How Transformers Learn to Plan via Multi-Token Prediction
Abstract: While next-token prediction (NTP) has been the standard objective for training LLMs, it often struggles to capture global structure in reasoning tasks. Multi-token prediction (MTP) has recently emerged as a promising alternative, yet its underlying mechanisms remain poorly understood. In this paper, we study how MTP facilitates reasoning, with a focus on planning. Empirically, we show that MTP consistently outperforms NTP on both synthetic graph path-finding tasks and more realistic reasoning benchmarks, such as Countdown and boolean satisfiability problems. Theoretically, we analyze a simplified two-layer Transformer on a star graph task. We prove that MTP induces a two-stage reverse reasoning process: the model first attends to the end node and then reconstructs the path by tracing intermediate nodes backward. This behavior arises from a gradient decoupling property of MTP, which provides a cleaner training signal compared to NTP. Ultimately, our results highlight how multi-token objectives inherently bias optimization toward robust and interpretable reasoning circuits.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at how LLMs (like the ones that power chatbots) learn to “plan” their answers. The authors compare two ways of training these models:
- Next-token prediction (NTP): guessing just the next word.
- Multi-token prediction (MTP): guessing several upcoming words at once.
They show that MTP helps models think ahead better, especially on tasks that need step-by-step planning, and explain why this happens.
What questions were the researchers trying to answer?
- Why does predicting multiple future tokens at once (MTP) help models solve problems that need planning?
- Is MTP just avoiding a common training “shortcut,” or does it genuinely teach better reasoning?
- What exactly happens inside a Transformer (the model’s architecture) when it’s trained with MTP that makes planning easier?
How did they study it?
To keep things clear and fair, the researchers used both experiments and math:
- They tested models on puzzles that need planning:
- Star graph path-finding: like choosing the correct path from a start node to a goal when only the first choice is hard.
