- The paper introduces a model-agnostic alignment update that rewrites new Semantic IDs into the old token vocabulary to preserve retriever compatibility.
- It empirically demonstrates that aligned SIDs (FT-ours) outperform both stale SIDs and naïve SID refreshes, maintaining high retrieval metrics under temporal drift.
- The method reduces training compute by approximately 8–9× compared to full retraining, offering a practical solution for continual adaptation in dynamic environments.
Mitigating SID Staleness in Generative Retrieval Under Temporal Drift
Context and Problem Setting
Generative retrieval with Semantic IDs (SIDs) reconfigures large-scale candidate generation for recommender and retrieval systems by encoding each item with a sequence of discrete tokens. Unlike dense nearest-neighbor retrieval, this approach facilitates autoregressive generation over a tokenized item vocabulary, decoupling the retrieval process from explicit vector similarity computations. While content-driven SID assignments are robust to item additions and cold start, interaction-informed SIDs trained on user--item behavior afford superior retrieval performance by capturing latent collaborative structures. However, as user-item interactions evolve due to drift in interests, popularity, or logging policies, these collaborative SIDs rapidly become outdated, undermining retrieval quality—a phenomenon referred to as SID staleness.
Prior practical systems commonly lock the SID vocabulary and simply finetune on new data (incurring semantic mismatch over time) or perform costly full retraining following SID refreshes, precluding efficient continual adaptation. The literature has lacked explicit, systematic quantification of SID staleness under strict temporal drift and practical solutions for seamless checkpoint-compatible SID update.
Semantic-ID Alignment Update: Methodology
The paper introduces a model-agnostic alignment update for SIDs that preserves retriever compatibility while integrating fresh interaction logs. Formally, given an 'old' SID assignment tied to a deployed retriever checkpoint and a 'new' SID assignment constructed from recent data, the method builds a bijective mapping aligning each codebook position ℓ in the new SIDs to the corresponding old token space. The mapping leverages observed co-occurrence statistics among overlapping items to maximize token correspondences according to empirical frequency, reducible to standard bipartite matching (solved via either greedy or Hungarian algorithms for each codebook position).
Upon applying the resulting per-codebook alignments, the new SIDs are rewritten into 'aligned SIDs' inhabiting precisely the old token vocabulary expected by the retriever checkpoint. This enables warm-start finetuning directly on updated collaborative signals, sidestepping the prohibitive compute cost of full retraining.
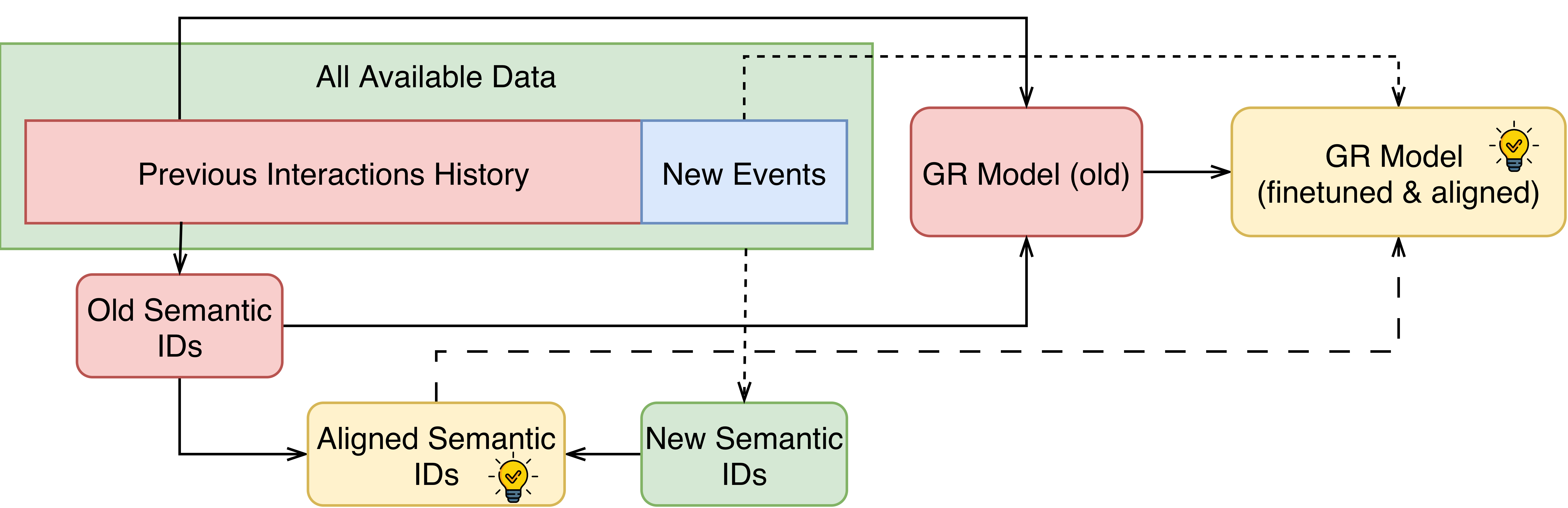
Figure 1: Overview of the alignment pipeline, showing SID reconstruction, token mapping to the old vocabulary, and warm-started retriever finetuning.
