Who Handles Orientation? Investigating Invariance in Feature Matching
Abstract: Finding matching keypoints between images is a core problem in 3D computer vision. However, modern matchers struggle with large in-plane rotations. A straightforward mitigation is to learn rotation invariance via data augmentation. However, it remains unclear at which stage rotation invariance should be incorporated. In this paper, we study this in the context of a modern sparse matching pipeline. We perform extensive experiments by training on a large collection of 3D vision datasets and evaluating on popular image matching benchmarks. Surprisingly, we find that incorporating rotation invariance already in the descriptor yields similar performance to handling it in the matcher. However, rotation invariance is achieved earlier in the matcher when it is learned in the descriptor, allowing for a faster rotation-invariant matcher. Further, we find that enforcing rotation invariance does not hurt upright performance when trained at scale. Finally, we study the emergence of rotation invariance through scale and find that increasing the training data size substantially improves generalization to rotated images. We release two matchers robust to in-plane rotations that achieve state-of-the-art performance on e.g. multi-modal (WxBS), extreme (HardMatch), and satellite image matching (SatAst). Code is available at https://github.com/davnords/loma.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a simple question: when you need to match the same points between two photos that might be turned sideways or upside down, which part of the system should learn to ignore the photo’s orientation? The authors test whether “rotation smarts” should live in the features that describe each point (the descriptor), in the final step that decides which points match (the matcher), or in both. Their goal is to make matching work well even when images are rotated, without slowing things down or hurting normal (upright) performance.
Key Questions the Paper Tries to Answer
- Where should rotation handling be learned: in the descriptor, in the matcher, or both?
- Does learning to handle rotations hurt performance when images are already upright?
- Can a model become good at rotations just by training on lots of varied data, even without special rotation tricks?
How They Studied It (Methods in Simple Terms)
Think of matching two photos like finding the same landmarks on two different maps.
- Step 1: Find interesting spots (keypoints) in each photo.
- Step 2: Describe what each spot looks like in a compact way (a descriptor—like a short ID card for each spot).
- Step 3: Pair up matching spots between the two photos (the matcher—like a professional who compares ID cards and says “these two match”).
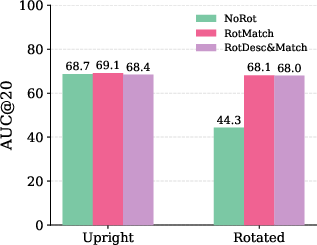
The authors built three versions of this pipeline:
- NoRot: trained without rotated images.
- RotMatch: kept the same descriptors, but trained the matcher with rotated images.
- RotDesc+Match: trained both the descriptors and the matcher with rotated images.
“Training with rotated images” (rotation augmentation) means they took training photo pairs and randomly rotated each image by 0°, 90°, 180°, or 270°. This teaches the system that the same place can look rotated.
They trained on a large mix of real and synthetic 3D vision datasets and evaluated on well-known benchmarks, including:
- MegaDepth and ScanNet (estimate how well you can recover camera movement from matches),
- WxBS (very different sensors and conditions),
- SatAst (matching astronaut photos to satellite images, which can be in any orientation),
- HardMatch (extremely tough, diverse image pairs).
Main Findings (What They Discovered and Why It Matters)
Here are the big takeaways, explained plainly:
- Rotation can be handled early or late—with similar final accuracy:
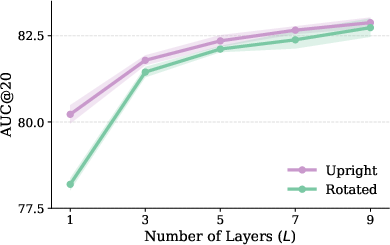
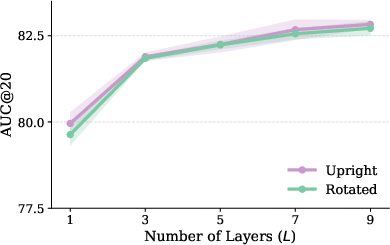
- Teaching the descriptor to be rotation-aware performs about as well as teaching only the matcher.
