- The paper develops an information-theoretic method using second-order Markov models to quantify phonological distances across languages.
- It validates Wasserstein distances with feature-embedded triphone distributions to uncover typological and genealogical language clusters.
- The study correlates phonological divergence with geographic separation to statistically support the Steppe Hypothesis for the Indo-European homeland.
Quantifying Phonological Distances and Locating the Indo-European Homeland
Introduction and Theoretical Motivation
The paper "Phonological distances for linguistic typology and the origin of Indo-European languages" (2604.11565) develops an information-theoretic methodology for quantifying sound-based distances among languages and demonstrates that these distances not only reflect typological and genealogical relations, but also correlate with geography. The authors leverage a parallel multilingual corpus to avoid register and genre bias, focusing specifically on phoneme sequence statistics. By casting phonological systems as second-order Markov processes, they provide a robust, reproducible pipeline for extracting, comparing, and interpreting quantitative phonological distances at scale, with downstream application to major open questions in historical linguistics such as the homeland problem of the Indo-European (IE) family.
Markov Modeling of Phonological Sequences
The study treats phonemic transcription sequences as outputs of a stationary stochastic process, with language-specific inventories ranging from L=26 (Finnish) to L=59 (Hindi). Crucially, the order of phoneme dependencies is inferred by computing the block entropy Hr as a function of contiguous r-phone subsequences. The predictability gain, Gu, derived as the second difference of Hr, quantifies how much additional Markov memory improves predictability.
The analysis reveals that all studied languages, when abstracted to the phoneme level, are well-modeled by second-order Markov chains: including dependencies up to two preceding phonemes captures nearly all relevant conditional structure, with higher-order gains being negligible. Consequently, 3-phone (triphone) probability distributions can serve as comprehensive statistical proxies for a language's phonology.
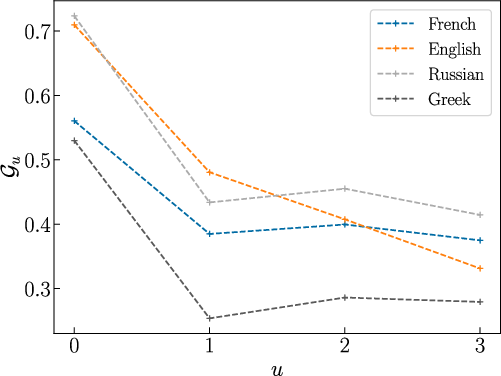
Figure 1: Predictability gain Gu as a function of phonological block size for selected languages, demonstrating rapid entropy saturation at u=2.
When phoneme classes are pooled via feature-based coarse-graining (voicing for consonants, openness/backness for vowels), this trend persists and Markov order two is sufficient.
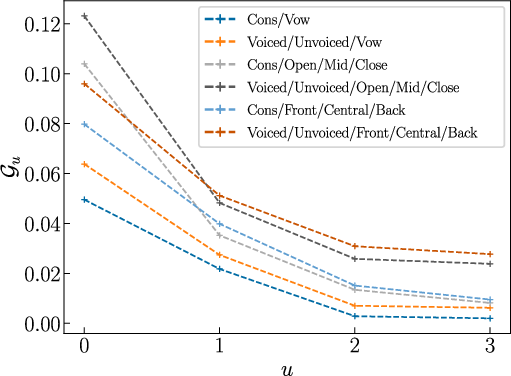
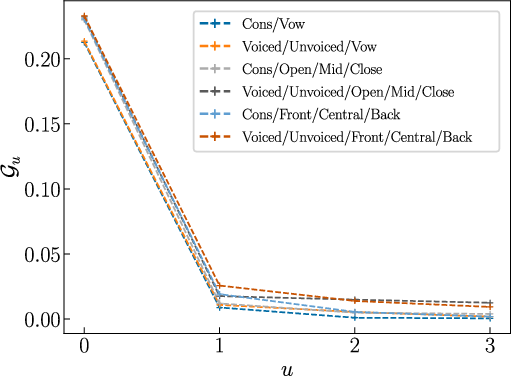
Figure 2: Predictability gain as a function of block size for various English and French coarse-grainings; Markov order two remains optimal under class grouping.