Empirical Evaluation
Benchmark Tasks and Implementation
Evaluation involves three temporally partitioned user-item datasets: Amazon Beauty (e-commerce), VK-LSVD (short-video streaming), and Yambda (music streaming). The experiments control for all modeling and training factors except SID assignment, ensuring a transparent comparison. The methods compared are:
- Content-only SIDs (TIGER-style)
- Interaction-informed SIDs (LETTER-style), with further variants:
- FT-old: stale SIDs with warm-start finetuning
- FT-new: fully rebuilt SIDs without alignment
- FT-ours: aligned SIDs enabling warm-start
- Full: retraining from scratch with rebuilt SIDs
Evaluation follows rolling-origin chronological splits, using Recall@K and nDCG@K with a focus on high-cutoff retrieval.
Main Findings
- Interaction-informed SIDs significantly outperform content-only SIDs across all datasets, reflecting the benefit of collaborative signals.
- Naive SID refresh (FT-new) without alignment can be detrimental or ineffective for warm-starting, often yielding inferior or marginally improved recall compared to keeping stale SIDs (FT-old), due to mismatch between the model's output space and the new SID vocabulary.
- The proposed SID alignment method (FT-ours) robustly improves retrieval metrics compared to both FT-old and FT-new, and often matches or surpasses full retraining in Recall@500, with negligible additional overhead relative to finetuning.
Sustainability Under Continual Adaptation
Multi-step experiments on VK-LSVD demonstrate that while FT-old accrues pronounced degradation under repeated updates, SID alignment enables stable, performant continual adaptation on par with or exceeding full retraining, without the associated compute burden.
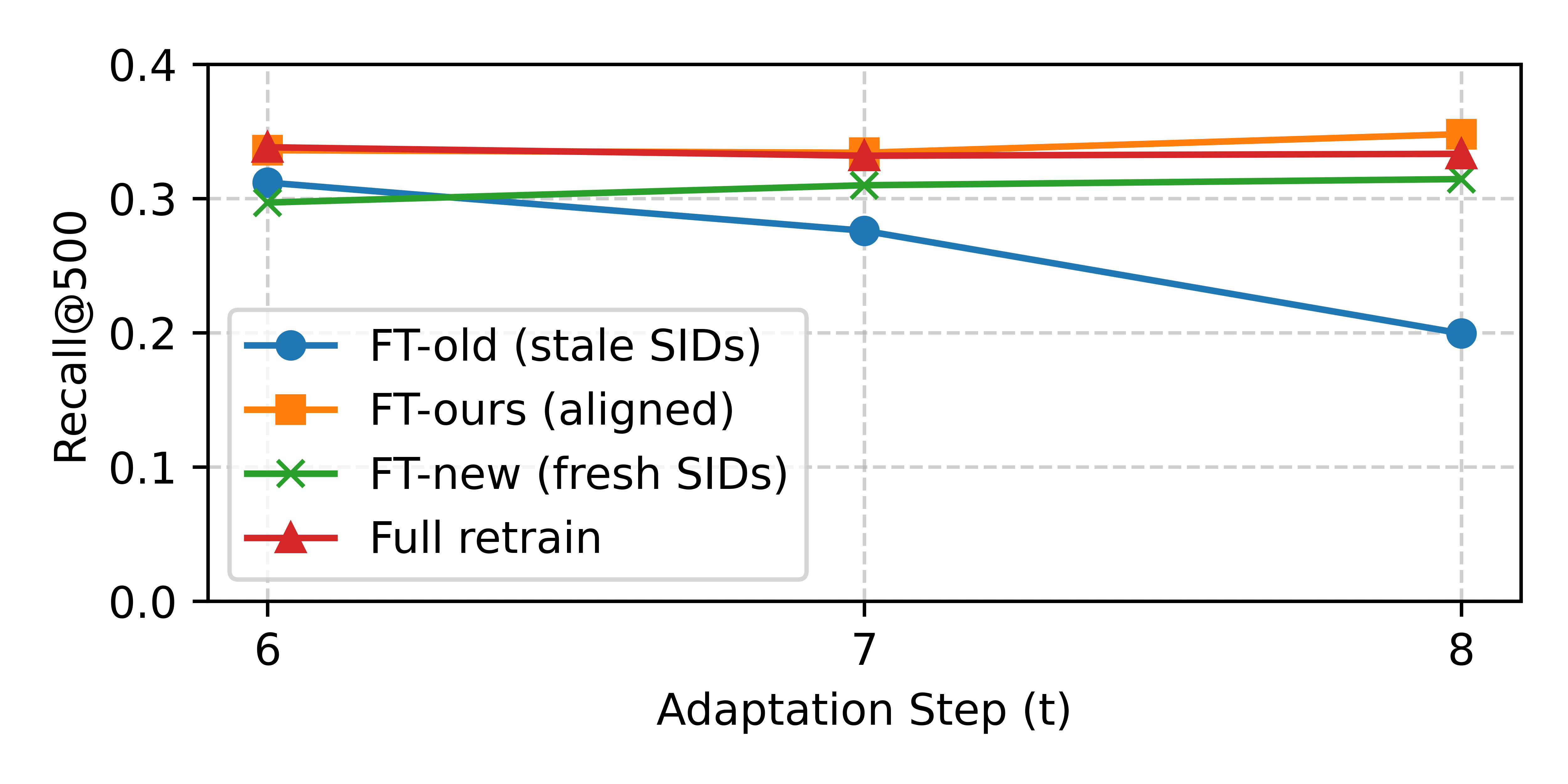
Figure 2: Evolution of Recall@500 across consecutive adaptation steps on VK-LSVD, showing FT-ours (alignment) maintaining high recall relative to alternatives.
Compute–Quality Trade-off
