- The paper presents a novel method using multidimensional simplex transformations to reduce noise variance in differentially private linear regression.
- It optimally combines independent unbiased estimators via inverse-variance weighting to achieve up to 4.8× variance reduction in critical statistics.
- Empirical and analytical evaluations demonstrate substantial improvements over traditional methods while preserving rigorous privacy guarantees.
Refined Differentially Private Linear Regression via Extension of a Free Lunch Result
Introduction and Problem Setting
The paper addresses the challenge of performing linear regression under differential privacy (DP) in the stringent add/remove (unbounded) DP model, which mandates that even the dataset size is private. Classical private regression approaches typically add independent calibrated noise to each sufficient statistic, resulting in high-variance and poor utility, particularly under tighter privacy budgets (ε small) or small datasets. This problem is exacerbated in the add/remove setting, as all relevant quantities—including dataset size—must be privately estimated.
Prior work demonstrated that "free lunch" simplex transformations allow private estimation of dataset size in [0,1]-bounded data for zero additional privacy cost, leveraging the summing of variables and their complements. This work generalizes that insight, introducing multidimensional simplex transformations to enable refined, multiple, independent estimators of core regression statistics (e.g., Sx2,Sxy). These can be optimally combined for substantially reduced estimation variance, directly improving the accuracy of the privatized regression parameters.
Standard approaches for private linear regression fall broadly into two categories:
- Sufficient Statistics Perturbation (DP-SS): Adds independent Laplace noise to key sums (e.g., Sx,Sy,Sxy,Sx2), split across the privacy budget. The add/remove model makes this more challenging, as even n must be privately estimated, incurring more noise.
- Robust Estimation via DP-Theil-Sen: Uses robust, median-based procedures with privatized selection (e.g., exponential or median mechanisms), but typically exhibits high variance at tight privacy levels.
- DP-SGD and Extensions: While effective in large-data or low-sensitivity regimes, these approaches are fragile under add/remove adjacency and often difficult to tune precisely in practice.
Prior work leveraging simplex structures for zero-cost dataset size estimation [kulesza2024, fitzsimons2024] inspired this work, but their results were not previously used for variance reduction in sufficient statistic estimation beyond n.
The methodological core is the use of algebraic simplex decompositions to map each (xi,yi)∈[0,1]2 into multiple components whose totals are invariant and whose sum is $1$. For the x-coordinate and (x,y)-joint statistics, the transformations are:
- [0,1]0
- [0,1]1
Summing these across all records yields two groups of three statistics, each with [0,1]2-sensitivity exactly [0,1]3, permitting efficient privatization via the Laplace mechanism.
Each sufficient statistic of interest can be estimated in two independent ways: directly (e.g., [0,1]4 is a primary component) and indirectly (e.g., [0,1]5). Since the privatization noises used in these paths are independent, the resulting estimators are likewise independent. Applying inverse-variance weighting, one obtains a refined, optimally-weighted estimator for each statistic.
Optimal Combining of Private Estimators
For each statistic, two independent unbiased estimators [0,1]6 and [0,1]7 are combined as [0,1]8 with optimal weights [0,1]9 (where Sx2,Sxy0 is variance). The variance reduction is dramatic, especially for quadratic statistics Sx2,Sxy1, achieving up to Sx2,Sxy2 lower variance compared to the baseline method that adds independent noise per statistic.
These improvements are achieved without sacrificing privacy, since all post-processing is DP-immune. The mechanism preserves the global budget split between the two transformation groups.
Analytical and Empirical Results
Analytical calculations demonstrate substantial reductions in the variance of the sufficient statistics used in linear regression, all under the same privacy budget:
| Statistic |
Baseline DP-SS Variance |
DP-RSS Refined Variance |
Improvement |
| Sx2,Sxy3, Sx2,Sxy4 |
Sx2,Sxy5 |
Sx2,Sxy6 |
Sx2,Sxy7 |
| Sx2,Sxy8, Sx2,Sxy9 |
Sx,Sy,Sxy,Sx20 |
Sx,Sy,Sxy,Sx21 |
Sx,Sy,Sxy,Sx22 |
| Sx,Sy,Sxy,Sx23 |
Sx,Sy,Sxy,Sx24 |
Sx,Sy,Sxy,Sx25 |
Sx,Sy,Sxy,Sx26 |
The greatest impact is for the error in the linear model coefficients, which are highly sensitive to the variance in quadratic statistics.
Experimental Evaluation
Empirical evaluation was conducted on synthetic regression data (Sx,Sy,Sxy,Sx27) under two regimes. DP-RSS is compared to the DP-SS and DP-Theil-Sen baselines across a range of privacy budgets (Sx,Sy,Sxy,Sx28).