- Binary tree path-finding: like a branching maze where every step requires a decision (no shortcuts).
- Countdown (like a numbers game where you combine numbers to hit a target).
- SAT (a classic logic puzzle about making true/false choices to satisfy rules).
- They compared training with:
- NTP (predict the next token).
- MTP (predict the next several tokens in parallel).
- They analyzed a simplified Transformer mathematically to understand the learning process. They used easy-to-understand analogies:
- Tokens are like words or symbols.
- “Heads” are like separate guessers that all look at the same context.
- “Gradients” are the feedback signals that tell the model how to adjust.
- “Layers” are steps in the model that process information.
A key idea they studied is “reverse reasoning”: solving a path by looking at the goal first and then working backward—like solving a maze by starting at the exit and tracing your way back to the start.
What did they find, and why is it important?
Here are the main takeaways:
- MTP helps models plan better than NTP:
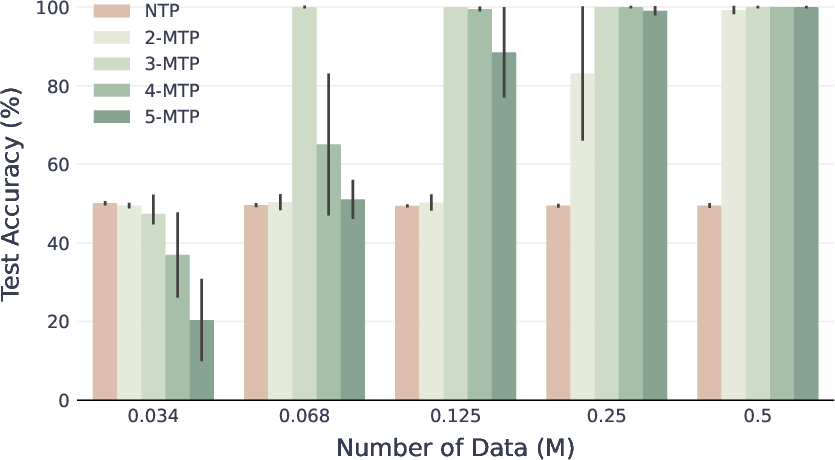
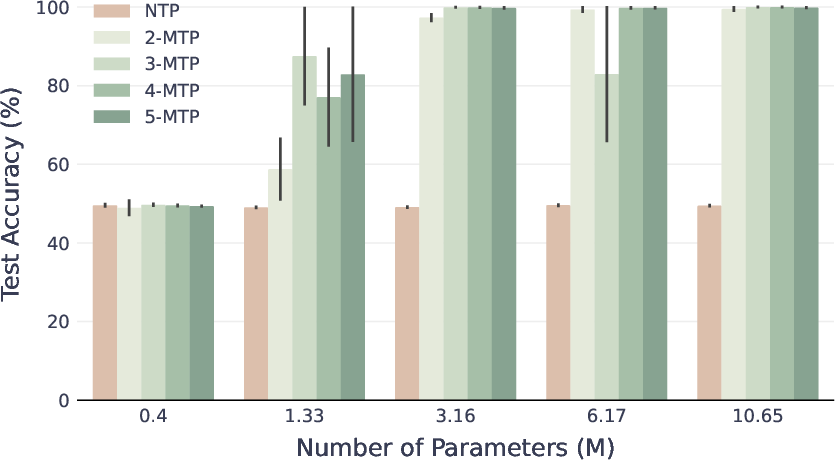
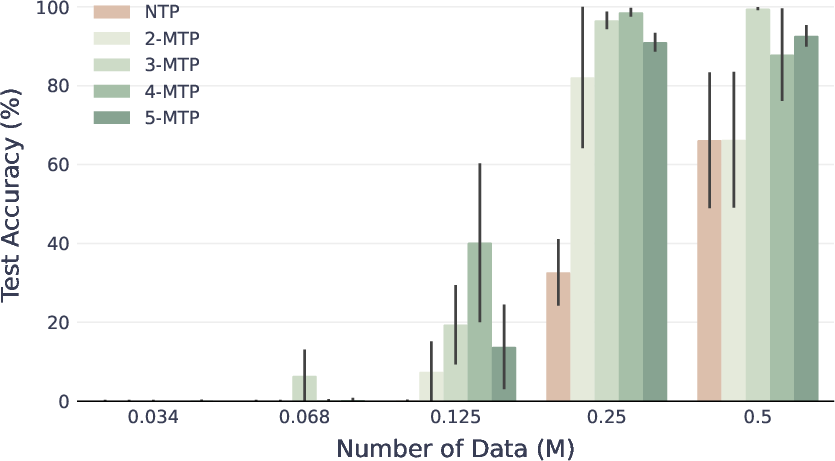
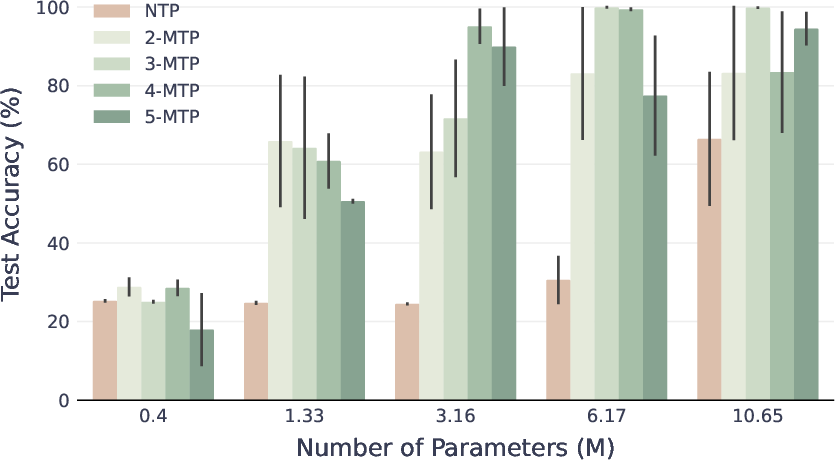
- On star graphs, models trained with MTP found the correct path far more often than those trained with NTP. Even predicting just one extra future token (k=2) was enough to jump to perfect accuracy in some settings where NTP stayed stuck around 50%.
- On binary trees—where simple shortcuts don’t work—MTP still beat NTP, especially when data or model size was limited.
- On real reasoning tasks (Countdown and SAT), MTP consistently gave higher accuracy than NTP.
- MTP doesn’t just “avoid cheating”—it changes how the model learns:
- In teacher-forced training, NTP can “cheat” by using previously revealed correct tokens to guess the next one, instead of learning the real logic (this is sometimes called the “Clever Hans” effect).
- The team designed tasks (like the binary tree) where this cheat doesn’t work—and MTP still did better.
- That means MTP isn’t just fixing a training trick; it’s genuinely encouraging deeper reasoning.
