Exploration and Exploitation Errors Are Measurable for Language Model Agents
Abstract: LLM (LM) agents are increasingly used in complex open-ended decision-making tasks, from AI coding to physical AI. A core requirement in these settings is the ability to both explore the problem space and exploit acquired knowledge effectively. However, systematically distinguishing and quantifying exploration and exploitation from observed actions without access to the agent's internal policy remains challenging. To address this, we design controllable environments inspired by practical embodied AI scenarios. Each environment consists of a partially observable 2D grid map and an unknown task Directed Acyclic Graph (DAG). The map generation can be programmatically adjusted to emphasize exploration or exploitation difficulty. To enable policy-agnostic evaluation, we design a metric to quantify exploration and exploitation errors from agent's actions. We evaluate a variety of frontier LM agents and find that even state-of-the-art models struggle on our task, with different models exhibiting distinct failure modes. We further observe that reasoning models solve the task more effectively and show both exploration and exploitation can be significantly improved through minimal harness engineering. We release our code \href{https://github.com/jjj-madison/measurable-explore-exploit}{here}.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain‑Language Summary of the Paper
What is this paper about?
This paper looks at how AI “agents” that use LLMs (like ChatGPT) make decisions in complicated tasks. In these tasks, an agent needs to do two things well:
- Explore: go find new information it hasn’t seen yet.
- Exploit: use what it already knows to finish the job.
The big idea: the authors build a way to measure when an AI agent makes exploration mistakes and when it makes exploitation mistakes—just by watching what it does, not by looking inside how it thinks.
What questions do the authors ask?
In simple terms, they ask:
- Can we tell the difference between “bad exploring” and “bad exploiting” just by watching an agent’s actions?
- Can we measure those mistakes in a fair way that doesn’t assume one “correct” plan?
- How well do different LLMs balance exploring and exploiting in tricky tasks?
- Can small changes—like better instructions or a simple memory aid—help agents do better?
How did they study it? (with an easy analogy)
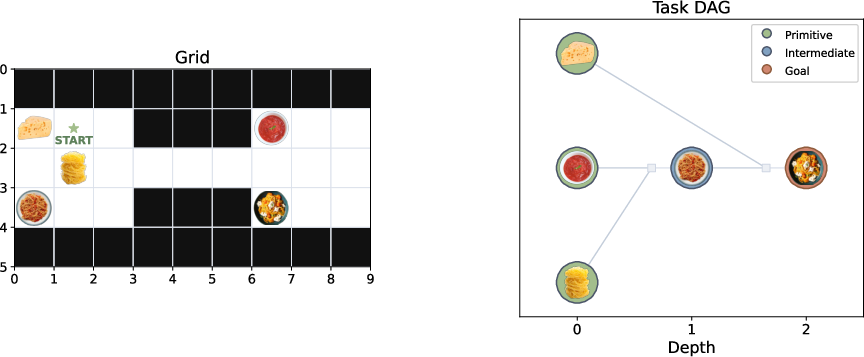
Imagine a video game:
- There’s a maze (a 2D grid of rooms). You can only see what’s near you, so you have to walk around to reveal new rooms.
