- The paper introduces LARYBench, a unified benchmark and large-scale dataset for latent action representations, covering over 1,000 hours of video across 151 action categories.
- It demonstrates that general visual encoders, like V-JEPA-2 and DINOv3, outperform specialized latent action models in both semantic classification and physical control tasks.
- The study advocates leveraging rich pre-trained visual models to enhance robust vision-to-action alignment and guide future research in open-world robotic control.
LARY: A Unified Benchmark for Latent Action Representation in Vision-to-Action Alignment
Introduction and Motivation
The paper "LARY: A Latent Action Representation Yielding Benchmark for Generalizable Vision-to-Action Alignment" (2604.11689) presents LARYBench, a comprehensive evaluation suite and large-scale dataset targeting latent action representations derived from visual data. This initiative addresses a critical deficiency in the field: the lack of rigorous, standardized benchmarks for latent action models (LAMs) that support cross-domain generalization and robust embodied control. The authors emphasize the inadequacy of prior evaluations, which largely focus on downstream task performance or qualitative metrics, and highlight the need to decouple representation assessment from policy evaluation.
LARYBench Dataset and Pipeline
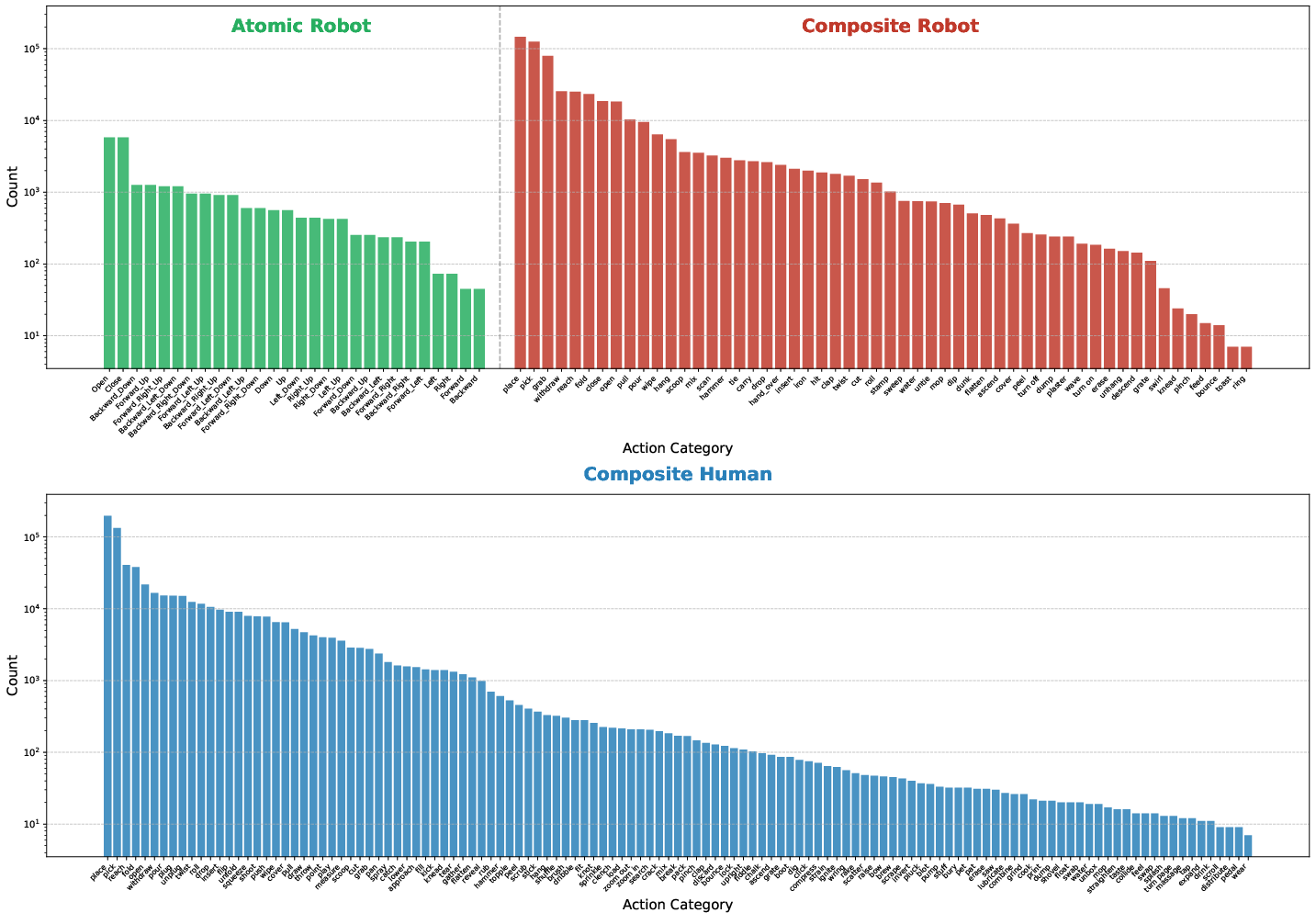
LARYBench comprises over one million curated videos (1,000+ hours), 620K image pairs, and 595K motion trajectories, spanning 151 action categories (atomic and composite) and diverse embodiments and viewpoints (11 robotic morphologies, human egocentric and exocentric domains, and both simulated and real-world settings). The pipeline addresses three main components: (a) comprehensive multimodal data construction, (b) robust extraction of continuous latent actions using alternative representation paradigms, and (c) quantitative probe-based evaluation for both semantic (classification) and embodied (regression) axes.
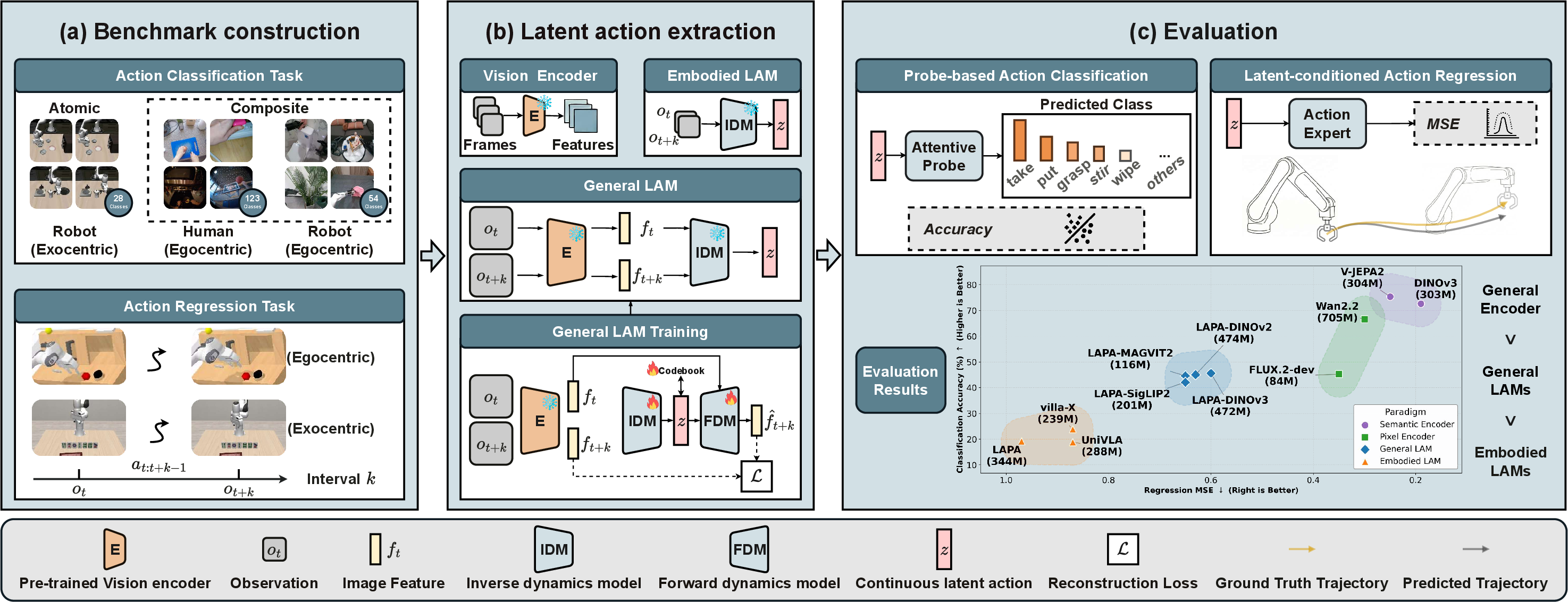
Figure 1: The LARY benchmark pipeline integrating data spanning atomic/composite actions, latent representation extraction (including pre-trained vision encoders), and evaluation with classification and regression probes.