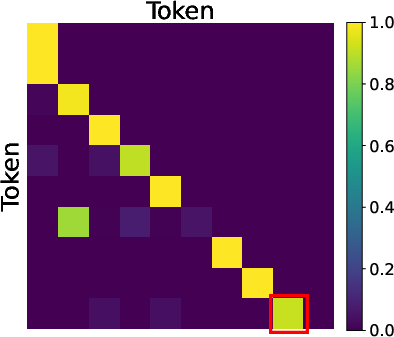
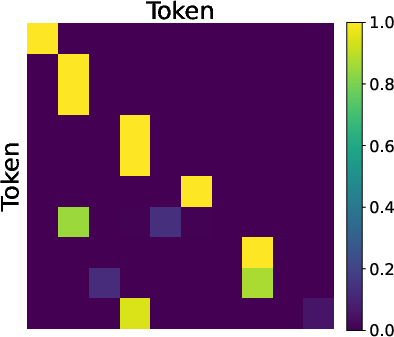
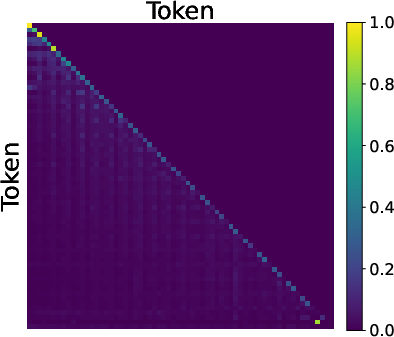
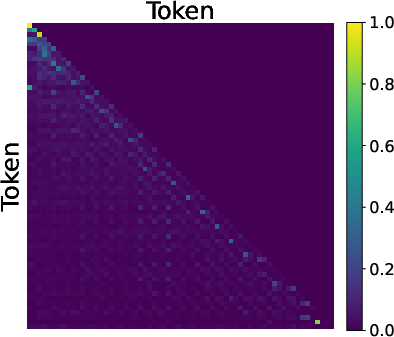
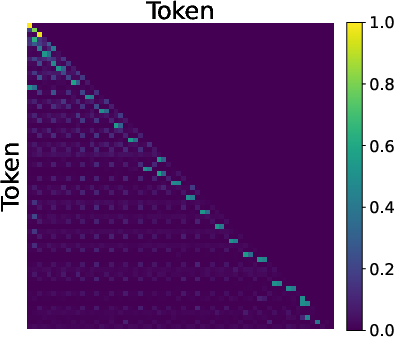
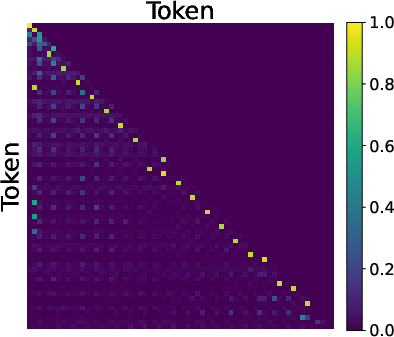
- Inside the model, MTP leads to a two-step “reverse reasoning” process:
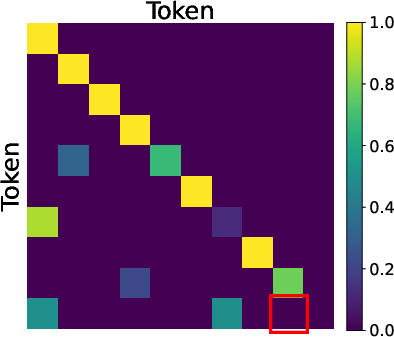
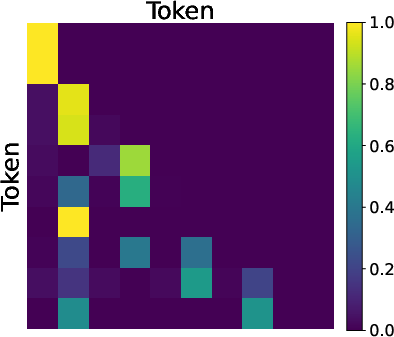
- Step 1: The model learns to focus on the goal (the end node).
- Step 2: It traces back the path step-by-step, reconstructing the route backward.
- This happens because MTP gives “cleaner” feedback signals. Think of it like having two teachers: one teaches the first step clearly without interference, and then another teaches the next step. This “gradient decoupling” helps the model learn each piece in the right order.
- With NTP, the feedback gets mixed together, making it harder for the model to discover the backward-tracing strategy.
