- The paper reveals a dramatic generalization collapse, with OCR models achieving >75% accuracy on Latin scripts but falling below 7.7% on low-resource scripts.
- It employs a comprehensive benchmark with clean and degraded image variants and robust metrics such as CER, Acc@5, and ScriptAcc across 158 Unicode scripts.
- The findings highlight systematic issues like script hallucination and reliance on attractor scripts, underscoring the need for dedicated pretraining on under-represented scripts.
GlotOCR Bench: Failure Modes and Generalization Gaps in Unicode-Scale OCR
Motivation and Context
Despite substantial advances in vision-LLMs, evaluation practice in OCR has overwhelmingly centered on Latin and a handful of high- and mid-resource scripts. Benchmarks such as OCRBench [liu2024ocrbench], CC-OCR [yang2025cc], and OmniDocBench [ouyang2025omnidocbench] systematically avoid the long tail of Unicode, leaving performance on minority, historical, and even some widely-used scripts essentially unstudied. This is non-trivial: the Unicode standard encodes over 170 scripts, with many in ongoing active use and many others critical for linguistic, historical, and cultural digitization.
GlotOCR addresses this systematic gap with a comprehensive benchmark covering 158 Unicode scripts. The dataset features both clean and heavily degraded image variants—synthetically rendered using Google Fonts, HarfBuzz, and FreeType engines from real multilingual texts. OCR models are prompted to transcribe these images, and their output is systematically analyzed using robust metrics in both character error rate (CER), approximate transcription acceptance (Acc@5), and script identification accuracy (ScriptAcc).
Dataset and Evaluation Protocol
Text for rendering was curated from broad-coverage datasets such as GlotLID [kargaran-etal-2023-glotlid], Wiktionary, WikiSource, and Omniglot, maximizing the coverage of genuinely attested sentences for each script. Font selection ensures glyph completeness and visual fidelity, with multiple levels of automatic filtering and human audit. Images are rendered in both a canonical clean version and a degraded format with perturbations designed to stress visual robustness, simulating artifacts from aging, scanning, and low-quality digitization.
Benchmarking encompasses both open-weight and proprietary models, including state-of-the-art systems such as Gemini 3.1 Flash-Lite, dots.ocr, GPT-4.1, and a selection from recent open-weight architectures (e.g., Qwen3-VL-8B, olmOCR-2, PaddleOCR-VL-1.5, etc.). All models are evaluated in zero-shot settings using uniform task prompts. Script-level resource tiering is defined: High (Latin), Mid (Arabic, Cyrillic, Devanagari, Han, etc.), and Low (the remaining long tail).
Main Results: Cross-Script Generalization Collapse
The primary empirical finding is a dramatic failure of generalization outside a circumscribed subset of Unicode scripts. While all models achieve >75% Acc@5 on Latin, and the strongest reach ~80% on mid-resource scripts, a sharp phase transition is observed for the remainder: on the 148 low-resource scripts, no current model exceeds 7.7% Acc@5 (even Gemini 3.1 Flash-Lite and dots.ocr), and most fall below 1%. This is not a smooth regression but a marked discontinuity, indicating threshold effects in pretraining coverage and intrinsic model limitations.