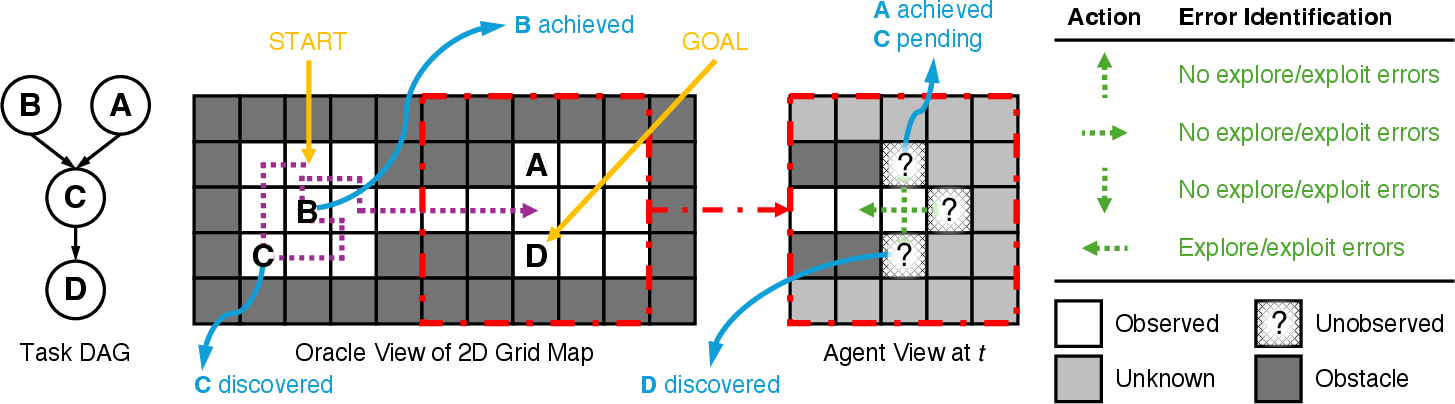
- There are hidden “task items” placed around the maze—like keys or switches—that must be done in the right order (some need all prerequisites done first, others need just one). This “right order” is stored as a task flowchart (a Directed Acyclic Graph, or DAG), which you learn bit by bit as you find items.
- The agent’s job is to discover the needed items and activate them in the right order to reach the final goal.
Key choices the authors made:
- They removed real‑world meanings (like “pasta,” “cheese,” etc.) and used symbols instead. Why? So models couldn’t just rely on their world knowledge and had to truly explore and reason.
- They varied the maps to make exploration harder (more open space, more hidden cells) or exploitation harder (trickier task chains that require careful planning).
How they measured mistakes without peeking inside the agent:
- At each step, the agent should either:
- Explore (head toward unrevealed cells) when it needs new information, or
- Exploit (head toward a known “ready” task) when it has enough info to make progress.
- They define a “target set” of useful destinations for the current moment (either unrevealed cells for exploration or known ready tasks for exploitation).
- A “gain” move is one that moves into a target or gets closer to one. If it doesn’t, it’s probably a mistake.
- But sometimes you can keep “getting closer” without really progressing (like pacing back and forth). So they add a “stale score” that goes up when the agent:
- Closes pointless loops,
- Reuses the same paths too many times,
- Repeats visiting the same places without progress.
- If the stale score increases, they count it as an error. They then label the error as an exploration error, an exploitation error, or both—depending on what the agent should have been doing at that moment.
They tested many frontier LLMs in these environments, used different prompts (e.g., “focus on exploration” vs. “focus on exploitation”), and tried simple “harness engineering” (like giving the agent a clean, structured memory of what it has seen).
What did they find, and why is it important?
Here are the main takeaways, explained simply:
- Low exploration error predicts success:
- Agents that explore well are much more likely to finish the task. If you never find the items, you can’t win—even if you’re great at exploiting known info.
- Same success, different styles:
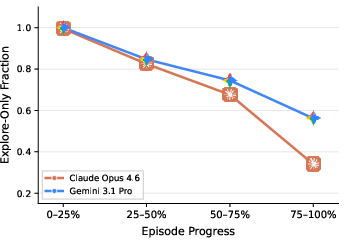
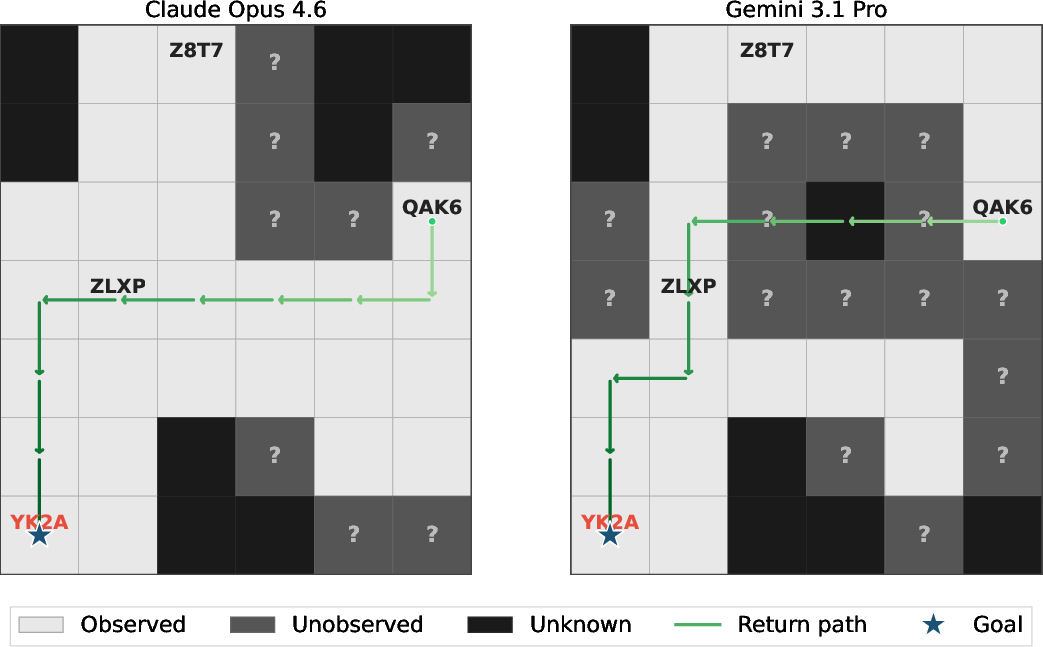
- Two top models could both win almost all the time but behave differently. For example, one might take direct routes once it knows enough, while another keeps revealing extra unseen cells along the way. This means “success rate” alone can hide interesting behavior differences.