Raw video curation is automated via a spatio-temporal vision-LLM serving as a segmentation and annotation agent. This system standardizes temporal boundaries and semantic alignment, harmonizing heterogeneous sources (e.g., Something-Something-v2, Ego4D, AgiBotWorld-Beta) into a highly controlled, consistent dataset for large-scale probe-based analysis.
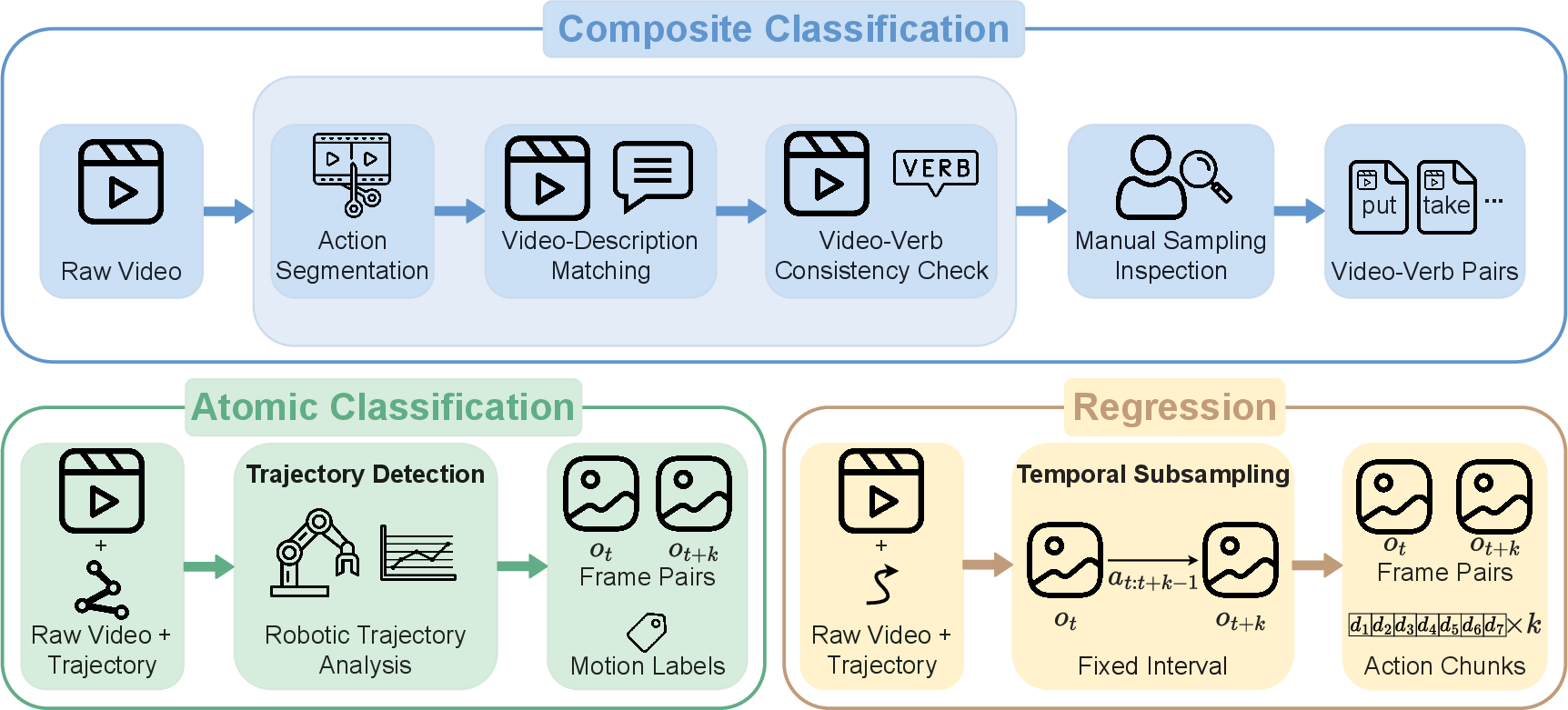
Figure 2: Data curation leverages a VLM for temporal segmentation and precise semantic action alignment across massive raw video corpora.