- But if the descriptor already understands rotations, the matcher becomes confident sooner (in earlier layers), so you can stop it early and run faster while still being robust to rotation.
- Rotation training doesn’t break normal performance if you train at scale:
- On typical upright images, performance was about the same (sometimes a tiny drop, sometimes a tiny gain).
- On harder, out-of-distribution tasks (like WxBS), rotation-trained models often did better—even when images weren’t rotated. In short: more robust, not less.
- More and richer training data naturally builds rotation robustness:
- Even without rotation tricks, training on a big, diverse dataset made the model much better at handling rotated images than training on a single dataset. Diversity in data teaches the model about many ways a scene can appear.
- Real-world wins:
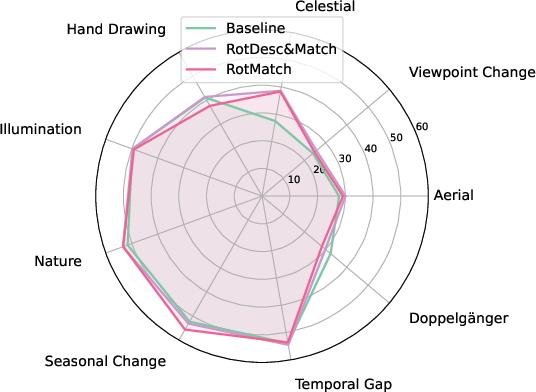
- The rotation-robust models achieved state-of-the-art results on challenging scenarios like multi-modal matching (WxBS), satellite/astronaut image matching (SatAst), and several tough categories in HardMatch (like star constellations, which don’t have a “right side up”).
- Practical speed benefit:
- Because rotation-aware descriptors help the matcher settle on correct matches sooner, you can stop the matcher early and save time—useful for real-time or resource-limited systems.
Why This Matters (Implications and Impact)
Many real-world images don’t have a “top” (think drone photos, satellite views, or pictures taken at odd angles). This work shows:
- You can make matching robust to rotations without sacrificing speed or everyday accuracy.
- It’s often best to teach rotation handling to the descriptors first, which can make the whole system faster.
- Training on large, varied data naturally builds stronger and more general systems—even for challenges you didn’t explicitly train for.
Bottom line: this research helps build more reliable, faster image-matching systems for maps, robots, drones, medical scans, and space imagery—anywhere orientation can be unpredictable. The authors also released code and two rotation-robust matchers, making it easier for others to use these improvements.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list synthesizes what remains missing, uncertain, or unexplored in the paper, phrased to guide concrete follow-up research:
- Detector-stage orientation handling is not studied. Evaluate rotation invariance at the detector (e.g., rotation-aware interest point selection, orientation assignment, or rotation-equivariant detectors) and its interaction with descriptor/matcher invariance.
- Architectural generality is unclear. Validate whether conclusions hold beyond the DeDoDe-G + LightGlue pipeline by reproducing results with other descriptors (e.g., SuperPoint, DISK, R2D2, ALIKED variants) and matchers (e.g., SuperGlue, modern transformer matchers, coordinate-free variants).
- Coordinate inputs to the matcher are assumed necessary but not ablated. Test removing, normalizing, or rotating coordinates into a relative, rotation-normalized frame in the matcher to determine if descriptor-only invariance can suffice without sacrificing performance.
- Equivariant architectures are not benchmarked. Compare learned invariance via augmentation versus hard-coded equivariance (e.g., rotation-equivariant CNN/transformer layers) at descriptor and matcher stages, including computational and accuracy trade-offs.
- Non-trivial steerers are not integrated. Develop and evaluate sparse matchers that can exploit learned steerers (latent rotations) at match time, and quantify whether steerers improve discriminativeness versus fully invariant descriptors.
- Training augmentation only uses discrete right-angle rotations. Assess continuous-angle augmentation, its sampling distributions, and anti-aliasing/resampling strategies during training; quantify if this reduces performance dips at non-multiple-of-90° angles.