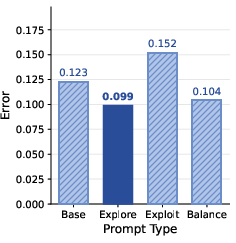
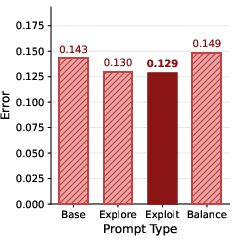
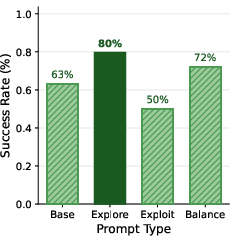
- Prompts matter:
- Telling the agent “prioritize exploration” reduces its exploration mistakes; saying “prioritize exploitation” reduces exploitation mistakes.
- The highest overall success often came from exploration‑focused prompts—again showing how crucial exploring is.
- A simple memory helps a lot:
- Giving agents a clean, structured “harness” (like an organized map of what’s been seen and a checklist of discovered tasks) significantly improved success rates and reduced both kinds of errors.
- Real‑world meanings change behavior:
- When the authors added back semantic hints (like a cooking task with named ingredients), some models used that knowledge to explore smarter, while others got biased and exploited too soon. Different models handled semantics differently.
Why it matters:
- This gives a fair, detailed way to judge agent behavior beyond just “did it win?” It shows where and how an agent struggles and how small tweaks can help.
What could this change in the future?
- Better agent design: Builders can use these measurements to diagnose whether an agent’s main problem is exploring or exploiting—and fix it with targeted prompts, training, or memory tools.
- Fairer benchmarks: Instead of only tracking if the agent finishes, researchers can also see why it failed and what type of mistake it made.
- Safer, more reliable agents: In real systems (coding assistants, workflow tools, or robots), this kind of analysis can reduce wasted time and avoid risky behavior by encouraging smart exploration before acting.
- Smarter use of knowledge: The results suggest that semantics (real‑world meanings) can help or hurt, depending on the model. Future agents may need better controls to use knowledge without getting overconfident.
In short, the paper shows how to tell “bad exploring” from “bad exploiting” by watching what an agent does in a controlled maze‑and‑tasks world. It finds that exploring well is the biggest key to success, that prompts and simple memory tools can make a big difference, and that models use real‑world knowledge in different ways. The authors share code so others can build on this and create more capable, trustworthy AI agents.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- External validity beyond symbolic 2D grids and DAGs: How well do the proposed metrics and findings transfer to richer environments (e.g., continuous/3D spaces, weighted graphs, stochastic dynamics, tool-use workflows, software/system tasks, and embodied robotics)?