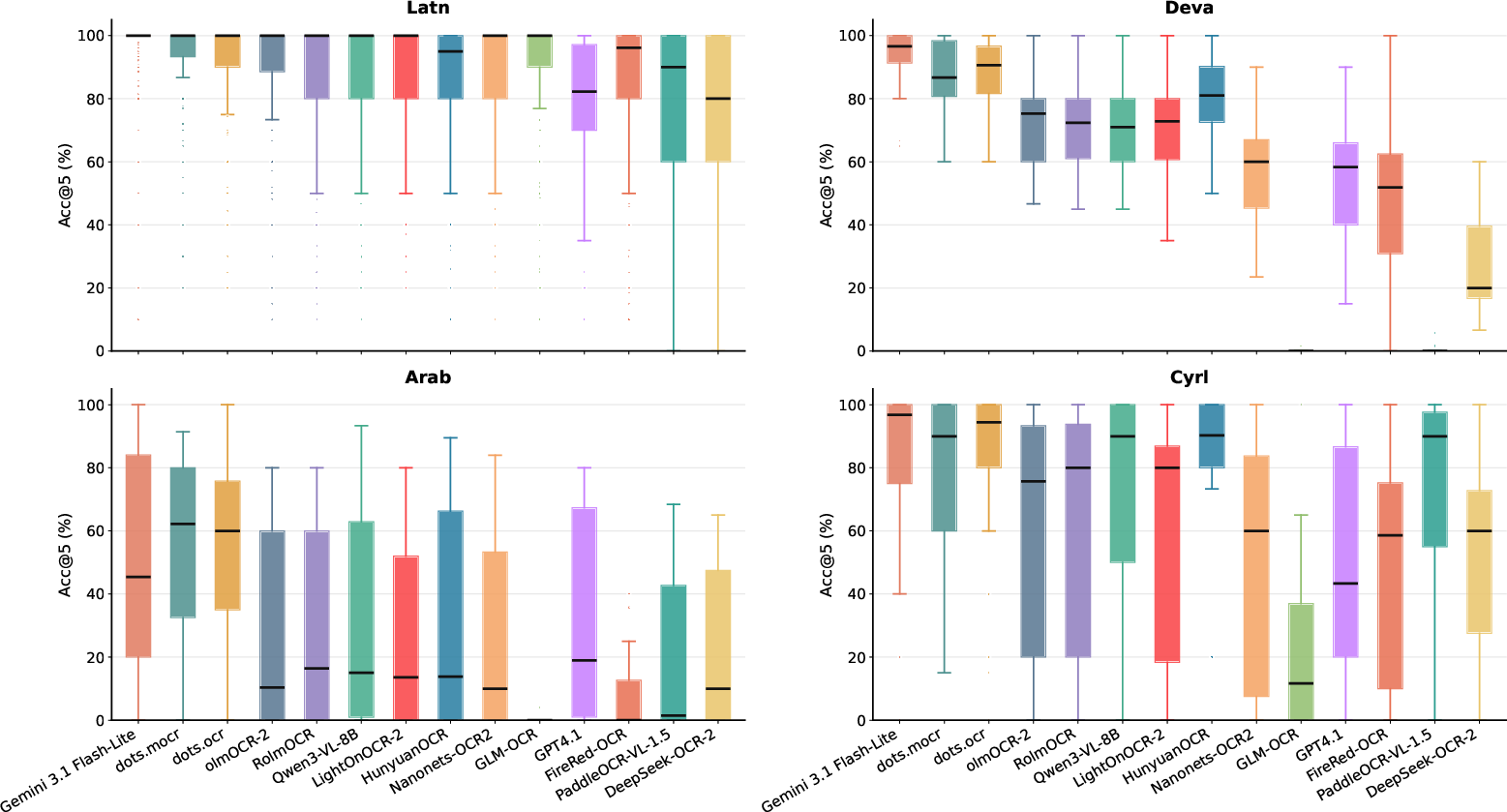
Figure 1: Acc@5 distributions for four scripts (Latin, Devanagari, Arabic, Cyrillic) reveal performance is highly script-dependent with catastrophic drops on scripts absent or under-represented in pretraining.
Within-script language-level variance further reveals that high aggregate script-level accuracy masks outlier failure on minority languages (e.g., less-exposed Latin-script languages are misrecognized even when the modal Latin is robustly handled). Arabic shows the steepest median degradation among mid-resource scripts, with error modes rooted in complex contextual shape and rendering ambiguities.
Script Recognition and Systemic Failure Patterns
A notable result is the decoupling between script recognition and actual transcription accuracy. There exists a strong rank correlation between ScriptAcc and Acc@5, but the presence of high ScriptAcc does not guarantee robust OCR: Arabic, for instance, provides high script recognition yet poor true reading accuracy due to intra-script ambiguity; Hebrew suffers substantial cross-script confusion (primarily with Thai), resulting in lower OCR effectiveness despite plausible lexicalization.
