- The paper introduces a GPU-accelerated SpMSpM algorithm for sparse fully homomorphic encrypted DNNs, yielding 2.5–3.0× speedups over CPU benchmarks.
- It leverages a hybrid CSR/CSC and VCSR format to optimize ciphertext rotations, relinearization, and rescaling, thereby reducing both runtime and computational complexity.
- The approach enables scalable, privacy-preserving DNN inference by balancing sparse data representation with minimal accuracy loss under the CKKS scheme.
GPU Acceleration of Sparse Fully Homomorphic Encrypted DNNs
Introduction and Problem Motivation
Fully homomorphic encryption (FHE) enables computation directly on encrypted data, providing a strong privacy-preserving computing paradigm applicable to sensitive domains such as machine learning on confidential datasets and secure outsourced analytics. However, the computational overhead inherent in FHE is a substantial barrier to practical adoption, especially for data-intensive workloads involving deep neural networks (DNNs). Ciphertext expansion and high algorithmic complexity mean that critical DNN primitives—particularly matrix multiplication (matmul)—are orders of magnitude slower under FHE than on plaintext data. This is compounded by the hardware-unfriendliness of FHE, as ciphertext size (tens to hundreds of MB for 128-bit security settings) and evaluation key usage outstrip typical cache and memory system capacities.
Recent algorithmic progress has improved FHE matmul feasibility, but main bottlenecks such as ciphertext rotations, key switching, and poor exploitation of data sparsity—especially when packing data to leverage SIMD execution—remain unsolved for high-throughput deployments. The lack of practically efficient sparse matmul for FHE impedes scaling to realistic DNN sizes and limits FHE's use in privacy-critical AI applications.
Contributions and Technical Approach
This paper proposes a novel, GPU-optimized implementation of sparse matrix-matrix multiplication (SpMSpM) for FHE, specifically targeting DNN workloads that exhibit operand sparsity. The core technical innovations are:
- A new algorithm for GPU-accelerated, ciphertext-ciphertext SpMSpM exploiting unstructured sparsity in both operands, using a hybrid compressed sparse row (CSR) and compressed sparse column (CSC) representation.
- Optimized execution on modern AMD GPUs, leveraging high parallelism and bandwidth, and using FIDESlib—a recent open-source FHE library tailored for CKKS evaluations on GPUs.
- Efficient handling of FHE-specific costs such as ciphertext rotations, relinearization, and rescaling, through an aligned data layout and minimal-movement access pattern.
- Support for advanced GPU sparsity formats, introducing an adaptation of the vertical CSR (VCSR) format to maximize thread-level parallelism and coalesced memory accesses.
Unlike prior CPU-based or dense-encrypted methods, this work supports encrypted-encrypted matrix multiplication, generalizing beyond the semi-honest settings where a plaintext operand can be assumed.
