- The paper's main contribution is a unified taxonomy that categorizes methods for integrating object-centric vision with LMMs and highlights precise localization and controllable editing.
- It details architectural paradigms and interfaces, including text prompts, visual tokens, and feature fusion, to enhance object segmentation and semantic grounding.
- The research explores advanced generative models for controlled editing and synthesis across 2D, video, and 3D data while outlining future directions for embodied AI.
Object-Centric Vision in Large Multimodal Models: Analysis and Perspectives
Introduction and Problem Landscape
Large Multimodal Models (LMMs) have demonstrated impressive advancements in general-purpose multimodal alignment and instruction following. However, their architectures trace inherent limitations in tasks requiring object-level precision, semantic grounding, and controllable manipulation due to a coarse global perception and the challenge of aligning high-level linguistic reasoning to localized visual regions. The reviewed paper systematically categorizes and analyzes breakthroughs at the intersection of LMMs and object-centric vision, emphasizing four core capabilities: object understanding, segmentation, editing, and generation.
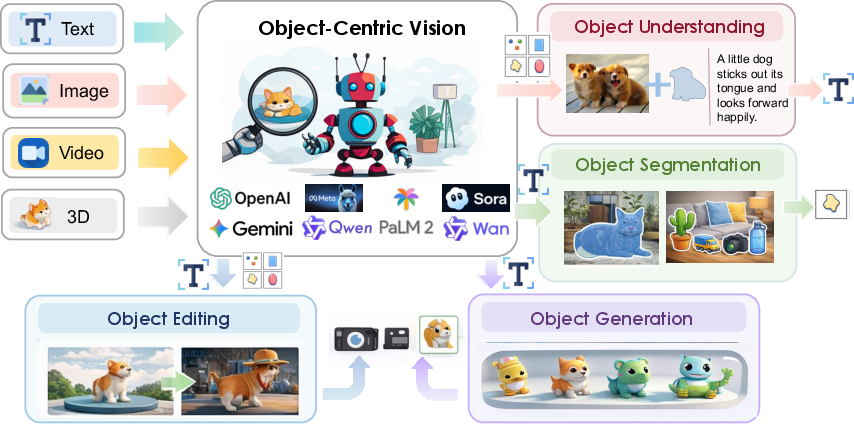
Figure 1: Object-centric vision in the LMM era; explicit object representations underpin understanding, segmentation, editing, and generation for both 2D and 3D data.
The authors provide a unified taxonomy, detail architectural paradigms, examine backbone and learning choices, and systematically expose gaps for future investigation.
Object-Centric Visual Understanding
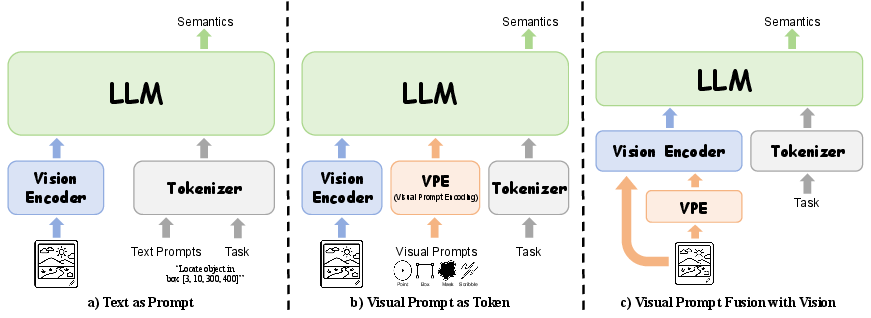
Object-centric understanding extends beyond classic image captioning or visual QA to precise identification, reasoning, and contextualization of entities and regions. The paper offers a granular decomposition of paradigms for injecting objectness into MLLMs:
In addition to modality fusion, region encoders are classified by their support for coordinate, mask-based, and mixed-format prompts, with notable progress in arbitrary visual marker comprehension. Significant progress is reported in both image and video referring, with unified interfaces now supporting shared representations for spatially/temporally grounded queries. The paper extends this to 3D, detailing the evolution from instance proposal models to architectures incorporating multi-view, geometry-aware, and compositional reasoning.
Object-Centric Referring Segmentation
LMM-driven referring segmentation reframes dense prediction as a hybrid reasoning and localization task, with the central architectural problem being the design of the language–pixel interface. The main interface patterns include:
- Single Embedding Prediction: LLM emits a single mask-guided embedding for segmentation.