Evaluation Protocols
LARYBench formalizes two principal axes for evaluating latent action representations:
1. Semantic Granularity: Kinematic and Behavioral

Figure 4: Word clouds illustrating the semantic and object diversity present in LARYBench’s annotations, reflecting wide coverage for both interaction types and manipulated entities.
2. Physical Execution: Regression for Control
Evaluating whether latent action embeddings preserve actionable, physically meaningful details for reconstructing end-effector movements, with regression targets tailored by morphology (e.g., 16-DoF for AgiBotWorld, 12-DoF for RoboCOIN, 7-DoF for others). The physical regression track is designed to challenge models’ capacity to support low-level control across significant morphological and environment diversity.
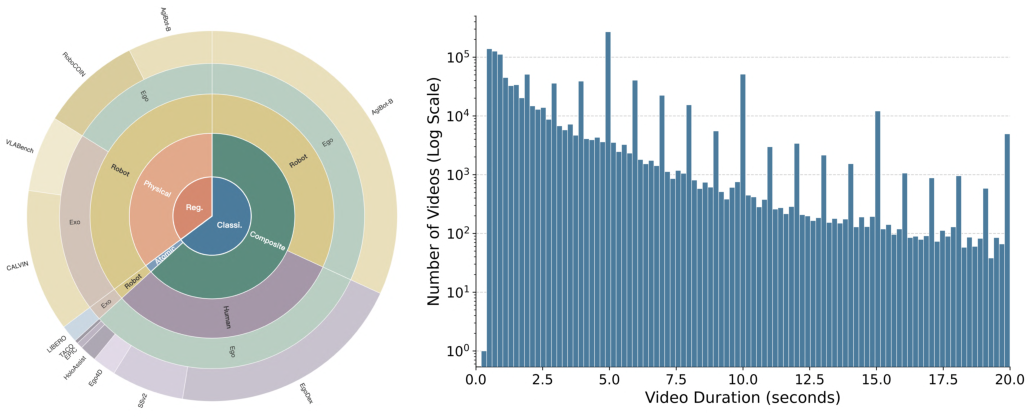
Figure 5: Proportional composition of LARYBench by data type, agent, and embodied task.
Model Paradigms and Probing Methodology
Three core model classes are systematically evaluated:
- Embodied LAMs: Architectures explicitly shaped by robot manipulation and forward/inverse dynamics constraints (e.g., LAPA, UniVLA, villa-X).
- General Vision Encoders: Foundation models trained with semantic- or pixel-level pretext objectives (e.g., DINOv3, V-JEPA-2, Wan2.2, FLUX.2-dev) but without explicit action supervision.
- General LAMs: Hybrid models that learn latent actions atop frozen, pre-trained visual backbones via VQ-VAE, trained with a scalable mix of human, robot, and environmental dynamics.
All models are evaluated via attentive probe classifiers for semantic tasks and simple MLP action experts for low-level control regression, with rigorous protocol for data splits, temporal sampling (MGSampler), and consistent latent feature alignment.
Empirical Results
1. Action Semantics: Classification
General vision encoders (especially V-JEPA-2 and DINOv3) achieve the highest accuracy across semantic tracks, outperforming both specialized embodied LAMs and General LAMs despite the absence of explicit action supervision. V-JEPA-2 surpasses DINOv3 slightly, attributed to latent-level encoding for more robust transfer.