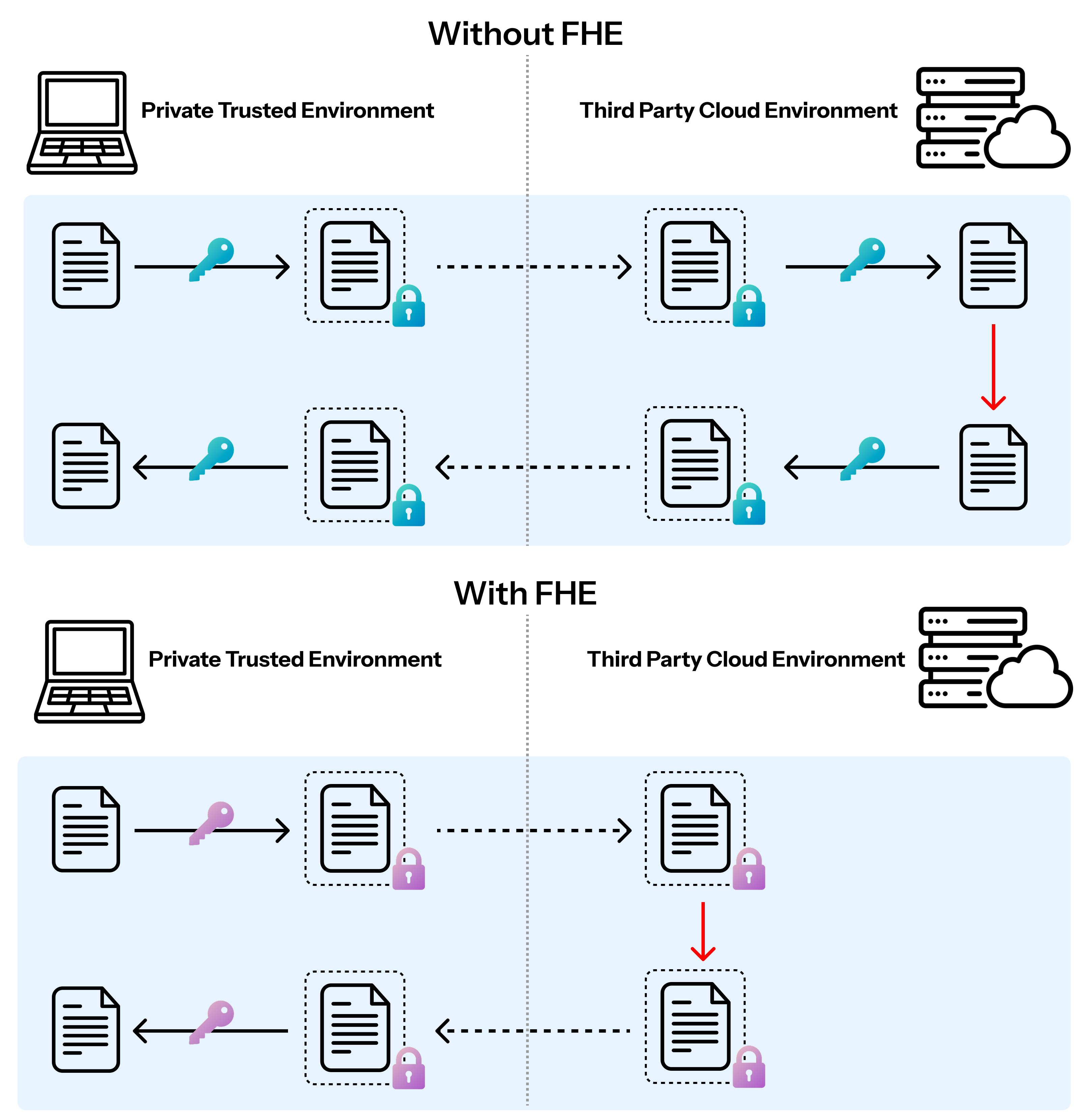
Figure 1: A schematic of FHE-based cloud computing: With FHE, all computation occurs on encrypted data, eliminating exposure outside the trusted perimeter.
Methodology Details
The method stores the left-hand matrix in CSR (row-wise) and the right-hand matrix in CSC (column-wise), aligning nonzero values for optimal traversal and reducing unnecessary key switching and ciphertext rotation events. For each (i,j) matrix position:
- Identify NZV pairs in the CSR row i and CSC column j; if matching column/row indices are found, rotate only one ciphertext to align, rather than both.
- Perform a homomorphic multiplication and mask the result via plaintext masking to isolate the output coordinate.
- Apply relinearization and rescaling to control noise and scale growth post-operation.
- Accumulate the masked product at the correct location in the output ciphertext through rotation and slot addition.
The method is further adapted to VCSR (and VCSC), enabling more efficient batch coordinate access aligned with GPU memory hardware.