- Limited analysis of emergent invariance from data. Identify which datasets or factors (e.g., aerial vs. ground scenes) contribute most to emergent rotation robustness via controlled leave-one-dataset-out or reweighting studies.
- Earlier stopping benefits are not quantified in system terms. Report wall-clock latency, throughput, energy, and memory savings for early stopping under realistic settings (batch sizes, devices) and across different N keypoints.
- Lack of adaptive halting criteria. Explore learnable or confidence-based early-stopping policies that dynamically decide when sufficient rotation invariance is attained during matching.
- Trade-off between invariance and distinctiveness remains underexplored. Measure how enforced invariance affects false matches, precision-recall, and match uniqueness in rotationally symmetric or repetitive structures.
- Failure mode characterization is limited. Provide a systematic analysis of scenarios where invariance degrades upright performance (e.g., textureless regions, highly anisotropic features), with targeted ablations.
- Robustness beyond in-plane rotations is not addressed. Evaluate sensitivity to out-of-plane rotations (viewpoint changes), anisotropic scaling, general affine transforms, and lens distortions; study combined invariance regimes.
- Interaction with other nuisance factors is not studied. Quantify how rotation invariance co-trains with robustness to illumination changes, blur, noise, and modality gaps, especially in cross-sensor settings (e.g., SAR, thermal).
- End-to-end joint training is absent. Investigate training detector+descriptor+matcher jointly under rotation augmentation/equivariance to assess whether synergy yields larger gains than stage-wise training.
- Keypoint budget sensitivity is unreported. Analyze performance and invariance across different numbers of keypoints (e.g., N ∈ [256, 8192]), including effects on early stopping and matching reliability.
- RANSAC stochasticity is acknowledged but not mitigated. Report confidence intervals across all benchmarks, and evaluate robust/degenerate-free pose estimators or deterministic alternatives to reduce metric variance.
- Rotation augmentation schedule and probability are not ablated. Vary augmentation strength, probability, independent vs. joint rotations, and curriculum over training to find configurations minimizing upright performance loss.
- Boundary and resampling artifacts are underexamined. Study the impact of rotation interpolation (e.g., bilinear vs. bicubic), padding/cropping strategies, and training-time circular cropping on downstream metrics.
- Evaluation breadth remains limited. Extend testing to more domains where orientation is unconstrained (e.g., medical scans, microscopy, robotics with random roll), and provide per-category/per-scene breakdowns beyond the celestial group.
- Dataset dependence and licensing constraints may affect reproducibility. Clarify data availability and provide smaller public subsets or synthetic surrogates to replicate scaling claims.
- Intrinsics handling under rotations is idealized. Stress-test robustness to intrinsics estimation errors after image rotations and to real-world EXIF/orientation metadata inconsistencies.
- Theoretical understanding of invariance emergence is lacking. Analyze representation geometry (e.g., canonical correlation, mutual information across rotations) layer-by-layer to explain why descriptor-trained invariance appears earlier in the matcher.
- Coordinate-induced biases are not quantified. Examine whether spatial biases (e.g., absolute image coordinates vs. relative geometry) hinder rotation invariance, and test learned normalizations or coordinate-free attention.
- Continuous-angle evaluation is only partial. Expand continuous-angle tests with randomized pairs and scenes, and report comprehensive statistics (AUC@k, precision-recall, inlier ratios) across the full angle range.
- Practical deployment constraints are unaddressed. Profile models on-edge (mobile/embedded) with and without early stopping, and study how invariance interacts with quantization and low-bit inference.
Practical Applications
Overview
This paper studies where to incorporate rotation invariance in a modern sparse image matching pipeline (descriptor vs. matcher). Key findings with practical bearing are:
- Incorporating rotation invariance in the descriptor yields similar final accuracy to handling it only in the matcher, but the matcher becomes rotation-invariant earlier across its layers—enabling earlier stopping and lower latency.
- Enforcing rotation invariance does not harm (and can improve) performance on upright, out-of-distribution tasks when trained at scale.