- A simple math model shows why:
- In a two-layer Transformer, MTP first teaches the early layer to point to the goal position, then teaches the next layer to reconstruct the path. NTP struggles because its feedback pushes attention in the wrong direction at the start.
Why this matters:
- Planning is central to hard tasks (math, logic, code). MTP gives models a built-in push to plan better.
- The reasoning patterns that emerge under MTP are more “interpretable”—you can see the model focusing on the goal and tracing backward—making it easier to understand and trust.
What does this mean for the future?
- Training with MTP can make LLMs better at multi-step reasoning, not just faster at generating text.
- It suggests that choosing the right training objective (what you ask the model to predict) can be as important as the model’s architecture when it comes to teaching reasoning.
- This could lead to better models for math, coding, and planning-heavy tasks, and inspire new training methods that encourage clear, step-by-step logic.
- The paper’s theory focuses on a simple two-layer setup and specific graph tasks; future work could extend this to deeper models, more complex graphs, and other multi-step training designs.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, stated concretely to guide future research.
- Extend theory beyond a two-layer disentangled Transformer to standard LLM architectures (multi-head attention, separate Q/K/V, residual connections, layer norm, MLPs, tied output heads).
- Analyze whether the gradient decoupling mechanism persists with shared or tied output heads (common in practice) rather than independent heads.
- Generalize theoretical results from the 2-path, 3-node star graph to:
- deeper paths (multi-hop beyond 2),
- larger branching factors,
- cyclic/loopy graphs,
- weighted or labeled edges,
- and general graph topologies.
- Provide finite-time convergence guarantees (rates, dependence on data size, model size, and initialization) rather than asymptotic gradient-flow arguments.
- Characterize the basin of attraction and stability of the “reverse reasoning” circuit under realistic training (SGD/Adam, finite steps, noise, weight decay, dropout, layer norm).
- Determine whether reverse reasoning is the unique attractor under MTP or whether alternative circuits can emerge and under what conditions.
- Formalize how lookahead length k affects:
- which reasoning circuit is learned,
- optimization stability,
- sample complexity,
- and diminishing returns or interference as k grows.
- Give principled guidance on choosing k relative to task horizon and path length; identify minimal k needed for various planning depths.
- Study head-weighting schedules (loss weights across lookahead heads) and their effect on layer-wise gradient routing and planning emergence.
- Analyze sequential MTP variants (e.g., DeepSeek-style) and whether they exhibit the same decoupling and reverse reasoning phenomena.
- Examine whether the gradient decoupling property survives in architectures with shared vocabulary projection or embedding tying.
- Quantify gradient signal-to-noise improvements from MTP (variance, bias) relative to NTP across layers and tasks; provide general conditions for decoupling.
- Evaluate robustness of the reverse reasoning mechanism under different positional encodings (RoPE, ALiBi) without assuming Toeplitz structure.
- Remove modeling simplifications used in the proof (e.g., fixing W0(1)=0, block-sparse/selector heads) and assess whether results hold in less constrained settings.
- Provide theoretical and empirical analysis when content and position cues are both learnable early (no staged freezing); does decoupling still yield the same circuit?
- Investigate how MTP behaves under free-running decoding (no teacher forcing) and with sampling/beam search; assess exposure-bias effects post-training.
- Test generalization to substantially longer sequences, larger graphs, and deeper planning horizons than those reported; quantify scaling laws for planning accuracy.
- Stress test for spurious shortcuts beyond the “Clever Hans” effect (e.g., positional or formatting cues) and demonstrate that MTP’s gains persist under adversarial prompting or randomized formats.
- Provide ablations isolating contributions of lookahead vs. other factors (data curriculum, prompt structure, head independence) to confirm causal role of MTP.
- Compare MTP with teacherless/implicit-label objectives (e.g., masked diffusion LMs, masked LM, scheduled sampling) on the same planning tasks to disentangle objective-specific benefits.
- Explore interactions between MTP and chain-of-thought supervision: does MTP reduce reliance on external CoT, or do they compound benefits?
- Validate on broader, real-world reasoning suites (GSM8K, MATH, MBPP, SATLIB) and with larger models to assess external validity and scaling.
- Report compute/efficiency trade-offs: does MTP’s added training cost yield net gains at fixed compute budgets; how do benefits change with longer contexts?
- Examine inference-time use of multi-head predictions (parallel generation) and its impact on planning quality versus the paper’s choice of using only the first head.