Feature-Based Distance Metric
For each language, the empirical distribution over 3-phones is calculated from the corpus. To address the limitation that frequency-based divergences (e.g., L1 or L2 distances) treat all symbols as maximally dissimilar, each 3-phone is embedded as a concatenation of articulatory feature vectors, following the PanPhon scheme with 24 binary features per phoneme. The phonological distance between two languages is then the optimal transport (Wasserstein) distance between their 3-phone distributions, with ground costs specified by feature edit distance.
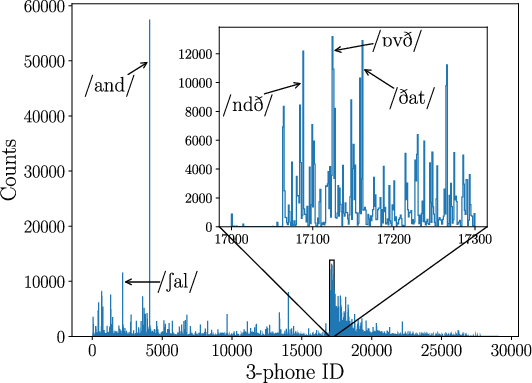
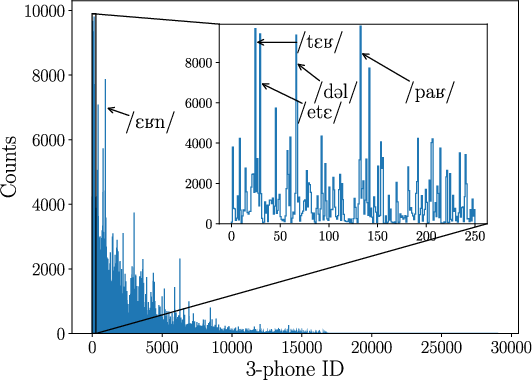
Figure 3: 3-phone distribution for English and French; high-frequency items correspond to frequent function words, reflecting language-specific phonotactics.
The choice of Wasserstein distance with feature-based ground costs, rather than edit or Hamming distances, is empirically validated: it minimizes spurious inflation of dissimilarity when similar phones or triphones are present.
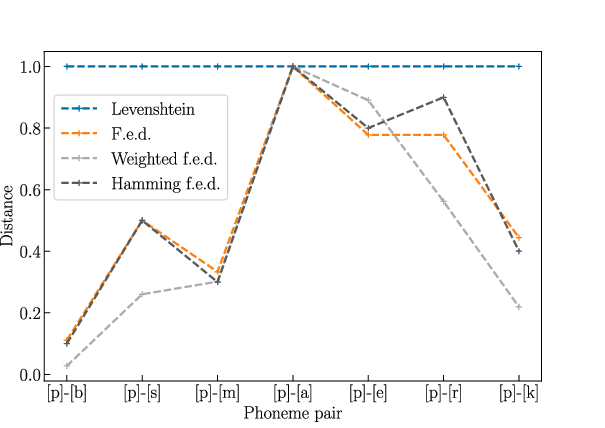
Figure 4: Comparative analysis of alternative feature vector distances; unweighted feature edit distance achieves maximal typological sensitivity with lower computational overhead.
Phonological Distance Matrix and Typological Clustering
The resulting phonological distance matrix among 67 languages reveals typologically and genealogically congruent clusters under hierarchical Ward linkage. Major Indo-European branches (Germanic, Slavic, Romance, Indo-Aryan) are recovered, as well as coherent groupings for Turkic languages (regardless of the controversial status of Altaic), Dravidian, Finno-Ugric, and contact-induced clusters (e.g., Basque-Spanish, Romanian-Italo-Western Romance). Crucially, observed clusters track phonological similarity, not genealogical descent exclusively—language contact and geographical proximity also play a significant role.