- Training on a diverse data mix substantially improves generalization to rotated images even without explicit rotation augmentation.
- The authors release two rotation-robust sparse matchers achieving state-of-the-art on multi-modal (WxBS), extreme (HardMatch), and satellite–astronaut (SatAst) benchmarks.
Below are actionable, real-world applications mapped to sectors, with feasibility notes.
Immediate Applications
These can be deployed with today’s tools; the authors provide code and trained models.
- Rotation-robust matching in SfM/visual localization pipelines
- Sectors: software, robotics, AR/VR, mapping
- What to do: Replace existing sparse matchers (e.g., SuperGlue/LightGlue baselines) with the released rotation-robust models in SfM, relocalization, and mapping pipelines to improve reliability under arbitrary in-plane camera orientations.
- Tools/workflows: Integrate the released LoMa-based rotation-robust matcher as a drop-in component in 3D reconstruction and localization stacks (e.g., photogrammetry pipelines, visual SLAM frameworks).
- Dependencies/assumptions: Access to keypoints and descriptors (e.g., DaD + DeDoDe-G or equivalent); pipelines that pass image coordinates to the matcher should train the matcher for invariance (descriptor-only invariance is insufficient if coordinates are used).
- Faster matching via early stopping in the matcher
- Sectors: mobile/edge computing, robotics, AR/VR
- What to do: Use the insight that rotation invariance emerges earlier when learned at the descriptor stage to stop the matcher after fewer layers, reducing latency/energy without sacrificing rotation robustness.
- Tools/workflows: Add early-exit criteria (fixed or adaptive layer count) tied to confidence/mutual assignment thresholds in LightGlue-like architectures.
- Dependencies/assumptions: Calibrate the earliest safe stopping layer per task/device; monitor match quality (e.g., confidence or RANSAC success rate) to avoid quality regressions.
- Aerial/satellite image registration and mosaicking with arbitrary roll
- Sectors: geospatial, energy, urban planning, disaster response, defense
- What to do: Swap in the rotation-robust matcher for aligning aerial imagery across variable aircraft/satellite roll angles and for astronaut-to-satellite image alignment (as in SatAst).
- Tools/workflows: Orthomosaic stitching, change detection, map alignment; integrate into GIS/photogrammetry pipelines.
- Dependencies/assumptions: Robustness demonstrated for 90° increments and generalization to arbitrary angles; quality depends on scene overlap and modality gap (may require domain-specific fine-tuning).
- Multi-modal and hard-condition correspondence (sensor, illumination, viewpoint)
- Sectors: security, industrial inspection, cultural heritage digitization
- What to do: Use rotation-robust models to stabilize matching across different sensors or lighting/time-of-day shifts (e.g., IR–RGB, day–night), with additional resilience to arbitrary orientations.
- Tools/workflows: Cross-sensor registration, stitching, object/scene correspondence under operational rotations.
- Dependencies/assumptions: Gains shown on WxBS; effectiveness rises with data diversity and may require fine-tuning for specific sensors.
- Drone and handheld mapping under camera roll
- Sectors: robotics, UAV operations, surveying
- What to do: Improve robustness of mapping/localization when the platform experiences significant roll/pitch, especially for small UAVs or handheld capture where canonical orientation is absent.
- Tools/workflows: Onboard or near-real-time matching; apply early-exit to meet compute budgets.
- Dependencies/assumptions: Adequate overlap and keypoint density; latency constraints dictate early-exit tuning.
- Medical and scientific image mosaicking (in-plane rotations)
- Sectors: healthcare, life sciences
- What to do: Improve 2D mosaicking/registration of rotated slides and images (e.g., histology tiles, microscopy fields) without pre-rotating or orientation normalization.
- Tools/workflows: Tile stitching, QA for scan orientation variability.
- Dependencies/assumptions: Primarily in-plane rotations; for strong cross-modality (e.g., MRI–CT), domain-specific training may be necessary.