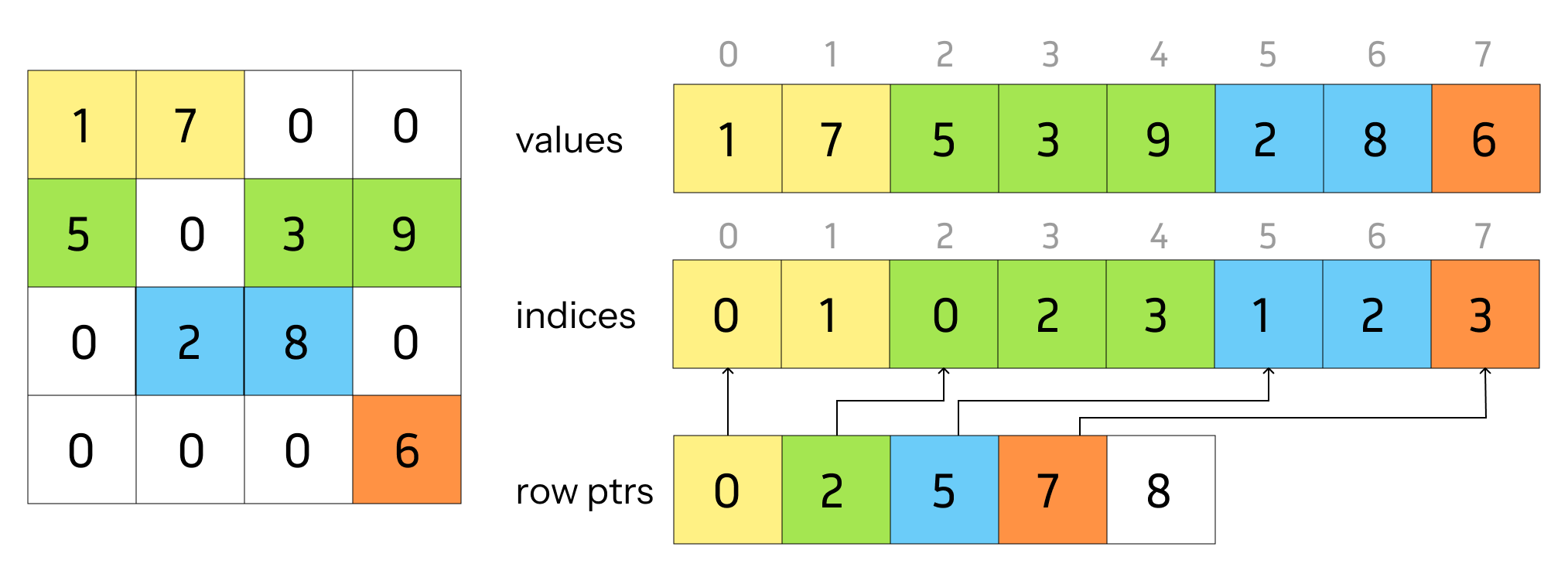
Figure 2: Example of a matrix in CSR format, highlighting the efficiency of sparse representation for GPU computations.