- Characterize when MTP’s reverse reasoning bias might be harmful (tasks demanding forward simulation rather than backchaining); develop diagnostics to detect mismatch.
- Study task distributions for Countdown and SAT (difficulty, clause distributions, tokenization) and evaluate out-of-distribution generalization (larger targets, clause counts, noise).
- Analyze multi-objective conflicts among heads as k increases (gradient interference) and propose optimization strategies (e.g., PCGrad, dynamic reweighting).
- Provide theoretical sample-complexity comparisons between MTP and NTP for planning tasks under explicit data models.
- Investigate stability of the learned circuit under domain shifts (graph topology changes, added distractor edges, noisy labels).
- Measure calibration and uncertainty under MTP versus NTP, particularly for multi-step planning outputs.
- Explore combining MTP with search-time methods (Tree-of-Thoughts, SoS) and RL fine-tuning; quantify complementarity and interference.
- Release code and detailed configurations for reproducibility of minimal and full-model experiments, including ablations referenced in appendices.
Practical Applications
Immediate Applications
Below are concrete ways to apply the paper’s findings now, emphasizing sectors, potential tools/workflows, and feasibility notes.
- Industry (Software/AI): Improve planning and reasoning in LLMs by adopting parallel multi-token prediction (MTP) during training
- What: Add 2–7 independent lookahead heads (k≥2) to the training loss while keeping standard next-token inference at deployment.
- Tools/workflows: Extend Hugging Face Transformers/Megatron-LM/DeepSpeed training loops with parallel heads; loss weighting and early stopping; evaluation on planning-heavy suites (e.g., star/binary tree, Countdown, SAT).
- Dependencies/assumptions: Modest extra training compute/memory for multiple heads; strongest gains on tasks requiring multi-step planning; benefit size varies by k and dataset.
- Industry (Agents/RPA, IT Ops): More reliable task-planning agents
- What: Fine-tune agent planner modules with MTP on datasets of multi-step workflows (e.g., incident response runbooks, ticket triage, IT playbooks).
- Tools/workflows: LangGraph/CrewAI + planner model trained with MTP; ensure datasets include target/goal tokens so the model can “reverse reason.”
- Dependencies/assumptions: Requires curated plan datasets; ensure inference uses first head only (as in the paper) and that evaluation measures goal-consistency.
- Software Engineering: Better stepwise code assistants and refactoring tools
- What: Train code LLMs with MTP on edit/commit sequences, multi-step bug fixes, or multi-function implementations.
- Tools/products: IDE plugins (VS Code/JetBrains) backed by MTP-trained models; CI bots that plan multi-step fixes; program synthesis with explicit plan tokens.
- Dependencies/assumptions: Availability of multi-step code-edit corpora; maintain balance with standard NTP to avoid degrading generic code completion.
- Data/Analytics (BI/SQL): Planning for query decomposition and multi-step pipelines
- What: Fine-tune LLMs with MTP on task decomposition (SQL → subtasks → joins → final query) and pipeline orchestration.
- Tools/workflows: Auto-ETL and data orchestration copilot that plans backwards from final metrics/SLAs.
- Dependencies/assumptions: Requires high-quality chain-of-steps data; interface with validators to enforce plan correctness.
- Education (Tutoring): More coherent step-by-step problem solving
- What: Train math/logic tutors with MTP on curricular datasets (algebra proofs, equation systems, logic puzzles).
- Tools/products: Tutors that better plan multi-step explanations; use Countdown-like curricula to reinforce reverse reasoning.
- Dependencies/assumptions: Ground-truth step solutions must be accurate; evaluation should emphasize end-goal consistency.
- Product Design/UX (Personal Assistants): More dependable itineraries and chore planning
- What: Fine-tune assistants with MTP on itinerary/task-list datasets that include explicit goals and constraints.
- Tools/products: “Plan-first” mode that drafts full solution internally before emitting the first step.
- Dependencies/assumptions: Data must capture goal tokens and feasible paths; verification hooks for constraints (calendar availability, travel times).
- Robotics/Automation (Near-term prototyping): Language-conditioned planners for discrete, symbolic tasks
- What: Apply MTP to sequence models that output discrete action plans from goals/descriptions (assembly steps, checklist tasks).
- Tools/workflows: Decision Transformer-style training with multi-horizon token targets; simulators for data generation.
- Dependencies/assumptions: Works best for symbolically structured tasks; continuous control requires additional adaptation (see long-term).
