- The paper introduces TabDistill, a framework that distills complex feature interactions from tabular foundation models into generalized additive models.
- It employs a modular pipeline combining TFM fitting, FBII-based attribution, and interaction ranking to systematically enhance model performance.
- Empirical results demonstrate that TabDistill outperforms traditional greedy methods, achieving superior accuracy and interpretability on multiple tabular benchmarks.
Selecting Feature Interactions for Additive Models via Foundation Model Distillation
Introduction
The paper "Selecting Feature Interactions for Generalized Additive Models by Distilling Foundation Models" (2604.13332) addresses the persistent challenge of identifying statistically and practically meaningful feature interactions for interpretable models, specifically Generalized Additive Models (GAMs), in tabular domains. Standard GAMs provide transparent, feature-level effect decomposition, yet their predictive power on real-world datasets is limited by their inability to capture important non-additive interactions. Existing interaction selection methods often employ greedy, pairwise heuristics, thereby risking omission of higher-order, context-dependent dependencies critical for both prediction and mechanistic insight.
To overcome these deficiencies, the authors introduce TabDistill, a modular framework which leverages modern tabular foundation models (TFMs) as the substrate for feature interaction discovery. Instead of relying on heuristic or model-constrained searches, TabDistill harnesses the adaptive, large-scale representation learning capabilities of TFMs to uncover a diverse spectrum of salient interaction structures. This distillation process lifts previously opaque, high-capacity black-box model information into the interpretable, additive framework of GAMs, yielding model instances that are both accurate and intelligible.
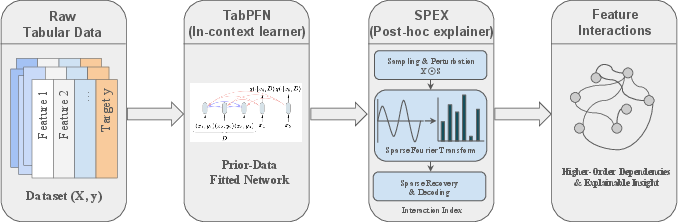
Figure 1: TabDistill operational pipeline combining TFM-based adaptive dependency learning with post-hoc explanation for interaction feature selection.
Methodological Framework
Model Structure and Objective
GAMs augmented with interaction terms are parametrized as
g(E[y∣x])=β+j=1∑pfj(xj)+I∈I∑fI(xI)
where fj are univariate (main effect) shape functions, and fI are functions over feature subsets I representing non-additive interactions. The central objective is to identify a minimal, performance-maximizing subset of interactions I (potentially higher-order, non-pairwise) that yield optimal expected loss for the downstream GAM.
The TabDistill Pipeline
The key components of TabDistill are:
- TFM Fitting: A TFM (e.g. TabPFN-2, TabICL) is fitted to the dataset, learning complex feature dependencies via large-scale or synthetic pretraining.
- Post-Hoc Attribution: A model-agnostic, sample-efficient interaction attribution algorithm—specifically the Faith-Banzhaf Interaction Index (FBII) calculated via the SPEX framework—extracts salient feature interactions from the fitted TFM. SPEX constructs an efficient, sparse surrogate in the Boolean Fourier basis, circumventing the exponential enumeration of the interaction space.
- Interaction Ranking and Selection: Salient interaction terms are ranked and selected based on their estimated importance across samples.
- Interpretable Model Update: The selected interactions are incorporated as additional terms in a GAM (e.g., EBM), thus boosting predictive capacity while retaining interpretability.
This approach preserves black-box model benefits while remaining model-agnostic; attribution is feasible for arbitrary TFM architectures. By design, TabDistill accommodates both pairwise and higher-order interactions.