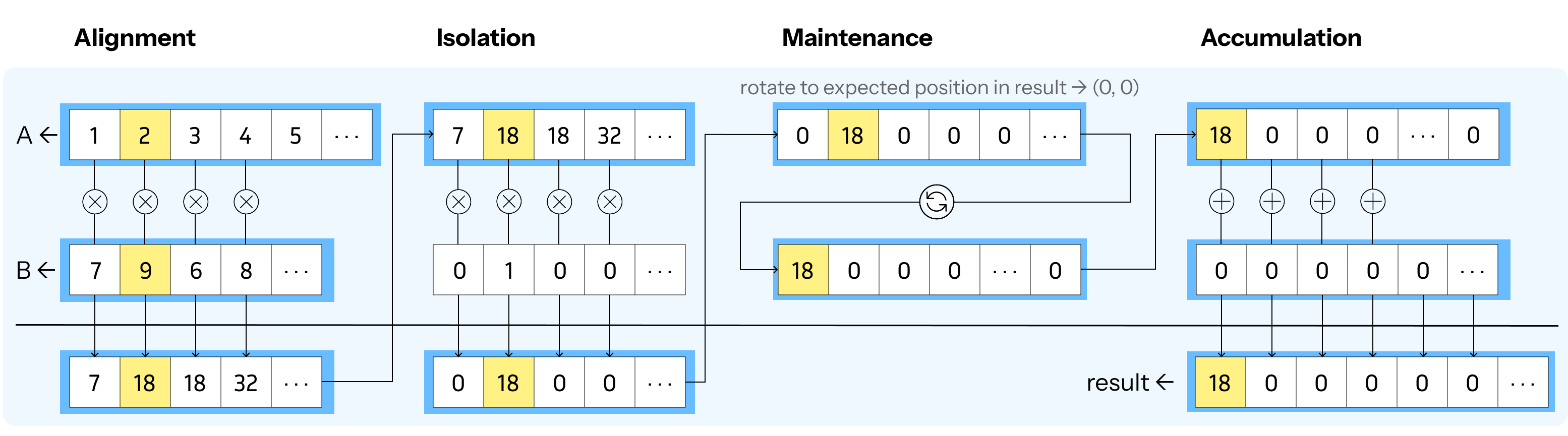
Figure 3: Illustration of the SIMD operations central to FHE CKKS matmul, where encrypted vectors are operated on in parallel, exploiting GPU parallelism and data packing.
Evaluation and Results
Extensive experimental analysis was carried out on AMD Radeon RX 7900 XT and Instinct MI300X GPUs, implementing all methods in HIP-compatible C++ code via FIDESlib. Key baselines include naïve dense matrix multiplication and recent CPU-based FHE matmul libraries (OpenFHE).
Primary experimental findings:
- Runtime: Across varying matrix sizes (up to 16x16) and sparsity levels (0–100%), the proposed CSR/CSC and VCSR/VCSC GPU algorithms yield speedups of 2.5–3.0× over CPU OpenFHE baselines, and exponential acceleration over naïve dense implementations in highly sparse regimes.
- Scalability: GPU methods outperform classical CPU-based approaches at all sparsity levels, with greater gains as sparsity increases. CSR/C consistently outperforms other sparse implementations and, notably, is faster than dense methods even at 0% sparsity.
- Accuracy: Output error, benchmarked via the Frobenius norm against plaintext results, is minimal and dominated by CKKS scheme approximation noise, not by sparse representation artifacts. Approximation error reduces further as sparsity increases.
- Time Complexity: By leveraging sparse layout, algorithmic complexity is reduced from cubic O(N3) in the dense case to semi-linear O(N⋅k) where k is the combined number of NZVs, realizing substantial work savings in practical DNNs.