Composite action classification reveals pronounced generalization gaps for traditional embodied LAMs, which plateau at ~18-20% average accuracy, compared to 76.6% for V-JEPA-2. Notably, General LAMs (e.g., LAPA-DINOv2) leverage diverse pre-trained priors to bridge some of this gap, indicating the benefit of visual self-supervision at scale but still underperforming compared to unconstrained vision encoders.
2. Low-Level Control: Regression
For action regression (MSE), latent-based encoders (V-JEPA-2, DINOv3) outperform both pixel-based and embodied-specific architectures, with DINOv3 slightly favored for its contrastive learning origin and enhanced spatial resolution in physical tasks. Embodied LAMs struggle with higher MSE, underscoring their limited capacity for universal control abstraction.
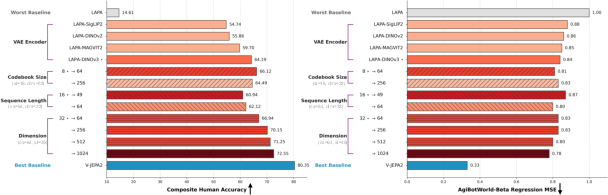
Figure 6: Evolution of latent action model performance in composite human classification and AgiBotWorld-Beta regression.
Ablation studies on codebook size, sequence length, and latent dimensionality reveal trade-offs between quantization utilization, stability, and representational richness, with intermediate codebook size (cs=64), longer sequence lengths (sl=49), and moderate latent dimension (dim=256) supporting best downstream performance.
3. Robustness and Temporal Generalization
Stride ablations demonstrate that while pixel-based encoders can perform well at short temporal horizons, they collapse for longer-range regression. Latent action models (including General LAMs) maintain stability across extended intervals, indicating their ability to encode robust, temporally persistent dynamic plans.
4. Error Analysis and Attention Diagnostics
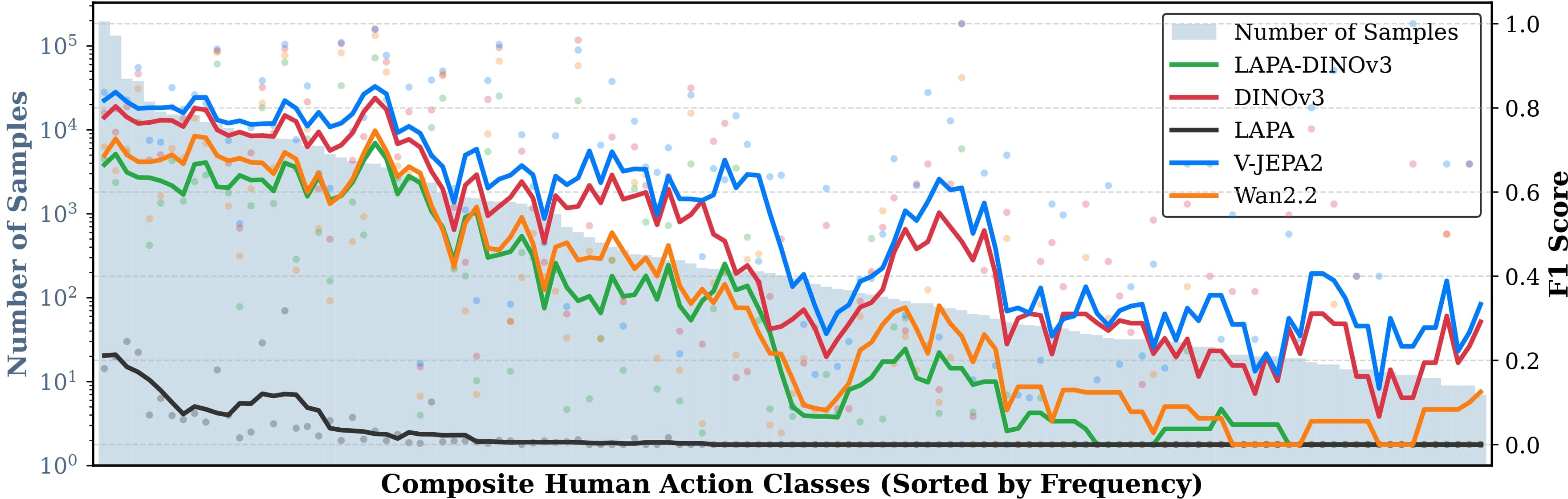
Figure 7: Composite Human classification performance over the long-tail action distribution. Strong models widen the generalization gap on rare actions.
