- The paper proposes a novel Latent-Condensed Attention approach that condenses distant context via group-wise semantic pooling and positional anchoring.
- It achieves up to 2.5× prefill speedup and a 90% reduction in KV cache while maintaining competitive accuracy even for 128K-length contexts.
- Empirical evaluations and ablations confirm that decoupled condensation effectively preserves essential token dependencies while reducing computational costs.
Latent-Condensed Transformer for Efficient Long Context Modeling
Introduction and Motivation
Transformer-based LLMs face two principal scalability bottlenecks when modeling long contexts: (1) the linear growth of the key-value (KV) cache memory required for storing past token representations during decoding, and (2) the quadratic computational complexity of full self-attention with respect to sequence length. Although Multi-head Latent Attention (MLA) partially ameliorates memory scaling by projecting tokens into a shared low-rank latent space, this approach does not resolve the quadratic attention computation since all latent tokens participate in dense attention. On the other hand, dynamic sparse attention techniques mitigate computational cost by selective sparsification post-hoc in the reconstructed high-dimensional space, thereby forgoing the benefits of native low-dimensional Latent-space reductions.
The proposed Latent-Condensed Attention (LCA) framework addresses these challenges by performing structured condensation and aggregation natively within the latent space produced by MLA, reducing both the KV cache and the attention computation without introducing additional parameters or resorting to information-destructive sparsification.
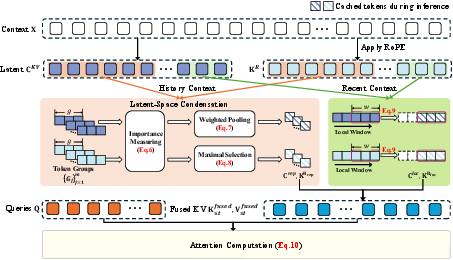
Figure 1: An overview of Latent-Condensed Attention (LCA). The history context is condensed into a compact set of representatives via group-wise condensation in the latent space: semantic information is aggregated through weighted pooling of CKV, while positional information is preserved via anchor selection from KR. The recent context is retained in full fidelity without condensation.
Methodology
Latent-Space Condensation
LCA is motivated by the observation that long-context sequences are highly redundant; typically, only a subset of tokens significantly contribute to model predictions. LCA partitions the distant context into contiguous groups. For each group, it separately aggregates the semantic component of the latent (via query-aware weighted pooling) and preserves the positional component by anchoring to the most relevant token. The disentangled processing of semantic and positional information is critical—direct pooling of positional encodings (e.g., RoPE features) leads to loss of essential sequence structure.
Semantic condensation minimizes reconstruction error within each group by leveraging attention-weighted pooling, which is theoretically shown to yield the optimal representative under expected squared error. For positional anchoring, LCA selects the token with maximal query relevance within each group, thus preserving precise positional cues required for accurate attention geometry.
A local window of recent latent tokens is kept uncompressed, ensuring preservation of fine-grained dependencies necessary for high-fidelity next-token prediction. The attention during inference and decoding is then performed over the set of groupwise representatives (for distant context) and the uncondensed local window, with the total number of KV-cache entries scaling as O(m+w) where m≪L is the number of context groups and w the local window size.
Theoretical Analysis
A uniform error bound is established: for any context length L, the ℓ2 deviation between the output of standard MLA attention and LCA is controlled by per-token key and value deviations within each group and is independent of L. This result demonstrates that LCA’s condensation does not accumulate unbounded error even as context length scales to 128K or more.
Implementation and System-Level Optimization
A kernel for LCA was implemented in Triton, yielding superior performance to the standard PyTorch baseline in real-world inference. The condensed computation schedule and reduced memory bandwidth maximization enable efficient scaling to million-token contexts.