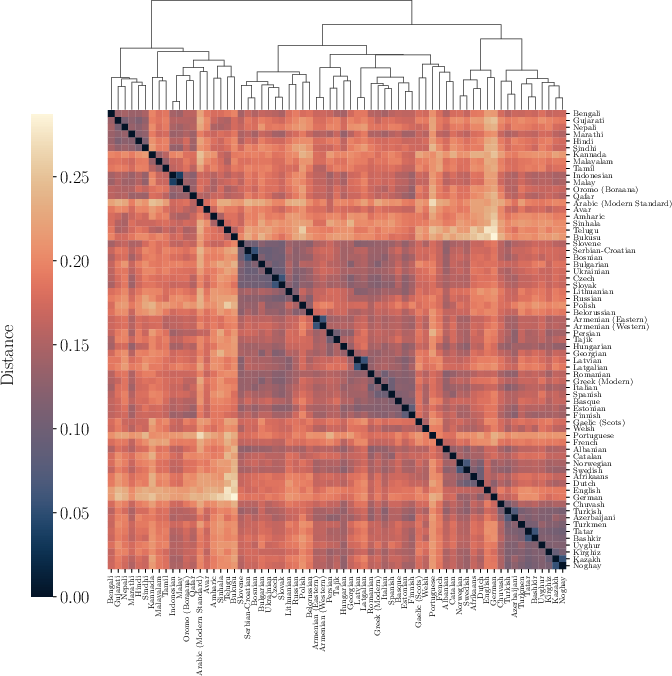
Figure 5: Heatmap of phonological distances and the resulting hierarchical clustering, recovering major language families and contact-induced typological convergence.
Subset analysis of Indo-European languages alone corroborates standard subgroupings (Indo-Aryan, Balto-Slavic, Germanic, Romance), while also exposing the influence of geographic and contact factors.
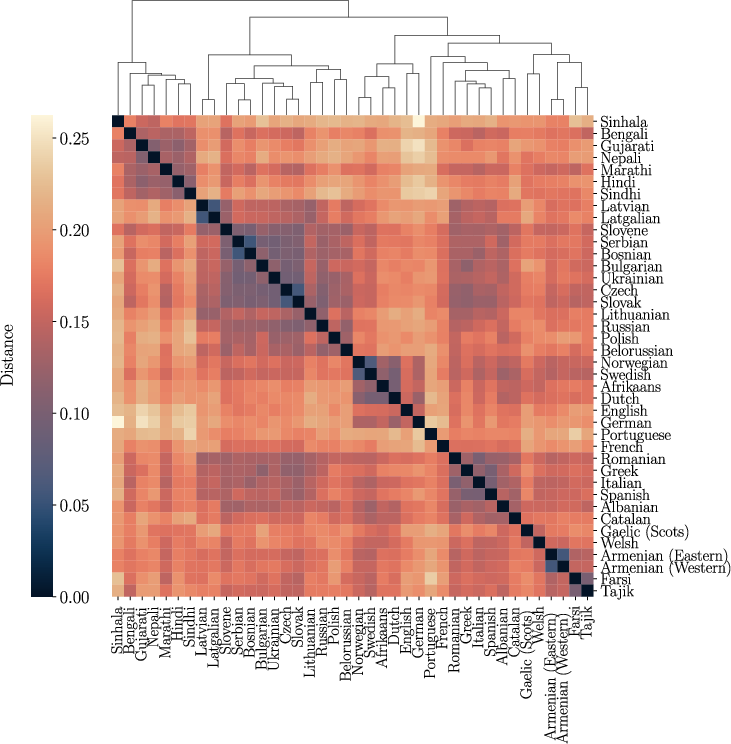
Figure 6: Indo-European sub-matrix; Balto-Slavic and Germanic subfamilies emerge cleanly, with Albanian and Greek clustering alongside Romance.
Geography–Phonology Correlation and the IE Homeland
Distance correlation analysis reveals a significant monotonic relationship between phonological and geographic distances (L=590 for IE, L=591 overall, empirically significant with L=592): the farther two languages are in geographic space, the greater their phonological divergence, with a logarithmic fit capturing the dependence.