- Multi-Embedding Prediction: Multiple embeddings capture local or multi-instance segmentation.
- Next-Token Prediction: Mask or proxy structures are generated directly in sequence space.
- Attention-Based Prediction: Segmentation mask is induced from grounded cross-modal attention distributions.
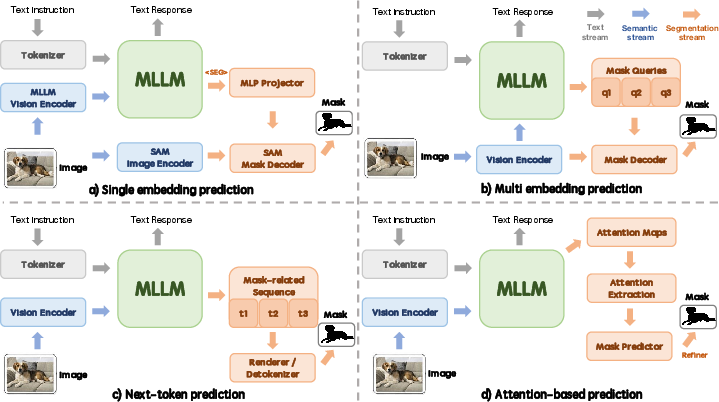
Figure 3: Representative segmentation interfaces: embedding, multi-embedding, token prediction, and latent attention extraction.
The detailed discussion traces interface evolution (from prompt-driven to autoregressive models), vision backbone selection (with perception increasingly unified via promptable and segmentation foundation models), and mask decoding mechanisms, highlighting the role of SAM/SAM2 in modular plug-and-play pipelines. The survey notes a shift toward reasoning-intensive, multi-instance, and cross-modal/object segmentation, both in 2D/3D and video/audiovisual contexts. Recent datasets reveal increasing scale and diversity, mirroring this architectural expansion.
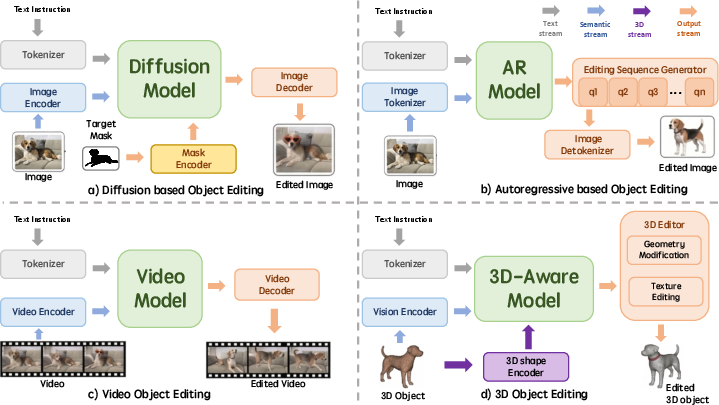
Object-Centric Visual Editing
Generative architectures, primarily diffusion and autoregressive models, drive the contemporary landscape of object-centric editing:
Benchmarks cover not only image-level instruction adherence and spatial consistency but also real-time, interactive, and multi-modal evaluation requirements.
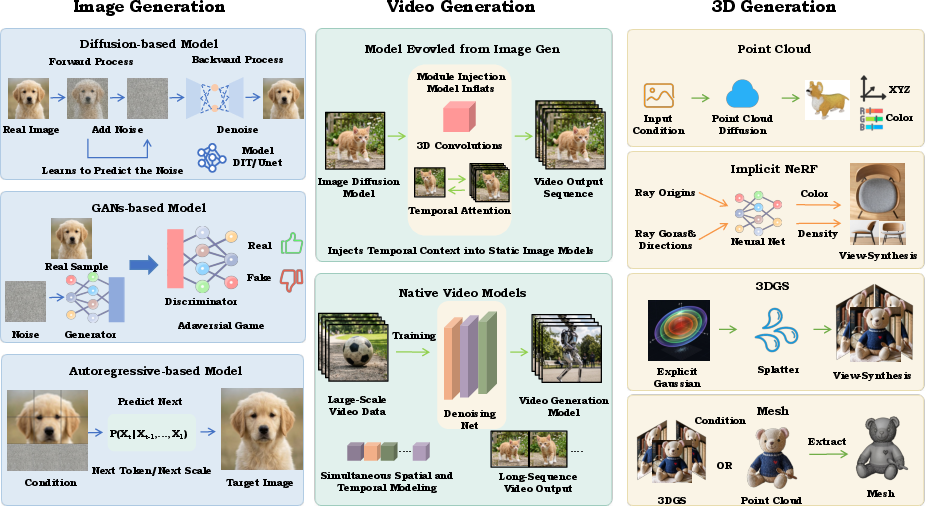
Object-Centric Visual Generation
The generative pipeline now spans images, video, and 3D, progressively moving from holistic synthesis toward explicit control and compositional object generation. Key architectural highlights include:
Dataset scale is highlighted as a key driver, with high-quality, large-scale corpora for each modality (e.g., LAION, Objaverse-XL) enabling scalable object-centric multimodal models.