- Safety & Interpretability: Training-time diagnostics for “reverse reasoning”
- What: Monitor whether attention heads attend to goal tokens and predecessor positions, as predicted by the gradient decoupling theory.
- Tools/workflows: Dashboard probes that quantify goal-attention and predecessor-pointing; regressions in these metrics trigger alerts.
- Dependencies/assumptions: Interpretability patterns may vary across architectures; probes need calibration per model.
- Academia (ML Research/Education): Reproducible labs on planning and optimization dynamics
- What: Use the paper’s star/binary-tree/Countdown/SAT setups to teach and study reasoning circuits and MTP vs NTP dynamics.
- Tools/workflows: Assignments and ablations (vary k, heads, loss weights); integrate small two-layer models and attention heatmap analyses.
- Dependencies/assumptions: Simplified tasks generalize qualitatively, but quantitative results differ for larger models.
- Formal Methods/Verification: Hybrid LLM+solver workflows
- What: MTP-trained models propose consistent multi-step candidate solutions/assignments for SAT/SMT that a solver verifies/refines.
- Tools/workflows: Loop: LLM plan → solver check → feedback data for further MTP fine-tuning.
- Dependencies/assumptions: Gains shown on 3-SAT likely require careful domain adaptation for broader formula classes.
- Enterprise MLOps: Training recipes and benchmarking of planning ability
- What: Add MTP as a first-class configurable objective; track planning benchmarks and “goal-attention” metrics alongside perplexity.
- Tools/workflows: W&B dashboards; CI gating using pathfinding and Countdown tests; loss schedules that emphasize shallow head early.
- Dependencies/assumptions: Metric trade-offs versus standard language modeling KPIs; need for domain-relevant planning tests.
- Policy & Procurement: Evaluation guidance for planning-critical AI
- What: Require disclosure of training objectives (NTP vs MTP) and performance on planning benchmarks for AI systems used in decision pipelines.
- Tools/workflows: Standardized benchmark packs (graph tasks, SAT variants) in solicitations; documentation of interpretability audits.
- Dependencies/assumptions: Policies must remain model-agnostic and focus on measurable planning reliability.
Long-Term Applications
These opportunities likely require additional research, scaling, domain adaptation, or tooling maturity.
- Multimodal Agents (Robotics, Vision-Language): Reverse-reasoning planners for continuous control
- What: Extend MTP to learn multi-horizon, goal-conditioned trajectories (navigation, manipulation) with image/sensor inputs.
- Tools/workflows: Multimodal tokenization strategies; offline RL datasets with explicit goals; hybrid trajectory/skill tokens.
- Dependencies/assumptions: Requires robust tokenization of continuous spaces and safety validation in real environments.
- Healthcare (Clinical Pathways): Goal-consistent care-plan generation
- What: Use MTP-trained models to plan from desired outcomes (e.g., discharge criteria) backwards through interventions.
- Tools/workflows: Integrations with EHRs, guideline databases; verification via clinical decision support.
- Dependencies/assumptions: Strict regulation, explainability, and randomized trials; curated labeled pathways.
- Energy & Utilities: Grid and maintenance planning with backward constraints
- What: Plan maintenance/dispatch sequences by reverse reasoning from reliability targets and constraints.
- Tools/workflows: LLM+optimizer hybrids; MTP fine-tuning on historical operations with goal annotations.
- Dependencies/assumptions: Domain constraints must be hard-enforced; datasets are sensitive and sparse.
- Logistics & Supply Chain: Backward-feasible routing and scheduling
- What: LLM planners that start from delivery windows and reverse-plan tasks across fleets or warehouses.
- Tools/workflows: Co-optimization with OR solvers; scenario simulators to create training data with explicit goals.
- Dependencies/assumptions: High-fidelity simulators and data sharing with privacy guarantees.
- Software Engineering (Program Synthesis/Verification): Backward search from specifications
- What: MTP-trained synthesis models plan from specs to implementations, verified by compilers and test harnesses.
- Tools/workflows: Integration with formal verifiers and fuzzers; guided backward-refinement loops.
- Dependencies/assumptions: Large curated datasets linking specs, tests, and code; careful safety constraints.
- Finance (Risk & Compliance): Backward planning from risk targets
- What: Generate remediation roadmaps (e.g., stress test outcomes → risk mitigations) via reverse reasoning.
- Tools/workflows: Compliance playbooks; human-in-the-loop audits; integration with scenario models.
- Dependencies/assumptions: High governance standards; domain data and regulatory approval.