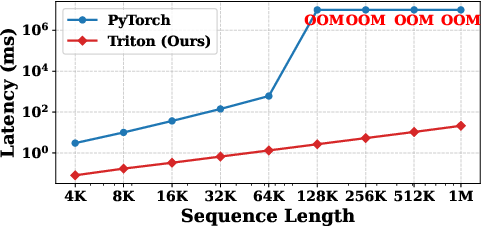
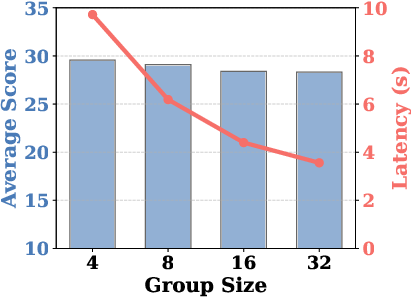
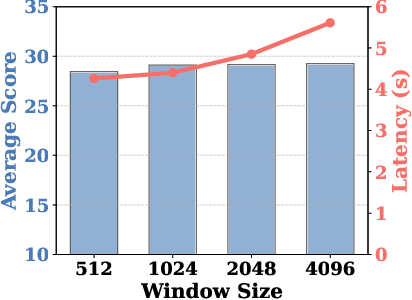
Figure 2: Latency comparison between the Triton kernel and PyTorch implementation, demonstrating drastic improvements for LCA-based long-context inference.
Empirical Results
Experiments were conducted on the DeepSeek V2-Lite (16B) and MiniCPM3-4B MLA-based models and also showed successful adaptation to GQA-based architectures. Evaluation covered extreme long-context benchmarks (LongBench-E, RULER at lengths up to 128K), as well as standard benchmarks (MMLU, GSM8K, MBPP) to ensure retention of near-field capabilities.
Numerical highlights include:
- Up to 2.5× prefill speedup at 128K context compared to MLA baseline.
- 90% KV cache reduction at 128K context.
- Competitive or even improved accuracy on long-context tasks (e.g., LongBench-E: LCA 29.09 vs. MLA 29.51; RULER@128K: LCA 24.38 vs. MLA 23.96).
- No meaningful degradation on standard short-context evaluations.
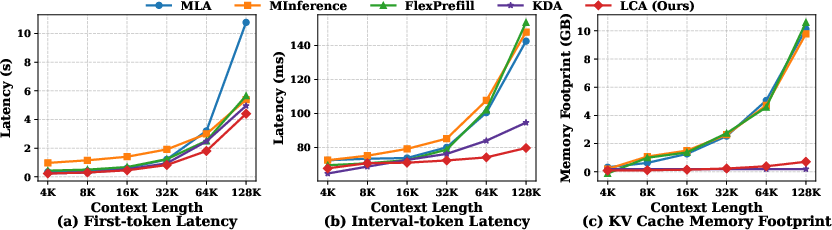
Figure 3: Efficiency comparison of different context lengths. (a) First-token generation latency; (b) Per-token (interval) latency; (c) GPU memory footprint of KV cache for LCA, MLA, and comparator methods, all showing substantial improvement for LCA.
LCA outperforms recent sparsification methods (FlexPrefill, MInference) in both numerical performance and robustness across long sequence regimes. Unlike linear-attention-style approaches, LCA achieves these gains without explicit parameterization or pretraining from scratch, and supports rapid integration via lightweight fine-tuning.
Ablation and Analysis
Extensive ablations demonstrate the necessity of the decoupled condensation: semantic weighted pooling and positional max-selection yield the highest accuracy, confirming the theoretical underpinnings. Larger local windows and smaller group sizes improve performance at the cost of efficiency, affording explicit control over the performance-efficiency tradeoff.
Empirical deviation measurements show that groupwise condensation maintains low average key/value representation error (sub-5% for both), supporting the effectiveness of the theoretical error bounds.
Implications and Future Directions
LCA demonstrates that native latent-space condensation is a practical, architecture-agnostic strategy for scaling attention models along both memory and CPU axes. Its reliance on exposed low-rank latent representations makes it compatible with any MLA- or GQA-style architecture and independent of full-dimensional reconstruction, opening avenues for its application in settings where memory and throughput constraints are prohibitive.
In practical terms, LCA substantially reduces inference costs and bandwidth in large-scale deployments, enabling full-document and multi-turn reasoning tasks with limited resources. On the theoretical side, it unlocks efficient surrogacy of full self-attention via optimal groupwise token summarization, and provides interpretable error-control parameters.
Further developments could consider fully adaptive group/window sizes, integration with learned or task-adaptive condensation heuristics, and combination with retrieval- or memory-based architectures for hybrid long-context reasoning.
Conclusion
Latent-Condensed Attention provides a principled and empirically validated solution to the dual bottlenecks of memory and computation in long-context LLMs. Its decoupled condensation of semantic and positional streams in latent space leads to significant efficiency improvements without meaningful performance reduction. LCA is both theoretically justified and practically scalable, suggesting it as a strong candidate for inclusion in future long-context models and as a template for further architectural innovations in efficient large-scale sequence modeling (2604.12452).