Empirical Evaluation
Benchmarking on Real-World Data
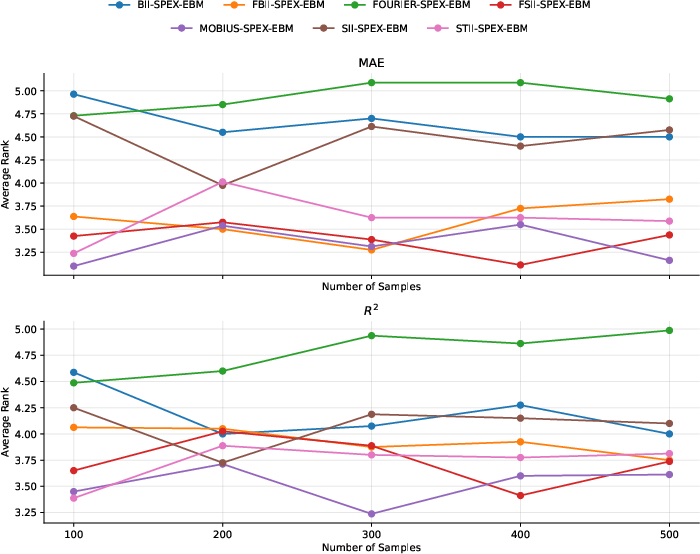
TabDistill is empirically evaluated across a set of standardized tabular benchmarks (TabArena, TALENT, PMLB), predominantly comprising datasets under 2000 samples and 10 features, in both regression and classification regimes. Key baselines include FAST (greedy, pairwise addition) and RuleFit (interaction mining via tree rules). All methods are evaluated via downstream predictive performance on GAMs, with rankings assessed across multiple metrics (MAE, MSE, R2, F1, accuracy, AUROC), controlling for the number of included interactions (Nint from 1 to 8).
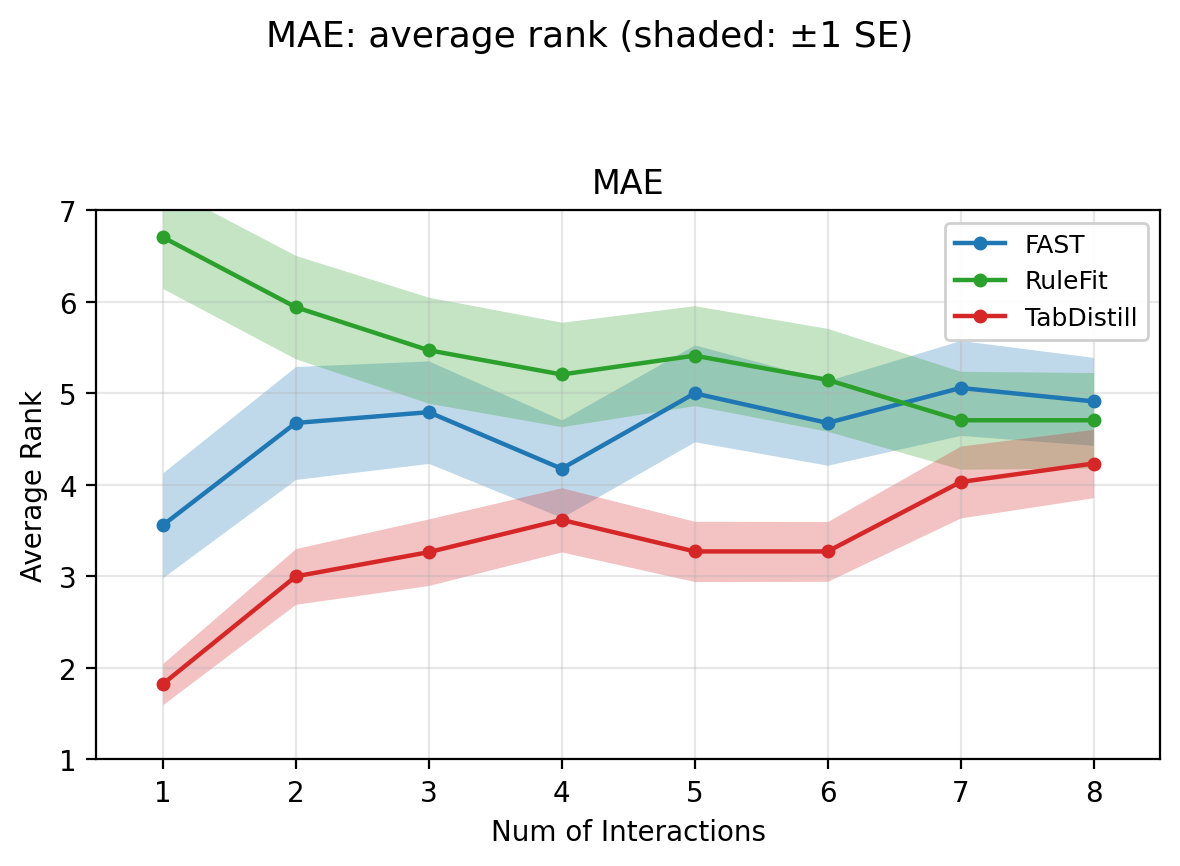
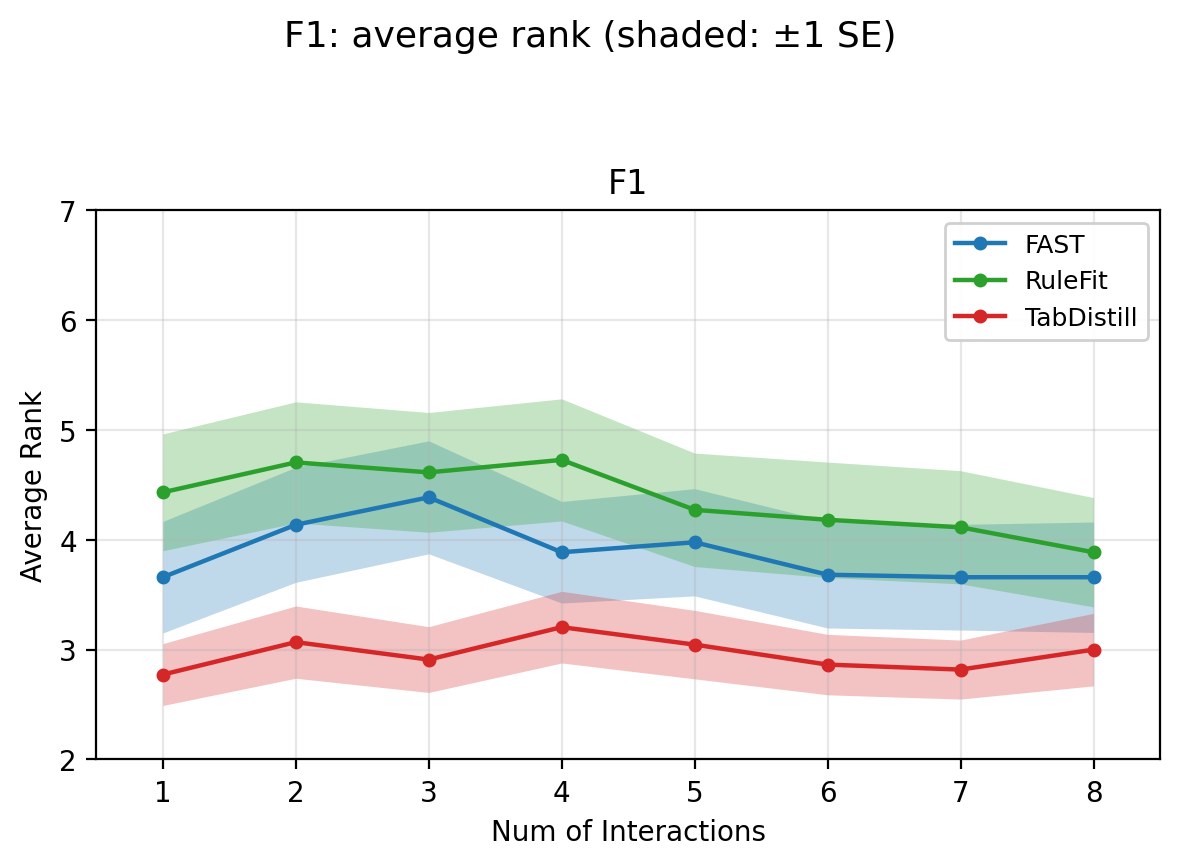
Figure 2: Regression average rank (MAE) comparison: TabDistill consistently outperforms baselines with lower ranks.
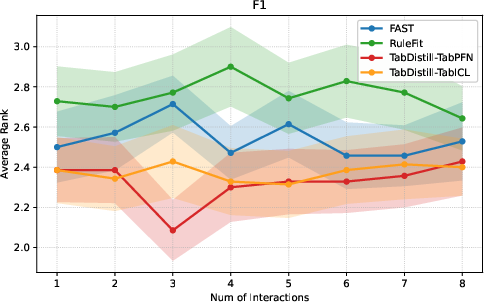
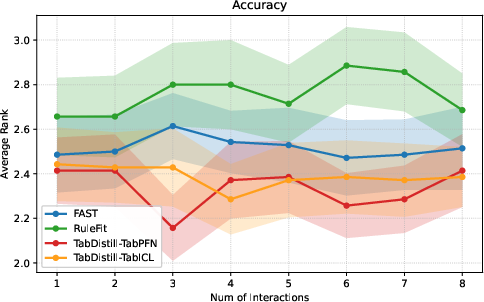
Figure 3: Comparative classification ranks (F1 left, accuracy right) for TabDistill on TabICL/TabPFN, showing robust superiority over alternative methods.