- Role of semantics at scale: The paper shows small-scale effects of reintroducing semantic information; a systematic, large-scale study across diverse semantic domains (coding, web automation, household tasks) is missing to understand when semantics help exploration versus biasing toward myopic exploitation.
- Comparison to non-LM baselines: There is no head-to-head benchmarking against classical planners (e.g., BFS/A*, D* Lite), graph-exploration algorithms, or RL agents in the same environments to contextualize LM behavior and the metric’s discriminative power.
- Theoretical properties of the metric: Formal guarantees or axioms that the policy-agnostic error metric correctly distinguishes exploration vs. exploitation across edge cases are not provided; conditions under which misattribution can occur remain uncharacterized.
- Sensitivity to metric hyperparameters: The choice of budgets (2 for edges/nodes) and uniform weighting S_t = c_t + e_t + n_t is motivated but not ablated; how different thresholds/weights or alternative redundancy measures affect error attribution and correlations with success is unknown.
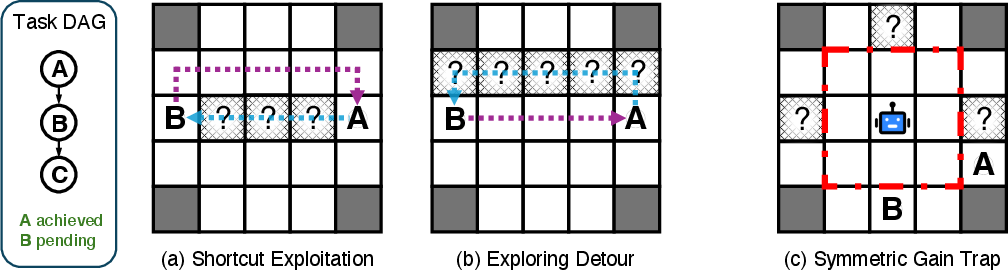
- Case-4 ambiguity (both actions allowed): Errors in Case 4 are attributed to both exploration and exploitation, which can mask the root cause; alternative disambiguation strategies (e.g., credit assignment based on opportunity cost or counterfactual shortest-path analyses) are unexplored.
- Trajectory-dependent normalization: Because per-case normalizations depend on the agent’s path (and step budget), comparing agents remains confounded; alternative normalizations, path-independent baselines, or counterfactual reweighting schemes are not evaluated.
- Anti-gaming and robustness: Agents could potentially “reset” no-progress by occasionally touching unobserved cells to avoid stale penalties; safeguards against such behaviors and robustness to strategic gaming are not explored.
- Optimality baselines for error bounds: The paper lacks oracle/planner-generated trajectories that establish lower bounds on achievable exploration/exploitation errors for each map, which would calibrate how far LMs are from principled upper/lower bounds.
- Generalization across map topologies: While maps are “programmatically adjustable,” there is no systematic taxonomy or theoretical difficulty index linking topological features (e.g., branching factor, corridor width, bottlenecks, diameter) to measured errors.
- Noisy and non-stationary environments: The metric assumes reliable observations and static DAGs; extensions to noise, dynamic obstacles, changing goals, partial/incorrect precondition info, or stochastic transitions are not studied.
- DAG assumptions and richer task logic: Only DAGs with AND/OR preconditions are considered; tasks with cycles, resource constraints, durations, revisitation requirements, or negative side-effects (consumables) remain unaddressed.
- Harness design space: The impact of harness engineering is demonstrated but not systematically mapped; trade-offs between harness size/structure, update frequency, memory fidelity, and performance across models remain open.
- Automatic harness/prompt optimization: Whether prompts and harnesses can be automatically tuned (e.g., via black-box optimization, meta-learning, or feedback from the proposed metric) to minimize exploration/exploitation errors is not explored.
- Training-time use of the metric: The metric is only used for evaluation; integrating it as a learning signal (e.g., reward shaping, self-training, curriculum selection, or verifier-guided planning) is an open direction.