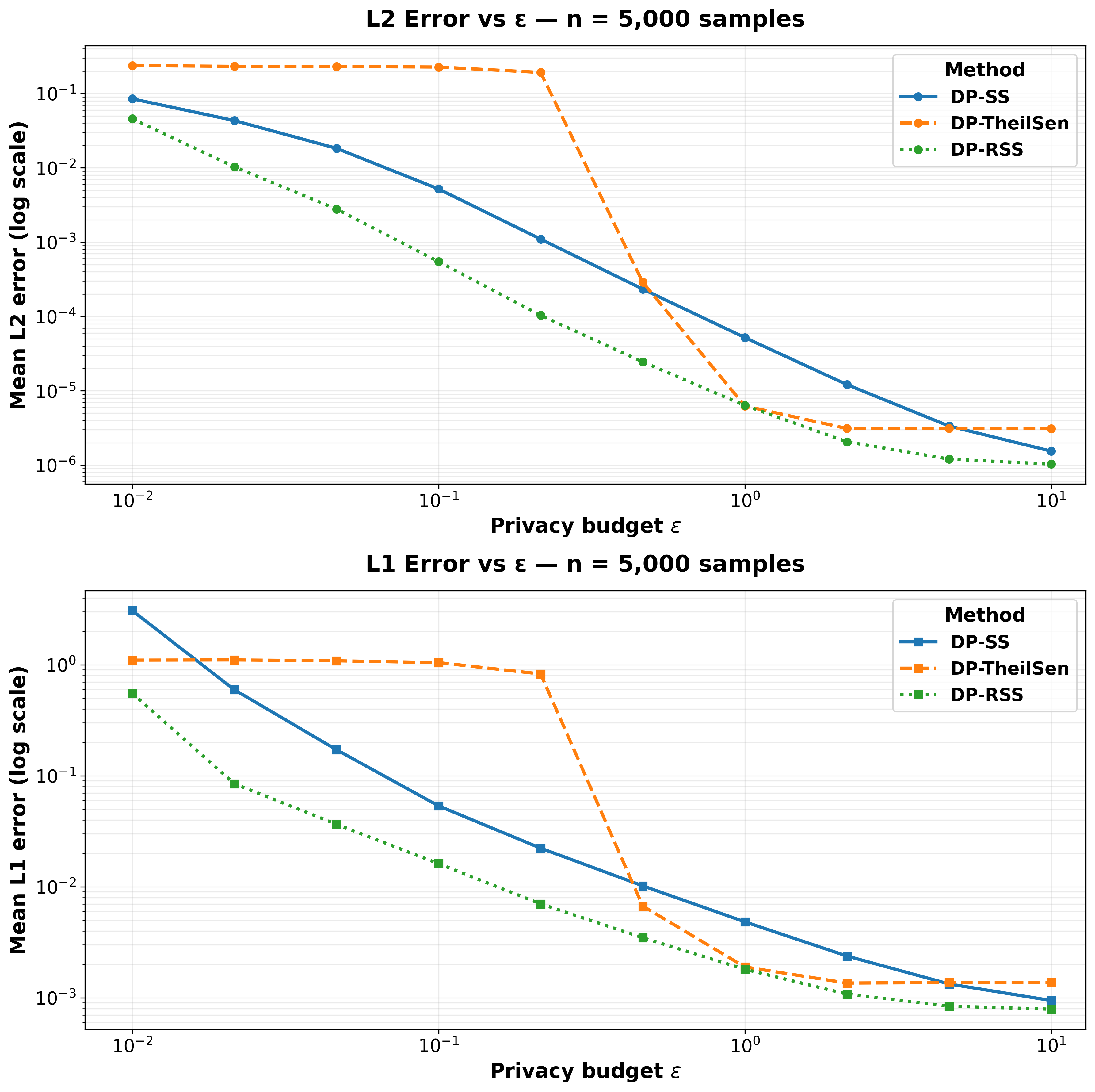
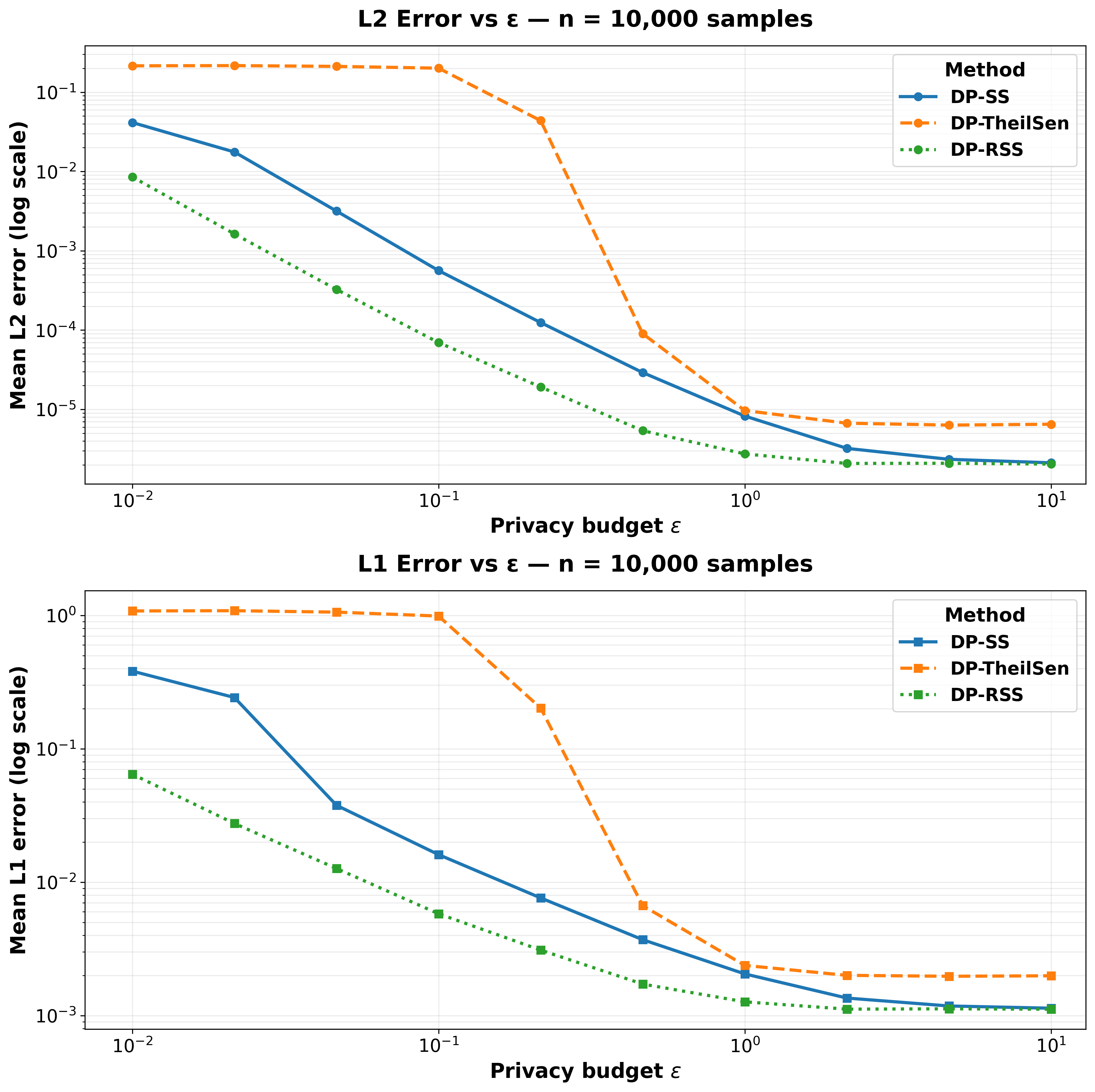
Figure 1: Sx,Sy,Sxy,Sx29 and n0 errors versus n1 for DP-RSS, DP-SS, and DP-Theil-Sen across two synthetic datasets of different sizes.
Both n2 and n3 errors are lower for DP-RSS across all privacy budgets, with especially pronounced gains at low n4. In particular, the reduction in n5 error for DP-RSS over DP-Theil-Sen under high privacy constraints is substantial. The empirical results track closely to the analytical variance reductions reported.
Extension to Polynomial Regression
The multidimensional simplex method generalizes naturally to polynomial regression. For degree-n6 polynomials, transformations of appropriate monomials and their complements enable constructing groups of statistics over the simplex, preserving unit sensitivity and supporting the same optimal variance reduction via independent estimators. The problem of optimally partitioning privacy budget among the corresponding n7 statistics remains open.
Theoretical and Practical Implications
The central implication is that careful exploitation of algebraic redundancy, informed by simplex transformations, offers variance reductions that significantly enhance the accuracy of private regression algorithms in the strongly private add/remove DP setting. This methodology preserves the privacy regime's full rigor: all improvements come from post-processing, sidestepping the cost-privacy utility trade-off that constrains most prior work.
Practically, the result enables accurate linear (and polynomial) regression on moderately-sized, highly sensitive datasets where naive DP methods would incur excessive error. The approach is directly compatible with existing adaptive frameworks (e.g., [wang2018PrivateLinearRegression], [lin2026LinearRegression]) and can be immediately applied to improve both core and data-dependent private estimation algorithms. Theoretically, this work illustrates how algebraic constraints and noise allocation structure can be leveraged under DP to bypass many hardness results based on classical independent-noise mechanisms.
Future research might seek optimal privacy budgeting for higher-degree polynomial statistics or extend the algebraic technique to more sophisticated statistical models (e.g., multivariate regression, GLMs) and aggregation protocols.
Conclusion
This work provides a principled and practical mechanism for highly accurate differentially private linear regression in the add/remove model by extending and generalizing simplex-based "free lunch" results. The DP-RSS method achieves strong variance reduction for sufficient statistics, leading to substantial improvement in regression accuracy, all under unaltered privacy guarantees. The framework is readily extensible to polynomial regression and potentially to broader families of statistical estimators under DP.