The gap between strong (general vision models) and weak (embodied) models is amplified on long-tail, low-frequency actions, highlighting the necessity of broad visual pre-training for rare event generalization.

Figure 8: Cross-attention heatmaps reveal spatiotemporal grounding of actions, with encoder-based models sharply focusing on interactive loci while generative and embodied models display diffuse, unlocalized attention.
Attention heatmaps confirm that continuous vision encoders more reliably localize attention on key interaction loci; embodied LAMs and pixel-based models tend toward unfocused, globally diffused attention, corroborating their poor semantic and physical alignment.
Cross-Domain Generalization
A cross-embodiment analysis of F1-score discrepancies between shared action categories (e.g., pick, place, twist) demonstrates that General LAMs, despite improvements, retain a human-centric bias, whereas DINOv3 and related encoders achieve balanced domain-agnostic performance. Embodied LAMs slant toward robots but at much lower overall precision.
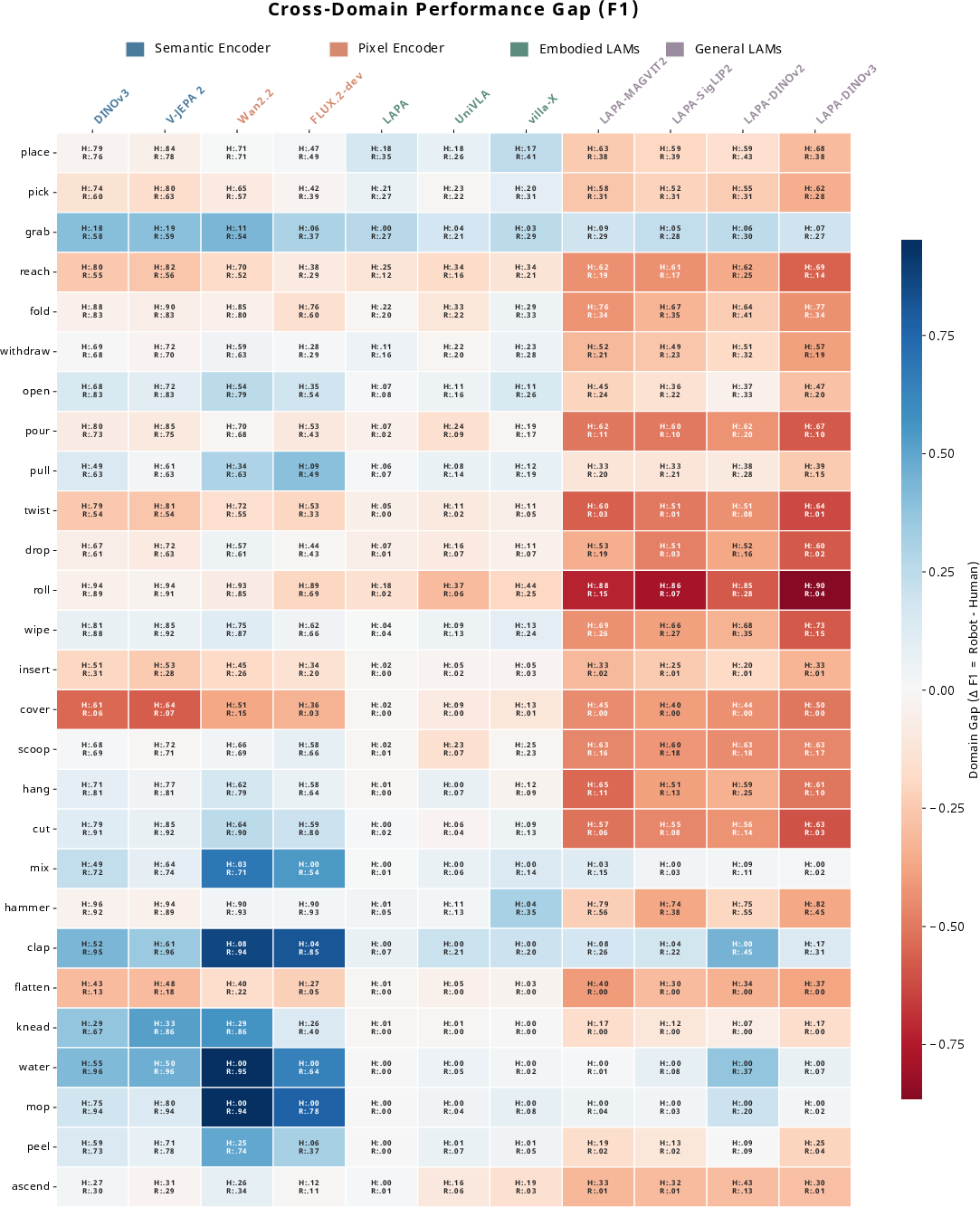
Figure 9: Performance gap heatmap between human and robot domains for shared semantic actions, highlighting morphological biases and dataset-induced imbalance.