Quantitative analysis reveals that warm-start adaptation via FT-ours yields an approximately 8–9× reduction in training FLOPs versus full retraining, achieving superior or comparable recall. The alignment step itself is computationally negligible, due to efficient codebook-wise matching on small token spaces. Thus, alignment shifts the quality–compute frontier in favor of practical, frequent SID refresh.
Theoretical and Practical Implications
This work reframes the continual adaptation problem in generative retrieval systems, addressing the heretofore neglected issue of semantic mismatch under collaborative SID staleness. The alignment method—a lightweight combinatorial postprocessing—harnesses fresh interaction data while retaining checkpoint compatibility, systematically bridging the gap between SID expressivity and operational efficiency.
Practically, this enables faster, more stable model updates in dynamic applications (e.g., streaming, e-commerce, recommendation), ensuring that deployed retrievers can remain synchronized with evolving user behavior without the latency and resource requirements of full pipeline retraining. Theoretically, this provides a paradigm for decoupling identifier evolution from model parameterization in sequence-based retrieval systems.
Limitations and Future Research
Future directions include dynamic handling of true vocabulary expansion (supporting item cold start and catalog growth), tighter integration with tokenizers capable of incremental learning, and extensions to multi-modal or hierarchical SID structures. Additionally, exploring adaptive alignment solvers (beyond greedy/Hungarian) as codebook sizes and drift rates grow may further enhance efficiency and stability.
Conclusion
By isolating and addressing the problem of SID staleness in collaborative generative retrieval, this paper introduces an efficient alignment scheme that enables robust, checkpoint-compatible, and computation-efficient adaptation to temporal drift in user-item interactions. The approach achieves strong recall at a fraction of conventional retraining cost, opening practical avenues for rapid retriever evolution in production environments.