- Interpreting internal strategies: The paper observes distinct behavioral modes across models but does not connect error patterns to interpretable internal policies or reasoning styles; causal analyses and probes are missing.
- Temperature and sampling effects: All evaluations use temperature 0 with limited seeds; how stochastic decoding, sampling strategies, or debate/ToT-style methods affect exploration/exploitation errors and variance is untested.
- Computational scalability: The overhead of tracking stale score components (c_t, e_t, n_t) and no-progress trajectories in large maps and long horizons is not analyzed; incremental or amortized implementations are unreported.
- Multi-agent settings: Extensions of the metric to multi-agent cooperation/competition (e.g., penalizing redundant joint exploration, credit assignment among agents) are not considered.
- Start-state and prior-knowledge confounds: Sensitivity to initial position, prior map priors, or partial pre-known structure is not explored; how such priors alter case distributions and metric values remains unclear.
- Weighted and continuous costs: The gain function relies on reducing minimum distance in an unweighted grid; extensions to weighted edges, anisotropic costs (e.g., turn penalties), or continuous navigation are not evaluated.
- Distributional realism of generated DAGs: The generative process for symbolic DAGs may not reflect the structure of real-world task dependencies; validation against empirical DAGs from code bases, workflows, or robotics is missing.
- Exploitation metric expressiveness: Exploitation error shows weak correlation with success; whether the current definition under-captures planning quality (e.g., suboptimal detours, late-stage dithering) and how to design more sensitive exploitation metrics is unresolved.
- Reproducibility across proprietary models: Heavy reliance on proprietary frontier models limits replicability; a thorough open-weight benchmark with matched harnesses/prompts and public datasets is not provided.
- Human or heuristic baselines: The absence of human or expert-heuristic baselines leaves it unclear how far LMs are from competent behavior on this task class and whether the metric aligns with human judgments of redundancy.
Practical Applications
Overview
This paper introduces a policy-agnostic metric and controllable environments to measure exploration and exploitation errors in LLM (LM) agents from action trajectories alone. The core innovations—symbolic task DAGs paired with partially observable maps, the stale-score–based error metric, and empirical findings on prompting and harness engineering—enable practical tools for building, testing, and operating agents in open-ended tasks. Below are concrete applications for industry, academia, policy, and daily life, grouped by deployment horizon.
Immediate Applications
The following applications can be deployed now with modest engineering effort, leveraging the released code and the paper’s metric, prompts, and harness patterns.
- Agent Evaluation in CI/CD (Software/AI Tooling)
- Use case: Integrate the exploration/exploitation error metric into continuous integration pipelines for coding agents, RPA bots, and tool-use LMs to catch regressions not visible in success rate alone.
- Tools/workflows: GitHub Actions for “Agent Eval CI”; plug-ins for LangChain/LlamaIndex/AutoGen; dashboards showing exploration/exploitation error and stale-score over time.
- Assumptions/dependencies: Access to action logs; mapping tasks to the grid+DAG testbed; acceptance that symbolic tasks complement (not replace) semantic benchmarks.
- Runtime “Stale Monitor” for Agents (Software Ops/AIOps, Security Ops)
- Use case: Monitor live agent sessions for no-progress loops using the stale score; automatically switch strategy, reset state, or escalate to a human when S_t rises.
- Tools/workflows: Agent watchdog services that read tool-call streams and trigger guards; MCP-compatible middlewares.
- Assumptions/dependencies: Reliable streaming of actions and state; policies for when to intervene; step-budget constraints.
- Prompt Strategy Libraries (Software, Workflow Automation, Web Navigation)
- Use case: Improve agent outcomes by switching between exploration-focused and exploitation-focused prompts at runtime based on the task phase (per Case 1–4 in the paper).
- Tools/workflows: “Prompt Switcher” middleware that inspects pending set and unobserved set to select prompts; prompt catalogs for exploration/exploitation/balanced modes.
- Assumptions/dependencies: Ability to detect target set conditions from the harness; prompt adherence by the model.
- Harness Engineering Templates (Enterprise Automation, Customer Support, DevOps)
- Use case: Reduce both error types by adding explicit state summaries (observed/unobserved cells, discovered/achieved nodes, pending tasks) as external memory for long-running agents.