- Architecture/Optimization Co-Design: Training/architecture patterns that exploit gradient decoupling
- What: Design modular “shallow goal heads” and curricula that explicitly stage learning (first positional/backward attention, then content).
- Tools/workflows: Two-phase schedules that freeze/unfreeze layers as per the theory; automated head selection.
- Dependencies/assumptions: More studies on stability, generalization, and trade-offs with generic language modeling.
- New Objectives Beyond MTP: Future-summary or hierarchical planning losses
- What: Train models to output summaries of future steps or hierarchical plans (subgoals) from the same prefix.
- Tools/workflows: Multi-granularity heads; mixture-of-objectives; structured plan tokens.
- Dependencies/assumptions: Requires dataset curation for subgoals and plan hierarchies; careful balancing with NTP.
- Safety & Governance: Interpretability standards around planning circuits
- What: Standardize probes for goal-attention and predecessor-pointing; certification that models exhibit interpretable planning behavior.
- Tools/workflows: Auditing suites and reporting templates; stress tests for spurious “Clever Hans” behaviors.
- Dependencies/assumptions: Agreement on metrics and thresholds; incentives in regulatory frameworks.
- Benchmarking Standards: Planning-centric leaderboards for LLMs
- What: Establish widely adopted benchmarks that include star/binary tree variants, SAT families, and arithmetic planning.
- Tools/workflows: Public datasets, baselines, and attention-pattern diagnostics; compute-efficient leaderboards.
- Dependencies/assumptions: Community buy-in; reproducible protocols that reflect real-world planning.
- Real-Time Systems: Parallel generation leveraging MTP for latency-critical tasks
- What: Combine training-time MTP with inference-time parallel decoding or speculative strategies for faster plan draft generation.
- Tools/workflows: Masked/parallel decoding algorithms adapted to MTP heads; caching and beam mechanisms.
- Dependencies/assumptions: Algorithmic maturity and stability; careful handling of coherence across parallel predictions.
- Curriculum/Data Engineering: Goal-first data pipelines
- What: Build datasets that surface targets early (e.g., goal tokens) to encourage reverse reasoning and reduce “Clever Hans” shortcuts.
- Tools/workflows: Data transformation rules; synthetic pathfinding/logic curricula blended with domain corpora.
- Dependencies/assumptions: Avoid distribution shift; maintain task diversity to preserve general skills.
Notes common to many applications:
- The paper’s strongest theoretical results are for simplified two-layer settings and star graphs; empirical improvements extend to Countdown and SAT but larger, real-world systems require validation.
- Benefits are largest for planning-heavy tasks; for generic chat or knowledge recall, trade-offs may exist and should be measured.
- MTP increases training complexity and may need careful loss balancing; inference can remain standard NTP to avoid latency increases.
- Datasets that expose goals and multi-step structure are critical to realize the “reverse reasoning” benefits.
Glossary
- Autoregressive (AR): A generation scheme where each token is predicted conditioned on previously generated or ground-truth tokens. Example: "the model must predict the path $( u_\mathrm{star}, v, u_{\mathrm{end})$ autoregressively."
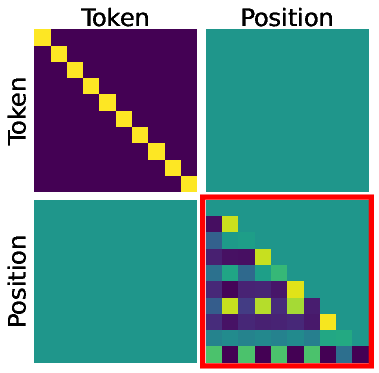
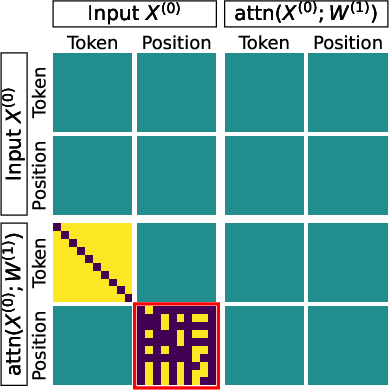
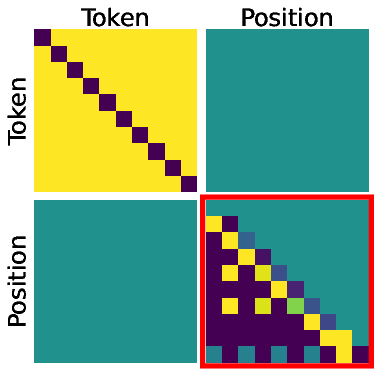
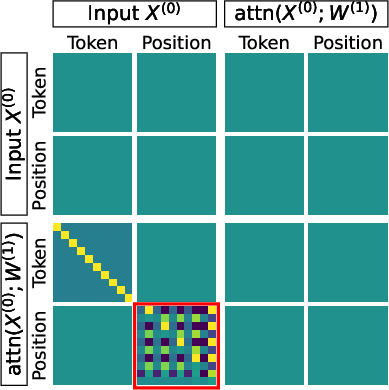
- Block-diagonal: A matrix structure composed of independent square blocks along the diagonal; here it separates content and positional attention components. Example: "The attention weights decompose block-diagonally:"
- Block-sparse: A sparsity pattern where nonzero entries are concentrated in specific blocks, with many zeros elsewhere. Example: "These block-sparse structures motivate the reduced model in Section~\ref{sec:prob_model}."