Representative Visual Examples
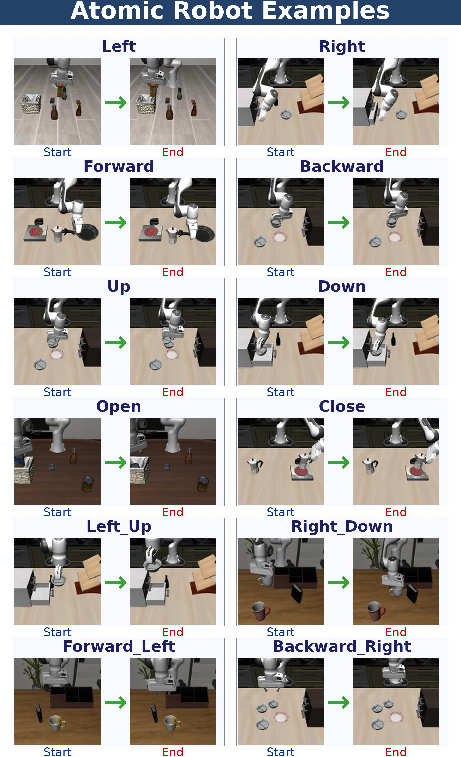
Figure 10: Examples of atomic robot primitives with discrete, structured spatial displacements and state changes.

Figure 11: Representative composite human actions curated via LARY’s pipeline.

Figure 12: Composite robot behaviors sourced from AgiBotWorld-Beta, extending semantic taxonomy across embodiments.
Implications and Future Directions
The findings from LARYBench substantiate two strong empirical claims:
- General visual foundation models encode action-relevant knowledge sufficient for both semantic abstraction and physical control, outperforming specialized LAMs trained on scarce embodied data.
- Latent feature representations, above pixel-level ones—even absent action supervision—provide more robust alignment to robotic control and action semantics.
These results call for a paradigm shift in VLA research: scaling policy learning with richly pretrained vision encoders and focusing research efforts on reliable feature-to-control alignment, rather than on further architectural specialization or increased data collection in the robot domain. The authors suggest that overcoming practical constraints such as robust continuous decoding and improved feature-to-policy mapping will be pivotal.
Potential avenues for extension include enhanced domain adaptation techniques, more effective continuous signal alignment, and leveraging LARYBench as a testbed for future multitask and open-world policy learning research.
Conclusion
LARYBench represents a significant advance in the systematic, multi-faceted evaluation of latent action representations across embodied intelligence. The evidence from this benchmark decisively supports the superiority of general visual foundation models in encoding both semantic and physical action features, motivating a strategic realignment toward leveraging general visual priors in vision-to-action architectures. Progress in bridging the gap between foundation visual models and robust, generalized robotic control will rely on architectures and training strategies that fully exploit this latent representational richness.
Reference:
LARY: A Latent Action Representation Yielding Benchmark for Generalizable Vision-to-Action Alignment (2604.11689)