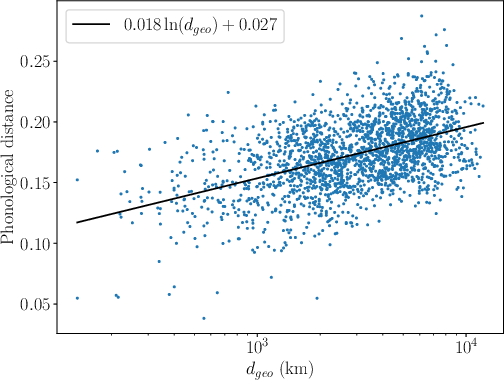
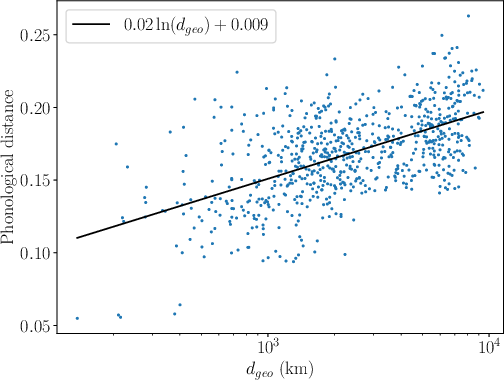
Figure 7: Pairwise Wasserstein phonological distance plotted against geographic separation; correlation is well fit by a logarithmic model for Indo-European and full language sets.
Leveraging this correlation, the authors propose a new statistical method for estimating the most probable homeland of the IE family by minimizing the summed squared discrepancy between observed phonological divergence from the mean IE triphone system and predicted geographic divergence from a candidate homeland. Sampling over uncertainty distributions yields a 95% plausible region for the ancestral homeland.
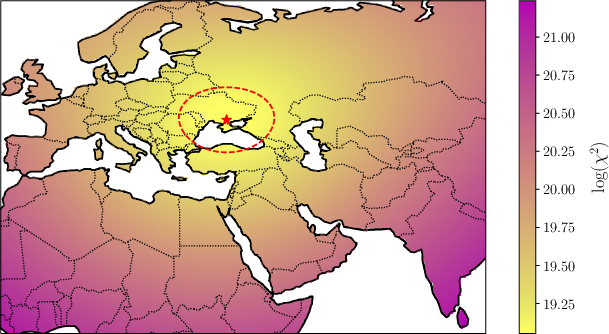
Figure 8: Sum of squared error heatmap for Indo-European languages: minimal residual and corresponding uncertainty region indicated north of the Black Sea, consistent with the Steppe Hypothesis.
This approach identifies the Pontic steppe (north of the Black Sea) as the most likely origin for IE, aligning with the Kurgan/Steppe hypothesis and recent genetic evidence, and inconsistent with claims for an Anatolian homeland.
Implications, Limitations, and Future Directions
The presented methodology provides a scalable, data-driven framework for quantitative linguistic typology and phylogeography, with formal grounding in information theory and statistical learning. The clarification that short-range dependencies dominate phonological structure generalizes across an extensive, typologically diverse corpus, and the statistical indistinguishability of triphone models for genealogically related languages underscores the value of sequential phoneme modeling as an alternative to lexicon- or grammar-based approaches.
Notably, the main claims rest on parallel corpus construction, second-order Markov approximations, and carefully validated feature-based alignments. Limitations include the moderate sample size (67 languages, under-representation of non-IE families), model synchrony (no diachronic inference), and the use of point-based, rather than area-based, geographic assignments. Future work could extend the framework to dialectal varieties, sociophonetic stratification, diachronic corpora, or combine with Bayesian inference for phylogenetic dating and model residual spatial autocorrelation.
Conclusion
This paper establishes a rigorous quantitative pipeline connecting phonological sequence statistics, typological family structure, and language geography. It demonstrates that second-order Markov processes suffice to capture cross-linguistic phonological dependency and that optimal-transport distances over feature-embedded phoneme trigrams recover not only major typological clusters but also contact-induced similarities. Most notably, it presents a statistically robust constraint on the Indo-European homeland consistent with steppe-based dispersal. The approach is extensible to both broader language samples and diachronic change models, with substantial implications for empirical typology, areal linguistics, and quantitative historical linguistics.