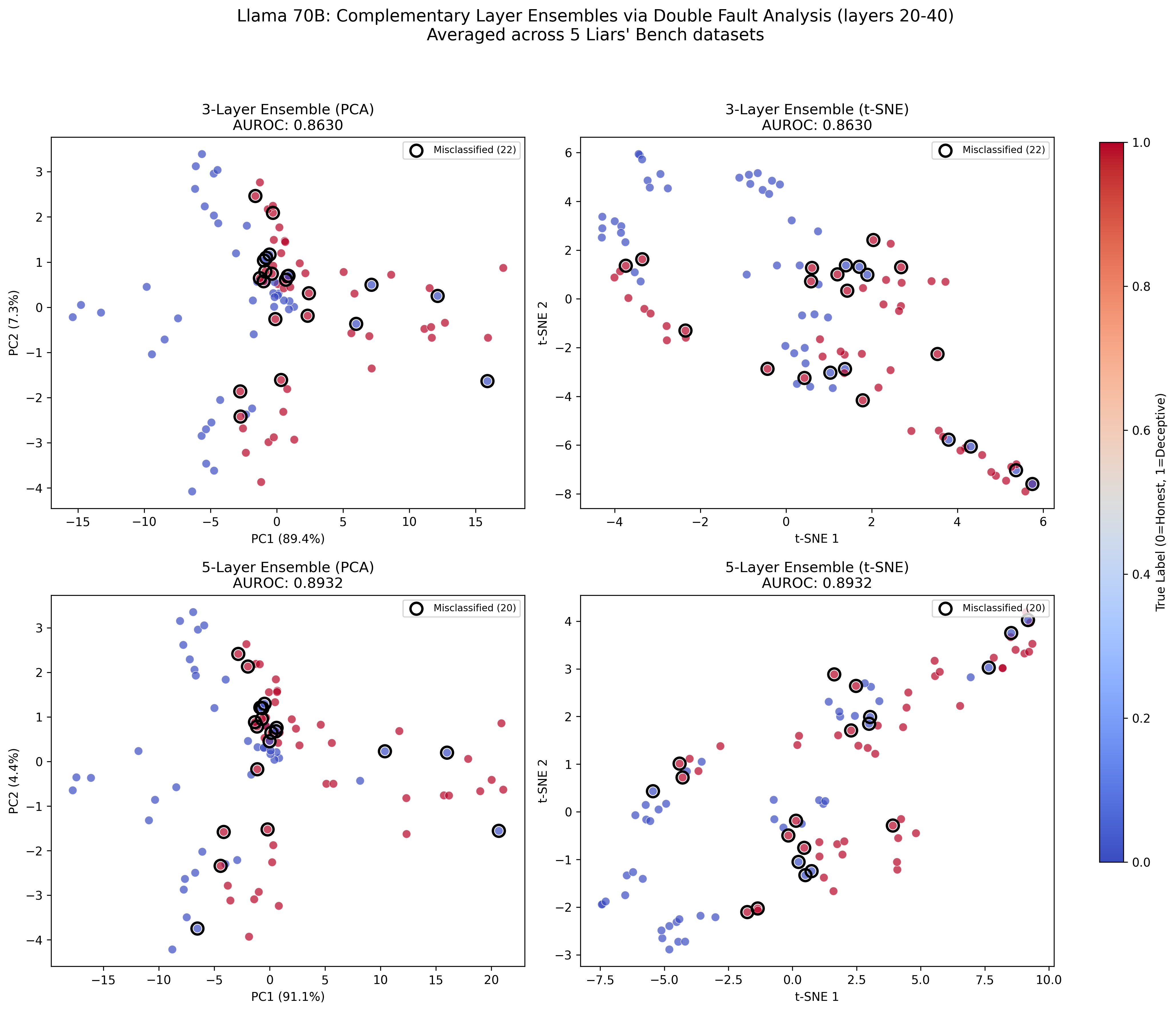
Figure 9: Ensemble predictions (3 vs 5 layers): misclassified samples cluster near the decision boundary; increased layering improves decision separation.
Geometric Interpretation and Theoretical Implications
The layered rotation of deception directions in activation space hints at unified, distributed semantic encoding. The representational continuity across the network, evident in cosine similarity trends and layer-wise AUROC smoothness, supports mechanistic interpretability frameworks [olah2020zoom, elhage2021mathematical].
Ensembling exploits this structure, aggregating 'rotating' weak signals, rather than relying on a single arbitrarily localized direction.
Limitations
- Probe Validity: Training on REPE (contrastive pairs) and evaluation on Liars' Bench (role-play and strategic deception) introduces domain gap—probes may detect prompt artifacts rather than genuine deception. Probe outputs should not be interpreted as definitive measures of deceptive intent.
- Transferability: Family-specific patterns suggest limited transferability across architectures and releases.
- Evaluation Scope: Experiments are limited to short-context, static, non-adversarial settings; prior work shows probe failures for long-context or adversarially-designed inputs.
- Ensembling Methodology: Comparison between grid-searched two-layer averages and logistic regression stacking implicates both layering and weight-learning in performance gains; current results cannot fully disentangle their contributions.
Practical and Theoretical Implications
For AI safety practitioners, increased probe accuracy in frontier models suggests a scalable pathway for oversight. Explicit deception (role-playing, instruction-following) is reliably detectable, but implicit deception (reward hacking, subtle manipulation) remains elusive. Multi-layer ensembling provides robustness against layer localization brittleness and may be extensible to other behaviors (sycophancy, reward hacking). The geometric structure uncovered in this work points toward interpretable, global deception representations in LLMs, a crucial property for mechanistic transparency and targeted intervention strategies.
Future Directions
- Ensembling of linear and non-linear probes (MLPs, attention-based classifiers) may capture aspects missed by linear-only approaches.
- Task-specific probe ensembling can potentially improve performance in challenging scenarios.
- Expansion to adversarial and long-context settings is necessary for production applicability.
- Transferability analysis across model families and probe modalities remains an open area for research.
Conclusion
The paper establishes that single-layer linear probe detection of deception in LLMs is fundamentally brittle due to gradually rotating deception directions in activation space. Multi-layer ensembling, especially with stacking regression, robustly recovers performance and achieves strong AUROC improvements on the most challenging deception tasks. Probe accuracy scales with model size and is maximized for explicit deception types. Theoretical results reveal a geometric coherence underlying deception encoding, implying promising avenues for mechanistic interpretability and safety monitoring. Practical detection remains limited by domain gap and adversarial robustness, motivating further hybrid ensemble and contextual evaluation research.