- Causal prefix: The sequence of past tokens available to a model under causal masking when predicting the next token. Example: "given its full causal prefix:"
- Causal self-attention head: An attention mechanism constrained to attend only to previous (causal) positions. Example: "Definition [Causal self-attention head]"
- Chain-of-thought: A prompting or modeling approach that elicits intermediate reasoning steps to solve problems. Example: "the role of chain-of-thought~\citep{feng2023cot,kim2025transformers,huang2025transformers}"
- Clever Hans cheat: A spurious shortcut where a model uses revealed answer tokens in teacher-forced prefixes instead of learning the true reasoning algorithm. Example: "a phenomenon known as the Clever Hans cheat"
- Content matching: An attention mechanism that identifies positions by matching token identities rather than positions. Example: "Content Matching (Layer 2, Last Row):"
- Countdown: A numerical reasoning task requiring combining given numbers with operations to reach a target value. Example: "Countdown is a generalized version of the Game of 24."
- Disentangled Transformer: A Transformer abstraction that separates content and positional representations into distinct subspaces for analysis. Example: "two-layer disentangled Transformer on the star graph task."
- Gradient decoupling: A property where gradients for different layers or heads are isolated, providing cleaner, layer-specific learning signals. Example: "This behavior arises from a gradient decoupling property of MTP"
- Gradient flow: The continuous-time limit of gradient descent dynamics used to analyze optimization trajectories. Example: "Consider the MTP loss under gradient flow."
- Jacobian: The matrix of partial derivatives of a vector-valued function; here, the derivative of the softmax distribution. Example: "we write J(s) := \mathrm{diag}(s) - ss\top for its Jacobian."
- Lookahead: In MTP, the number of future tokens predicted in parallel from a given prefix. Example: "MTP with lookahead instead predicts the next tokens in parallel"
- Predecessor pointing: An attention pattern focusing on the immediately preceding position, enabling backward tracing of paths. Example: "Predecessor Pointing (Layer 1):"
- Reverse reasoning: A planning strategy that starts from the goal and works backward to reconstruct intermediate steps. Example: "We prove that MTP induces a two-stage reverse reasoning process: the model first attends to the end node and then reconstructs the path by tracing intermediate nodes backward."
- RoPE (Rotary Positional Embeddings): A positional encoding method that rotates token representations to encode relative positions. Example: "has RoPE (Toeplitz) structure"
- Stationary point: A parameter setting where the gradient of the objective vanishes (not necessarily a minimum). Example: "The model achieves a stationary point for both the shallow loss"
- Strictly lower shift matrix: A matrix with ones on the first subdiagonal (and zeros elsewhere) that shifts vectors backward by one position. Example: "strictly lower shift matrix with and zero elsewhere."
- Teacher forcing: A training technique that feeds ground-truth tokens as inputs at each step, regardless of the model’s predictions. Example: "Next-token prediction (NTP) with teacher forcing has long been the standard objective for training LLMs,"
- Teacherless training: A training setup that withholds ground-truth prefixes, preventing reliance on revealed answers. Example: "\citet{bachmann2024pitfalls} further introduced teacherless training to eliminate the Clever Hans Cheat"
- Toeplitz structure: A matrix form where entries depend only on the difference of indices, commonly modeling translation-invariant patterns. Example: "has RoPE (Toeplitz) structure "
Collections
Sign up for free to add this paper to one or more collections.

