- The paper introduces a vision-driven system that retargets human upper-body motions into an 8-DoF robotic configuration.
- It employs capsule-based collision geometry with a CBF-QP layer to enforce real-time self and human-robot collision avoidance.
- Simulation results validate the approach by maintaining safety margins and demonstrating GPU-accelerated performance for practical deployment.
Safe Human-to-Humanoid Motion Imitation via Capsule-Based Control Barrier Functions
Overview of the Framework
The paper "Safe Human-to-Humanoid Motion Imitation Using Control Barrier Functions" (2604.11447) introduces an integrated, vision-based system for real-time imitation of human upper-body motion by a humanoid robot, focusing specifically on collision-aware safety. The framework leverages monocular camera-based human keypoint detection, retargets these observations into the robot's joint space, and employs a Control Barrier Function (CBF) layer—formulated as a Quadratic Program (QP)—to ensure both self-collision and human-robot collision avoidance. The architecture is highly adaptable and designed for deployment both in simulation and on real-world hardware.
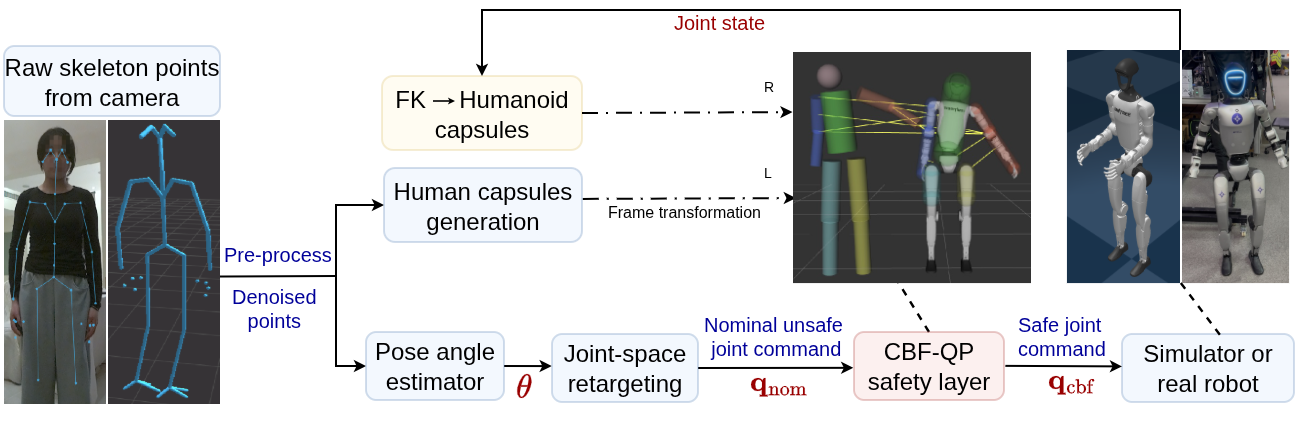
Figure 1: Overview of the proposed safe human-to-humanoid motion imitation framework.
Vision-Driven Pose Estimation and Retargeting
The perception pipeline utilizes a single camera to extract human skeletal keypoints, followed by signal filtering with an EMA and jump rejection to suppress noise artifacts. Pose estimation is reformulated to avoid solving full-body inverse kinematics, instead producing a reduced 8-DoF representation encompassing torso roll/pitch, bilateral shoulder pitch/roll, and elbow pitch angles. The estimate is constructed in a body-centered frame, dynamically registered to the human demonstrator.
The robot's imitation space is defined by upper-body joint angles, with an affine retargeting map that projects the human pose vector to the admissible range of the robot's configuration space. This retargeting includes explicit joint-limit enforcement through element-wise clipping and calibration offsets, establishing a robust nominal command as input to the safety layer.
Both the human and robot are modeled with a 7-capsule abstraction, covering major upper-body links, which offers a compact and differentiable representation for proximity calculations. Robot capsule endpoints are dynamically updated via FK, while human capsule geometry is reconstructed from the processed skeletal keypoints. All human capsules are referenced into the robot’s frame for unified collision monitoring.
Safety is enforced by defining a distance-based CBF for every meaningful pair of robot-robot and robot-human capsules, parameterized by a tunable barrier margin ϕ. The CBF-QP is posed at the velocity level: for each control step, the robot seeks to follow a reference velocity (towards the retargeted pose), while satisfying a linear CBF constraint per active collision pair. This guarantees forward-invariance of the safe set, ensuring that all motion commands respect the minimum separation condition.