TabDistill consistently achieves superior (lower) ranks compared to baselines for both regression and classification tasks at low interaction budgets, substantiating the claim that the TFM-guided approach is more effective at identifying high-value interactions than data-driven heuristics or decision rule mining. As the interaction budget increases, performance convergence across methods is observed, indicating that initial interaction selection is critical for practical, parsimony-demanding tasks.
Transferability and Stability
Ablation studies demonstrate several salient properties:
Synthetic Validation of TFM Interaction Capacity
On controlled synthetic domains, the authors demonstrate that TabPFN can recover ground truth non-additive interactions with high precision, outperforming standard machine learning models even in low-data, high-dimensional (Fourier-sparse) and complex interaction (tree-structured) regimes.
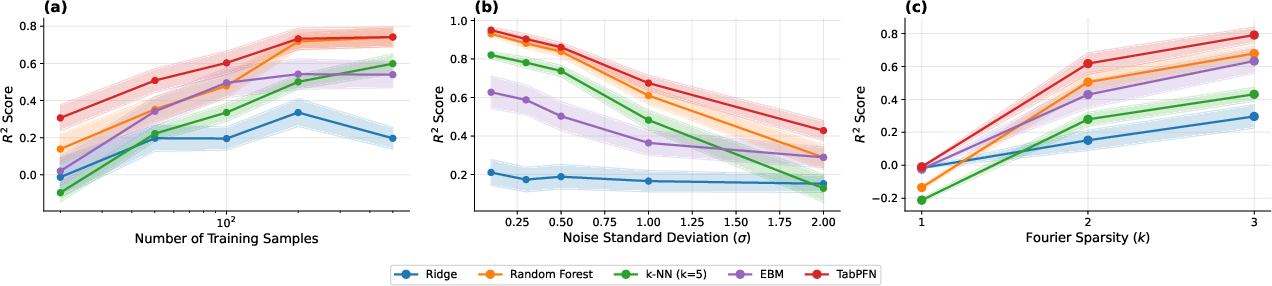
Figure 5: TabPFN performance against baselines on Fourier-sparse functions under low-data, noise, and sparsity variations.
Case Study: Interpretable Used-Car Price Prediction
On the TabArena Fiat 500 car pricing task, TabDistill-augmented EBM achieves state-of-the-art MAE and R2 performance (MAE: 536.1, R2: 0.86). Critically, TabDistill uniquely discovers a higher-order interaction among longitude, latitude, and model type, revealing a fundamentally non-additive dependency not isolated by pairwise-only (FAST) or tree rule-based (RuleFit) methods.
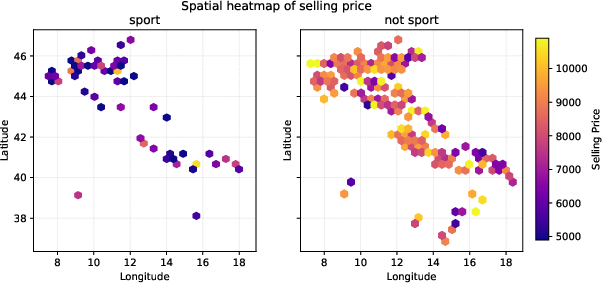
Figure 6: Visualized higher-order interaction: joint effect of seller location and model type on predicted price.
Theoretical and Practical Implications
TabDistill demonstrates that high-capacity TFMs encode complex, context-dependent feature interactions that, when effectively distilled, can be efficiently injected into additive interpretable frameworks such as GAMs. This approach bridges the performance–interpretability tradeoff by utilizing state-of-the-art representations for targeted structure transfer, not blind knowledge distillation. In principle, this pipeline generalizes to any scenario where structured black-box representations must be synthesized into transparent, domain-interpretable hypotheses—spanning scientific discovery, regulatory domains, or high-stakes operational models.
In practice, limitations remain. The procedure inherits failure modes and spurious interaction artifacts from the underlying TFM, and attribution is computationally intensive at large scale. Future work may involve more sample-efficient attribution schemes (e.g., ProxySPEX), direct interaction-aware TFM training objectives, or integration into human-in-the-loop settings for hypothesis or mechanism discovery.
Conclusion
The TabDistill framework empirically and methodologically advances the identification of meaningful, high-impact feature interactions for interpretable additive models by distilling knowledge from tabular foundation models. It substantiates consistent performance improvements over established heuristics, enables detection of complex non-additive effects, and offers a generalizable, model-agnostic paradigm for bridging predictive performance and interpretability in tabular machine learning. The integration of post-hoc attribution, efficient sparse recovery, and modular interfacing with diverse TFMs positions TabDistill as a practical path forward for accurate, transparent modeling across scientific and operational domains.