- Astronomy and celestial mapping
- Sectors: aerospace, research
- What to do: Enhance matching of star fields/planetary imagery with arbitrary orientation, benefiting star trackers and celestial navigation aids.
- Tools/workflows: Star map alignment, constellation recognition, deep-sky mosaicking.
- Dependencies/assumptions: Scene symmetry can reduce distinctiveness; nonetheless, paper reports gains on “celestial” cases in HardMatch.
- Dataset and training practice: prioritize diversity to induce invariance
- Sectors: academia, ML engineering
- What to do: Curate training sets with varied domains and natural rotations to gain rotation robustness even without augmentation; then add rotation augmentation to descriptors and matchers for further gains.
- Tools/workflows: Data pipelines that mix aerial, indoor/outdoor, synthetic/real scenes; scripted rotation augmentation for descriptor and matcher stages.
- Dependencies/assumptions: Access to large-scale, diverse datasets; training compute budget.
- QA and benchmarking with rotated evaluations
- Sectors: academia, industry QA
- What to do: Adopt rotated variants of standard benchmarks (e.g., MegaDepth-1500 rotated) and multi-modal sets (WxBS) for model verification and regression testing.
- Tools/workflows: CI tests that include rotated pairs; track AUC/mAA under rotations.
- Dependencies/assumptions: Standardized evaluation code; acceptance criteria for rotated performance.
- Consumer photo stitching and near-duplicate detection
- Sectors: consumer software, photo management
- What to do: Improve panorama stitching and duplicate detection across rotated images (e.g., photos taken upside down).
- Tools/workflows: Integrate rotation-robust matching in camera apps and libraries.
- Dependencies/assumptions: On-device efficiency relies on early-exit and efficient keypoint/descriptor extraction.
Long-Term Applications
These require further research, engineering, or scaling to be production-ready.
- Fully rotation-equivariant sparse matching pipeline
- Sectors: software, robotics, aerospace, mobile
- What: Develop detector/descriptor/matcher architectures with guaranteed rotation equivariance/invariance (not just learned) to eliminate residual rotation sensitivity and reduce training burden.
- Dependencies/assumptions: Architectural advances (e.g., group-equivariant networks), proof of compute/latency benefits; integration with real-world I/O and coordinate handling.
- Latent steerer–aware sparse matching
- Sectors: software, research
- What: Integrate non-trivial “steerer” transformations into descriptors and adapt the matcher to exploit them for distinctiveness across rotations, potentially exceeding invariance-only approaches.
- Dependencies/assumptions: New matcher designs to leverage steerers; joint training protocols.
- Energy-aware, adaptive early-exit matchers for edge devices
- Sectors: mobile/AR, robotics, UAVs
- What: Dynamically adjust the number of matcher layers per frame based on confidence or motion estimates to save energy while meeting accuracy targets.
- Dependencies/assumptions: Reliable confidence metrics; scheduling policies; hardware/OS support for dynamic compute budgeting.
- Standards and procurement guidelines for rotation-robust vision
- Sectors: policy, public sector, defense
- What: Codify rotation-robust matching performance in RFPs and standards for mapping, disaster response, and autonomous systems.
- Dependencies/assumptions: Community consensus on benchmarks and metrics; reproducible evaluation suites.
- Beyond rotation: robustness to broader symmetries (scale, affine, viewpoint)
- Sectors: photogrammetry, autonomous systems
- What: Extend the “learn invariance early” insight to scale/affine invariance and study early-exit savings under more complex transformations.
- Dependencies/assumptions: Data and augmentation coverage; potential use of affine steerers/equivariant layers.
- Cross-modality extremes (e.g., SAR–optical, thermal–RGB)
- Sectors: geospatial, defense, infrastructure monitoring
- What: Combine rotation-robust sparse matching with multi-modal feature learning to handle severe appearance gaps across arbitrary orientations.
- Dependencies/assumptions: Modality-specific training data; tailored descriptors; rigorous field validation.