Cross-Cutting Themes and Future Directions
The synthesis provided identifies several theoretical and practical implications:
- Unified Multimodal Architecture: Trends point toward sequence-to-sequence models operating over unified, tokenized representations, largely minimizing hand-crafted, task-specific heads.
- Long-term Consistency: The next bottleneck is robust instance permanence in temporally dynamic settings, motivating integration of explicit spatial-temporal reasoning (e.g., chain-of-thought tracking, physical priors, anchor-based attention).
- Fine-Grained Controllability: Decoupling attributes (shape, appearance, kinematics) and improving disentangled tokenization are critical for compositional editing and synthesis.
- Data and Benchmarking: Weakly supervised and synthetic data pipelines will be increasingly utilized, with a premium placed on robust optimization (e.g., sim-to-real adaptation, annotation noise mitigation).
- Toward Embodied AI: The natural end state is active, real-time, object-aware agents—demanding egocentric adaptation, affordance grounding, RL-based policy learning, and algorithm–hardware codesign.
Conclusion
This survey establishes a formal framework unifying object-centric vision and LMMs, synthesizing a comprehensive lens on architectures, data, and evaluation across understanding, segmentation, editing, and generation. It clearly articulates advances in object-aware multimodal interaction while systematically exposing the challenges of grounding, fine-grained control, and robust evaluation. The convergence toward unified, precise object-centric modeling in vision–language foundation models is shaping practical and theoretical pathways for the next generation of embodied, interactive AI systems.
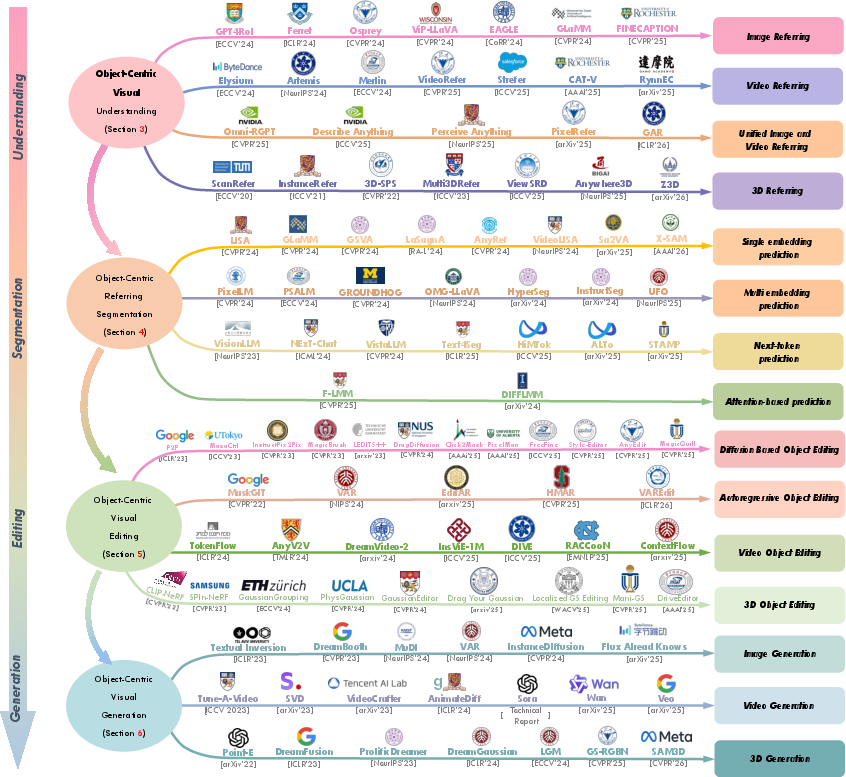
Figure 6: Schematic overview of technical approaches for object-centric understanding, segmentation, editing, and generation, including model categorization and capability mapping.