- Tools/workflows: “Harness Kit” with JSON schemas; memory backends (SQLite, Redis, vector DB) and structured summaries injected into prompts; MCP tool adapters.
- Assumptions/dependencies: Stable memory store; cost/latency overheads for frequent state updates; data governance for stored context.
- Agent Behavior Analytics (Product/Model Ops)
- Use case: Analyze model-specific behavioral differences (e.g., explore-heavy vs exploit-heavy) among LMs that achieve similar success, to select the right model for a given task profile.
- Tools/workflows: Model comparison dashboards plotting success vs. exploration/exploitation error; quartile analysis over trajectory progress.
- Assumptions/dependencies: Representative task suites; consistent seeds and budgets across runs.
- Pre-Deployment Sandboxing for Regulated Domains (Healthcare, Finance, Cybersecurity)
- Use case: Test prototypes of triage, investigation, or guideline-navigation agents in a sandbox that mirrors domain workflows as DAGs; ensure agents don’t dither or prematurely exploit.
- Tools/workflows: Domain-specific DAGs (e.g., lab ordering/interpretation in healthcare; KYC/AML checks in finance; IOC gathering in SOC workflows); internal QA gates.
- Assumptions/dependencies: Manual DAG design or semi-automated extraction; human review of scenarios; isolation from live systems.
- Robotics Simulation Experiments (Robotics, Warehousing, Mobile Manipulation)
- Use case: Use the grid+DAG testbed to evaluate exploration/exploitation behavior of embodied LMs in sim before deploying on robots; compare harness variants and prompts.
- Tools/workflows: Integration with lightweight simulators; procedure libraries to map tasks to DAGs (e.g., pick→place→verify).
- Assumptions/dependencies: Sim-to-real gap; discretization of continuous spaces.
- Cost Control for Tool-Using Agents (Enterprise IT, Cloud Ops)
- Use case: Reduce redundant tool calls by triggering “no-progress” alerts and discouraging cyclical behavior; cut API and compute costs without sacrificing outcomes.
- Tools/workflows: Cost-aware stale-score thresholds; per-tool budgets; budgeting policies tied to S_t and gain.
- Assumptions/dependencies: Accurate metering; willingness to trade off thoroughness vs. cost.
- Education & Training (Academia, Bootcamps, Corporate Training)
- Use case: Teach exploration–exploitation trade-offs using the released environment; set labs where students tune prompts/harnesses and compare models.
- Tools/workflows: Course modules, Jupyter-based labs, contests; rubrics using success and error metrics.
- Assumptions/dependencies: Students can run frontier/open models; compute budget.
- Internal Procurement Criteria for Agent Tools (Policy/Compliance within Organizations)
- Use case: Require vendors to report exploration/exploitation errors alongside success rates during PoCs to avoid overfitting to success alone.
- Tools/workflows: Evaluation RFP annex specifying metrics and task variants.
- Assumptions/dependencies: Vendor cooperation; shared testbeds or reproducible logs.
Long-Term Applications
These applications require further research, scaling, domain adaptation, or standardization beyond the released artifacts.
- Domain-Standard Agent Test Suites with Semantics (Healthcare, Finance, Education, Energy)
- Use case: Build standardized, semantically grounded DAG+map benchmarks per sector (e.g., clinical pathways, audit workflows, learning progressions).
- Tools/products: Open benchmark collections and leaderboards; reference harnesses per domain.
- Dependencies: Community curation; privacy constraints; DAG extraction from real workflows.
- Adaptive Orchestration via Phase-Aware Meta-Controllers (Agent Platforms)
- Use case: Switch models, tools, or strategies dynamically based on detected phase (explore vs exploit) and stale-score trends; route exploration to broad-reasoning models and exploitation to precise executors.
- Tools/products: Meta-controllers in agent frameworks; policy learning with S_t as a signal.
- Dependencies: Robust phase detectors; cost/latency budgets; evaluation harnesses.
- Training Objectives that Internalize Exploration/Exploitation (Model Training, RLHF/DPO)
- Use case: Incorporate stale-score penalties and exploration gains into RL fine-tuning or preference optimization to reduce structurally redundant behavior.