- Spacecraft guidance and terrain-relative navigation
- Sectors: aerospace
- What: Use rotation-robust matching for star trackers and planetary/asteroid surface matching under arbitrary roll/yaw and illumination extremes.
- Dependencies/assumptions: Radiation-hardened implementations; certification; integration with onboard navigation stacks.
- Regulatory-grade medical image registration
- Sectors: healthcare
- What: Build rotation-robust registration modules for clinical workflows (e.g., digital pathology, endoscopy mosaics) with validated accuracy across orientations.
- Dependencies/assumptions: Clinical validation, data governance, regulatory approval.
- Open-source ecosystem integration (OpenCV/ROS/SLAM stacks)
- Sectors: software, robotics
- What: Mature libraries and ROS packages for rotation-robust sparse matching with configurable early exit and evaluation tools.
- Dependencies/assumptions: Community maintenance; cross-platform optimization; clear licensing.
- Curriculum/data-centric training recipes
- Sectors: academia, ML Ops
- What: Formalize training curricula showing how dataset diversity plus targeted augmentation yields robustness, transferable to other symmetry groups and tasks.
- Dependencies/assumptions: Access to large, diverse datasets; reproducible training infrastructure.
Notes common to many applications:
- Assumes availability of the released code/models and compatibility with existing keypoint/descriptor pipelines.
- While performance on rotations is markedly improved, invariance is not mathematically guaranteed; for safety-critical deployments, consider equivariant architectures and extensive validation.
- The benefits of “invariance-in-the-descriptor” for early-exit speedups depend on careful layer/threshold tuning per deployment.
Glossary
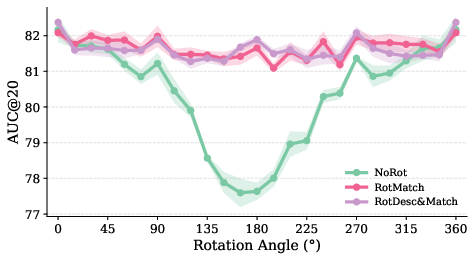
- AUC@20: Area Under the Curve at a 20-degree threshold; a summary metric for pose/matching accuracy across error tolerances up to 20°. "Notably, AUC@20 improves by 52 points on the rotated evaluation set of MegaDepth-1500."
- camera intrinsics: Parameters defining the internal calibration of a camera (e.g., focal length, principal point) used to relate image pixels to rays. "The camera intrinsics are updated to remain consistent with the rotated image coordinates."
- confidence interval: A statistical range indicating the uncertainty around an estimated performance metric. "We average over 5 runs and include a 95\% confidence interval."
- data augmentation: Training-time transformations of inputs to improve robustness and generalization. "A straightforward mitigation is to learn rotation invariance via data augmentation."
- dense matchers: Methods that establish correspondences across many or all pixels rather than at sparse keypoints. "The resulting model, LoMa, achieves state-of-the-art (SotA) performance, even surpassing dense matchers on some benchmarks."
- descriptor: A vector representation capturing local image appearance around a keypoint for matching. "We train descriptors and matchers with and without rotation augmentation, resulting in the three different models used for our main experiments."
- detector: An algorithm or network that identifies salient keypoint locations in images. "We do not train the detector ."
- detector-free matching: Matching without explicit keypoint detection, typically using dense or semi-dense features. "Broadly, there are two paradigms: (i) sparse and (ii) dense, detector-free matching."
- double-softmax: Applying softmax along both rows and columns of a similarity matrix to obtain mutual match probabilities. "Soft assignments are produced by taking the double-softmax of ."
- equivariant neural networks: Networks designed so that transformations of the input (e.g., rotations) correspond predictably to transformations of the output. "One way to obtain rotation invariance is by using equivariant neural networks~\cite{cohen2016group,weiler2023EquivariantAndCoordinateIndependentCNNs}."
- graph neural network: A neural architecture operating on graph-structured data; here used to reason over relationships between keypoints for matching. "Sparse matchers, such as SuperGlue~\cite{sarlin2020superglue} and LightGlue~\cite{lindenberger2023lightglue}, replace nearest neighbor search with a graph neural network in order to match descriptors."