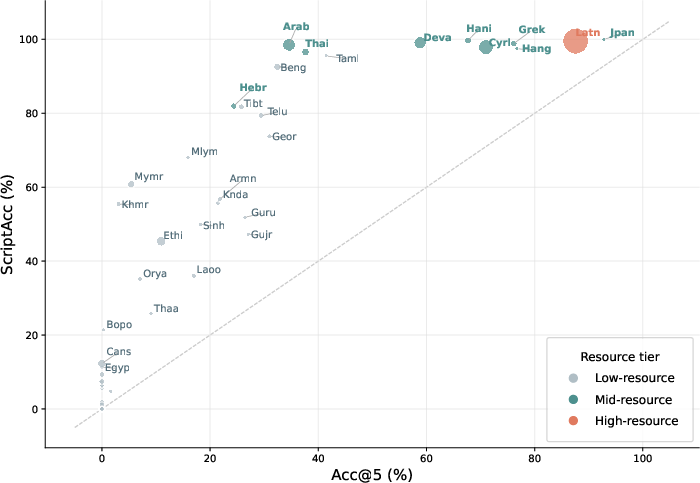
Figure 2: Script-level recognition accuracy (ScriptAcc) vs. OCR accuracy (Acc@5), showing that script recognition is necessary but not sufficient for successful generalization; bubble size ∝ log(number of languages per script), color encodes resource tier.
Model Response to Unfamiliar Scripts: Hallucination and Attractor Scripts
A major failure modality is cross-script hallucination. On unfamiliar scripts, mainstream systems rarely abstain; instead, they hallucinate outputs using the closest high-resource script in their training—e.g., rendering Gujarati as Devanagari, Coptic as Greek, Mongolian as Arabic. This is systematic and not random: attractor scripts (Latin, Arabic, Devanagari) serve as default output bases, reflecting their statistical dominance in both web data and model development cycles. Silent or artifact-only failures are much less common; the strongest open-weight models such as dots.ocr are more likely to abstain (with a ~42% silence rate), while most others emit output in unrelated but familiar scripts.
Script-aware hinting (providing explicit script or character information in the prompt) has minimal effect: for most scripts, Acc@5 remains unchanged, with mean gain across scripts +0.7pp for GPT-4.1, indicating that the bottleneck is not in script activation, but fundamental absence of visual recognition and token-level exposure.
Robustness to Image Degradation
Assessing clean vs. degraded image robustness, all models show performance drop under realistic synthetic noise, with relative loss correlating to resource tier. High-resource Latin drops moderately (up to ~20% in weaker models), while mid- and low-resource tiers, already near-zero, become essentially unsolvable under degradation. GPT-4.1 is more robust than other LMMs but the degradation gap cannot be overcome in under-represented scripts.
Implications and Theoretical Significance
Core empirical claims are:
- Current SOTA OCR models (both proprietary and open-weight) are effectively limited to ≤30 Unicode scripts by design, with a sharp and non-gradual collapse in long-tail or unseen scripts.
- Visual recognition and script identification are not separable: pretraining exposure, not only visual complexity, is the limiting factor for generalization.
- Script hallucination is the dominant failure; abstention is systematically avoided. Attractor scripts reflect both visual similarity and statistical frequency.
- Synthetic or domain-transform adaptation, such as script hinting, is not sufficient for closing the gap—the primary bottleneck is lack of script-specific pretraining or adaptation.
- Robustness to degradation tracks with both model architecture and script exposure but does not fundamentally alter the cross-script generalization outcome.
Future Directions
These results have substantial practical consequences for digital humanities, cultural heritage, and any application domain requiring robust OCR on minority, historical, and under-digitized scripts. The field requires a reframed research agenda: curated pretraining data for missing scripts, improved script identification and open-set recognition capabilities, and honest benchmarking that does not overstate generality by evaluating only on familiar scripts.
As models shift towards larger and more inclusive pretraining, direct community investment in Unicode-breadth data, script-agnostic architectural inductive biases, and robust abstention mechanisms for unfamiliar scripts will become necessary.
Conclusion
GlotOCR constitutes the first Unicode-scale, systematically curated, and reproducible OCR benchmark spanning 158 scripts and both clean and degraded imaging conditions. Its evaluation protocol and analysis uncover a stark, threshold-driven limitation of current SOTA OCR models: near-perfect performance is restricted to a narrowly defined subset of scripts, with the remainder essentially unsolved. Model failures are typified by confident hallucination in attractor scripts, not silence or artifact-only output, and script-aware hinting yields negligible improvement. The results substantiate the need for fundamental changes in data curation, pretraining, and architecture to enable general robust OCR. GlotOCR, with its public release of datasets, rendering pipelines, and evaluation code, defines a new standard for empirical rigor and inclusiveness in OCR research.



Figure 3: Example clean Greek-script GlotOCR image, illustrating high-fidelity rendering for mid-resource scripts.