- Tools/products: Synthetic curricula with procedurally generated DAG+maps; reward shaping modules.
- Dependencies: Access to training pipelines; stability of objectives; transfer to real tasks.
- Continuous-Space Generalization (Robotics, Autonomous Systems)
- Use case: Extend the metric beyond grids to continuous navigation/manipulation by discretizing beliefs or building topological graphs on-the-fly (e.g., from SLAM).
- Tools/products: Hybrid graph–metric-space representations; adapters for ROS/SLAM stacks.
- Dependencies: Real-time state estimation; safety constraints; calibration against real-world metrics.
- Safety Certification and Auditing for Agents (Policy/Regulation)
- Use case: Use exploration/exploitation error traceability in audits to show that agents avoid harmful dithering or risky exploratory actions; inform approvals and monitoring.
- Tools/products: Audit logs labeled with case types and stale-score evolution; compliance-report templates.
- Dependencies: Regulatory convergence; standardized reporting; secure logging.
- Auto-Harness Synthesis and Optimization (Software, Research)
- Use case: Learn or search for optimal harness designs (state schemas, memory policies) per task to minimize both errors and steps.
- Tools/products: “Meta-harness” optimizers using Bayesian optimization or neuro-symbolic search guided by the metric.
- Dependencies: Evaluation loops; stable signal-to-noise; on-policy/off-policy trade-offs.
- Agent UI Patterns for Human-AI Teaming (Product Design)
- Use case: Expose “pending tasks” and “unknowns” panels in copilots so users can nudge exploration vs exploitation; visualize stale loops in-session.
- Tools/products: UX components for DAG visualization and uncertainty maps; user controls for mode switching.
- Dependencies: Usability research; cognitive load considerations; privacy.
- Ensemble Agents with Division of Labor (Cross-Model Systems)
- Use case: Build ensembles where one agent specializes in exploration (discovering nodes) and another in exploitation (executing prerequisites), coordinated by shared harnesses.
- Tools/products: Inter-agent protocols; shared memory services; arbitration policies tied to S_t and gain.
- Dependencies: Robust synchronization; cost/latency budgets; conflict resolution.
- Energy/Cost-Aware Agent Planning (Enterprise, Cloud/Edge)
- Use case: Optimize resource usage by coupling stale-score–based penalties with scheduling, especially on edge or constrained devices; predict and avoid wasteful loops.
- Tools/products: Planners that co-optimize task success and action redundancy; edge-optimized harnesses.
- Dependencies: Accurate telemetry; multi-objective optimization; SLAs.
- Automated DAG Extraction from Real Workflows (All Sectors)
- Use case: Convert processes (e.g., SOPs, EHR guideline trees, SOP runbooks) into executable DAGs for agent planning and evaluation; keep “map” as information topology (systems, docs, APIs).
- Tools/products: DAG extractors from text and logs; human-in-the-loop validation tools.
- Dependencies: High-quality process documentation; access to event logs; NLP reliability.
- Procurement/Standards Bodies Adopt Metrics (Public Sector, Consortia)
- Use case: Establish performance baselines and certification regimes that include exploration/exploitation metrics to reduce deployment risks in critical systems.
- Tools/products: Standard test suites, scorecards, and disclosure requirements in model cards.
- Dependencies: Multi-stakeholder consensus; benchmarking infrastructure.
Notes on Feasibility and Assumptions
- Mapping real tasks to the paper’s grid+DAG abstraction may require manual or semi-automated DAG extraction; symbolic tests are complementary to semantic evaluations.
- The metric depends on high-granularity action logging and a notion of “observed vs. unobserved” information; some closed tools may limit observability.
- Results show that reducing exploration error is a strong predictor of success; however, optimal exploration must be balanced against time/cost constraints and safety policies.
- Harness engineering benefits assume stable external memory and well-structured summaries; poor harness design may degrade performance.
- Reintroducing semantic information can help or bias agents differently across models; domain pilots should A/B test with and without semantic cues before deployment.