- homographies: Planar projective transformations mapping points between images under certain geometric conditions. "We report the AUC@10px for estimated homographies in \cref{tab:challenging-matching}."
- in-plane rotations: Rotations of the image around the viewing axis (within the image plane). "We release two matchers robust to in-plane rotations that achieve state-of-the-art performance..."
- keypoints: Distinctive image locations (e.g., corners) used as anchors for establishing correspondences. "This is typically achieved in a three-step manner: (i) detection of sparse keypoints..."
- mAA@10px: Mean accuracy at a 10-pixel threshold; the fraction of predicted correspondences within 10 pixels of ground truth, averaged over cases. "WxBS~\cite{mishkin2015WXBS} ... We report the mean accuracy (mAA@10px) in \cref{tab:challenging-matching}."
- matcher: The stage or model that establishes correspondences between descriptors from two images. "The matcher is trained with rotation augmentation while using the same descriptor as NoRot."
- mutual nearest neighbor: A matching criterion where two descriptors are paired only if each is the nearest neighbor of the other. "Learning-based approaches have been proposed for each stage of this pipeline. Sparse matchers ... replace nearest neighbor search with a graph neural network in order to match descriptors. Recently, ..."
- out-of-distribution (OOD): Data that differs from the distribution seen during training; used to assess generalization. "However, generalization to out-of-distribution upright matching tasks marginally improves..."
- RANSAC: A robust estimation algorithm that fits models (e.g., epipolar geometry) while rejecting outliers. "Empirically, we find that AUC@20 fluctuates by around due to the stochasticity of RANSAC."
- relative pose estimation: Estimating the rotation and translation between two camera views from image correspondences. "We evaluate relative pose estimation on MegaDepth-1500~\cite{li2018megadepth,sun2021loftr} and ScanNet-1500..."
- rotation augmentation: Training-time application of random image rotations to encourage rotational robustness. "To investigate the effect of rotation invariance, we include random rotation augmentations in some experiments."
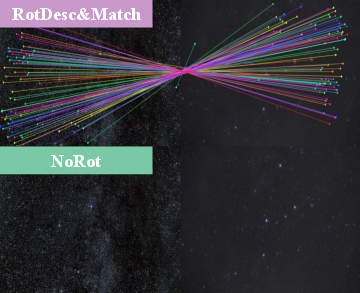
- rotation invariance: The property that performance is unaffected by rotations of the input images. "Rotation invariance in image matching is a popular research topic..."
- similarity matrix: A matrix containing pairwise similarity scores between descriptors from two images. "The resulting descriptors ... are used to compute the similarity matrix ."
- soft assignments: Probabilistic match scores between features, often derived via softmax normalization. "Soft assignments are produced by taking the double-softmax of ."
- sparse matchers: Methods that match a limited set of detected keypoints rather than dense pixels. "Sparse matchers, such as SuperGlue~\cite{sarlin2020superglue} and LightGlue~\cite{lindenberger2023lightglue}..."
- state-of-the-art (SotA): The best reported performance in a field at a given time. "The resulting model, LoMa, achieves state-of-the-art (SotA) performance, even surpassing dense matchers on some benchmarks."
- steerer: A learned latent transformation used to align feature representations across transformed inputs (e.g., rotations). "Recently, Steerers~\cite{bökman2024steerers,bokman2024affine} proposed to use a latent transformation (steerer) for aligning descriptions of corresponding keypoints in rotated images."
- Structure-from-Motion (SfM): The process of reconstructing 3D structure and camera motion from multiple images. "A crucial part of both visual localization and Structure-from-Motion (SfM)~\cite{hartley2003multiple} is finding correspondences..."
- SVD (Singular Value Decomposition): A matrix factorization used here to visualize descriptor features by projecting onto principal components. "To allow for meaningful color semantics, we estimate the projection to the top three principal components using SVD in the upright image..."
Collections
Sign up for free to add this paper to one or more collections.