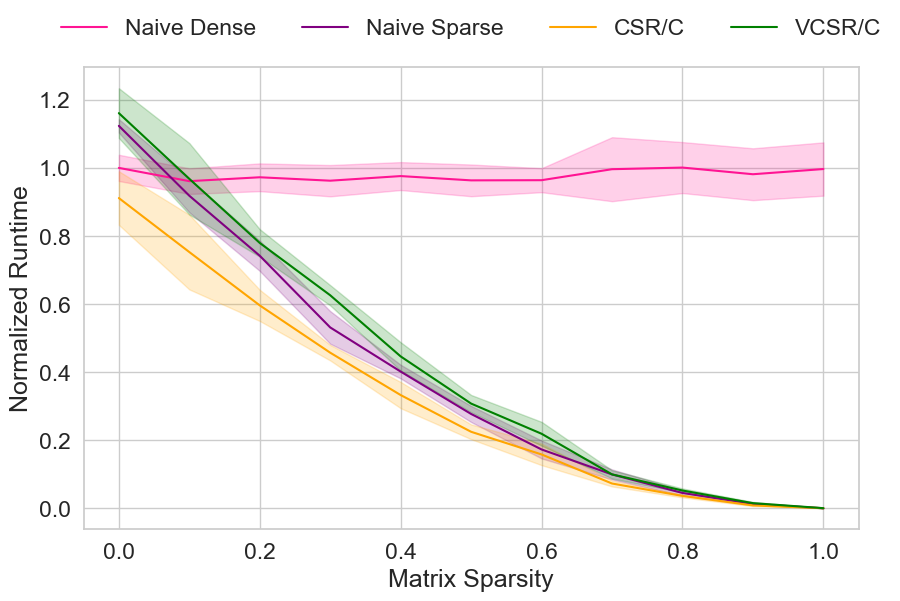
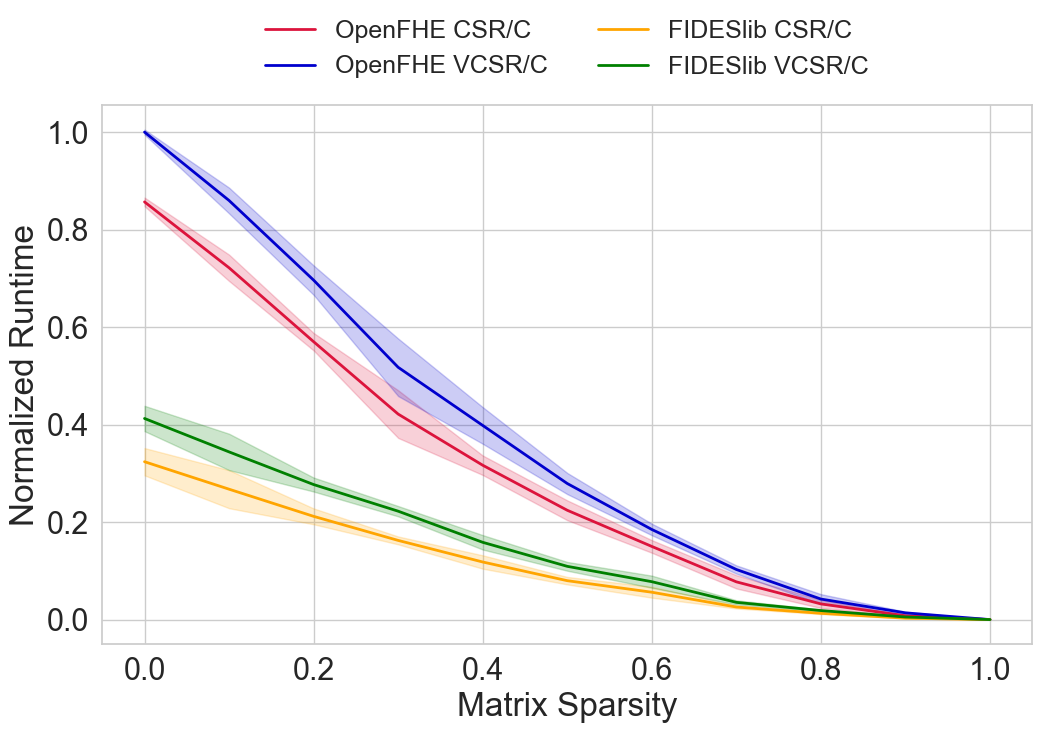
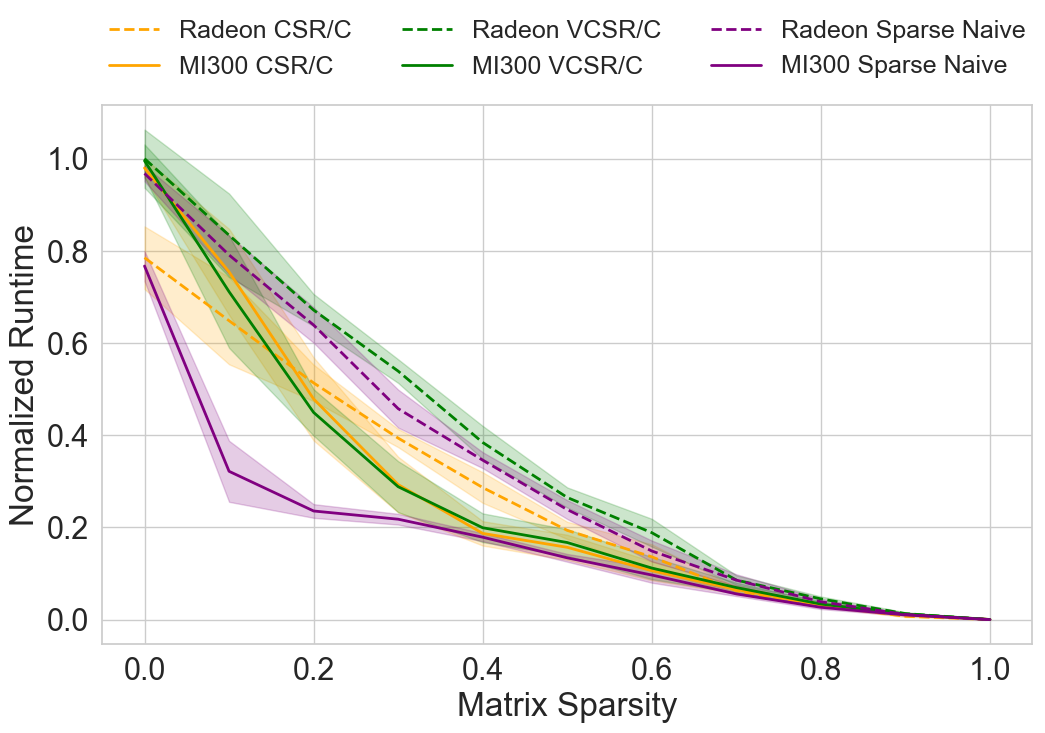
Figure 4: Empirical runtime performance of FIDESlib on Radeon, exhibiting strong speedup for CSR-based methods as sparsity increases.
Security and Privacy Implications
While structural metadata (row/column pointers) must be exposed in plaintext for sparse acceleration—potentially leaking limited information about the nonzero pattern—all numerical matrix entries remain encrypted for strong confidentiality. For DNN inference, model weight sparsity is often public, but activation sparsity may leak input information if not carefully managed. The methodology enables practical design trade-offs, allowing the selective exploitation of weight vs. input sparsity in alignment with threat models.
Theoretical and Practical Implications
This work demonstrates the feasibility of deploying privacy-preserving DNN inference with encrypted weight and activation matrices at practical performance on commodity GPU hardware. The reduction in time and space complexity greatly expands the tractable matrix size regime for FHE-secure AI deployment, particularly in settings where operand sparsity can be induced via model pruning, quantization, or structured sparsity techniques. The framework is also directly applicable to privacy-preserving recommendations, secure graph analytics, and encrypted scientific computing.
From a hardware–software co-design standpoint, the results show that FHE workloads are sufficiently bandwidth-limited and parallel-friendly to benefit substantially from modern GPU architectures, motivating future accelerator designs optimized for encrypted sparse algebra.
Future Directions
Further research is expected to benchmark at larger matrix scales, address format conversion and system-level overheads, and co-design sparsity-aware DNN training pipelines aligned with FHE constraints. The development of automated, privacy-preserving pruning or quantization methods that expose sparsity while minimizing sensitive information leakage could further accelerate adoption. Additionally, joint optimizations with bootstrapping and advanced approximate-FHE schemes may shrink ciphertext expansion and cost even further.
Conclusion
The paper establishes a practical, generalizable method for accelerating encrypted sparse matrix-matrix multiplication on GPUs. By combining FIDESlib’s optimized CKKS primitives with hybrid CSR/CSC and VCSR/VCSC layouts, the approach achieves a significant reduction in runtime and algorithmic complexity for core DNN operations under FHE. This work is a foundational step toward practical, privacy-preserving encrypted AI, extending FHE to real-world neural network inference and analytics workloads.