Glossary
- Advice string: A concise piece of auxiliary information provided to an agent to guide its actions, often used in online graph exploration. Example: "Providing the harness explicitly is analogous to equipping the agent with an anchored map~\citep{dessmark2004} or an advice string~\citep{fraigniaud2008, dobrev2012}, where structured information about the environment is made directly available rather than requiring reconstruction from context."
- Anchored map: An explicit, structured representation of the environment given to an agent to avoid reconstructing state from history. Example: "Providing the harness explicitly is analogous to equipping the agent with an anchored map~\citep{dessmark2004} or an advice string~\citep{fraigniaud2008, dobrev2012}, where structured information about the environment is made directly available rather than requiring reconstruction from context."
- AND/OR preconditions: Logical dependency types on task nodes indicating whether all parents (AND) or at least one parent (OR) must be achieved before a node can be completed. Example: "Finally, each node has two types of preconditions: where AND indicates that all of its parent nodes must be achieved, and OR indicates that only one of its parent nodes needs to be achieved in order to achieve the current node (see Equation~\eqref{eqn:prec})."
- Cyclomatic number: A graph-theoretic measure of the number of independent cycles in a traversed subgraph, used here to quantify redundant looping. Example: "the cyclomatic number of the current no-progress trajectory."
- Exploitation error: A counted mistake where the agent fails to efficiently act on already-known, actionable information (e.g., not moving toward pending tasks). Example: "a weak relationship () between exploitation error and success rate."
- Exploration error: A counted mistake where the agent fails to efficiently acquire new information when exploration is required (e.g., not moving toward unobserved cells). Example: "In Figure~\ref{fig:success-vs-explore}, exploration error and success rate show a strong negative linear relationship ()"
- Gain: A binary indicator for an action that either moves into a target cell or shortens the distance to at least one target; otherwise the action is an error. Example: "We say that an action is a gain (Equation~\eqref{eqn:gain}) if it steps into a target cell or reduces the minimum distance to at least one of the target cells"
- Harness engineering: The design of external memory/state structures (the harness) to improve an agent’s long-horizon performance. Example: "both exploration and exploitation can be significantly improved through minimal harness engineering."
- No-progress trajectory: The segment of actions since the last meaningful advancement (achieving a pending task or entering an unobserved cell), used to detect redundant behavior. Example: "we define a no-progress trajectory $\tau_{\text{np}(t)$ as the sequence of actions since the most recent progress event"
- Partially observable map: An environment where only locally visited or revealed cells and transitions are known to the agent at any time. Example: "We define our partially observable map as the set of traversable cells in a 2D grid"
- Pending tasks: Discovered task nodes whose prerequisites are satisfied and locations are known, making them ready to be achieved. Example: "We define pending tasks which denotes the nodes in the task DAG with prerequisites satisfied and locations known, making them ready to be achieved"
- Policy-agnostic: Independent of any specific agent policy; evaluation relies only on observed behavior rather than internal strategies. Example: "we introduce a policy-agnostic framework for quantifying exploration and exploitation errors from action trajectories alone."
- Progress event: An event marking meaningful advancement, defined as either achieving a pending task or entering an unobserved cell. Example: "where a progress event is either achieving a pending task or entering an unobserved cell."
- ReAct: A prompting strategy that interleaves reasoning (thoughts) with acting (tool/environment interactions) for LM agents. Example: "Following the philosophy of ReAct~\citep{yao2023react}, we provide minimal information to the agent by default and assume that a skilled agent would maintain relevant context history and make rational decisions at each timestep."
- Semantic priors: Pretrained knowledge or assumptions derived from semantics that can bias or guide agent reasoning and exploration. Example: "effectively preventing conflation of semantic information from pretrained knowledge and semantic priors."
- Stale score: A redundancy metric combining loop closures and overuse of nodes/edges during no-progress periods to flag unproductive actions. Example: "Now we define the stale score and flag error when the stale score increases"
- Target set: The set of productive destination cells at a given timestep, comprising unobserved cells and/or locations of pending tasks. Example: "We refer to the set of productive destinations as the target set "
Collections
Sign up for free to add this paper to one or more collections.