Simulation studies expose two critical cases: self-collision risk via cross-arm reach and human-robot collision in a side-by-side arm raise. The CBF-QP intervention is visually and numerically analyzed; when the robot’s arms approach unsafe configurations—either intersecting its own body or encroaching on the designated human region—the CBF constraints activate, reshaping the velocity command to preserve safety margins while minimizing deviation from the demonstrator’s intent.

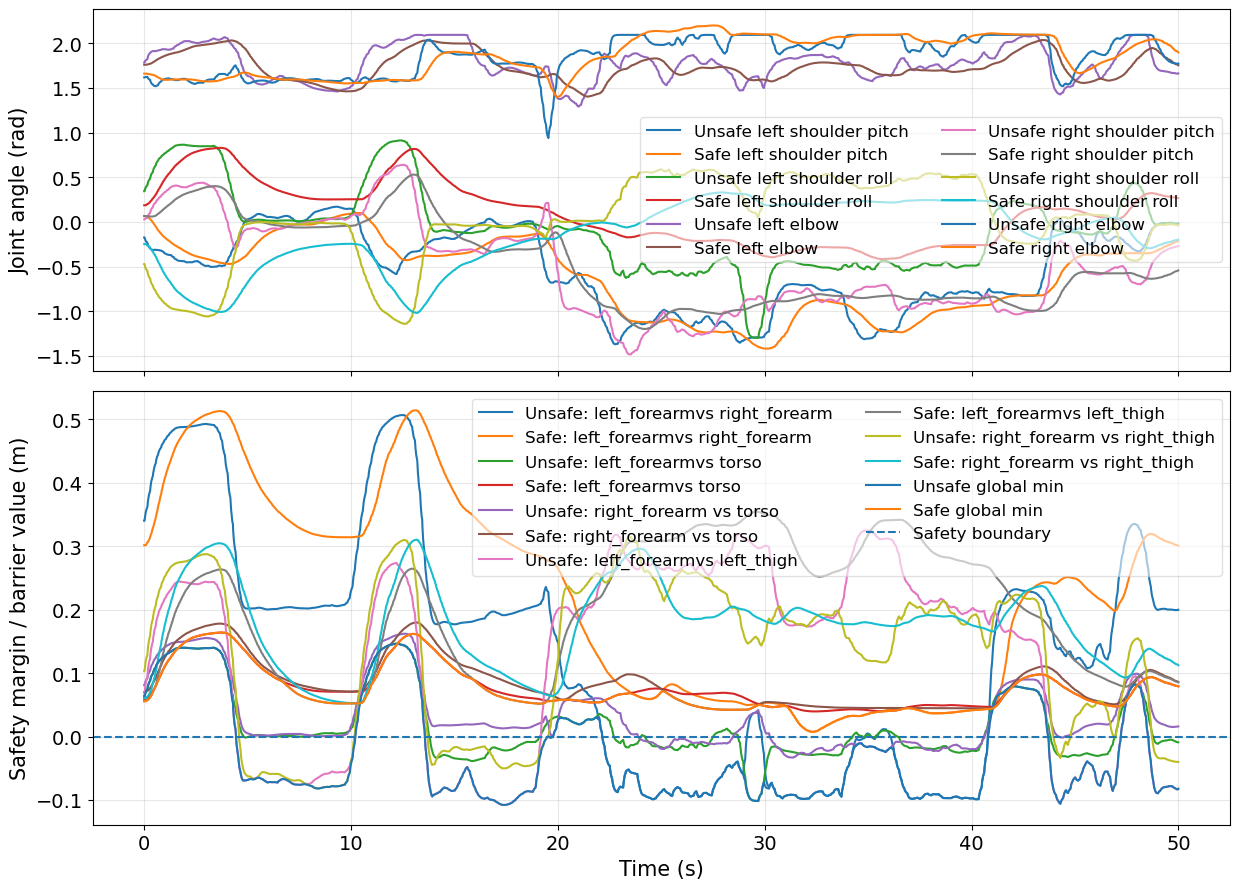
Figure 2: Cross-arm reach scenario; the ghost robot (left) violates arm collision constraints, while the CBF-filtered robot (right) respects the defined safety margin.
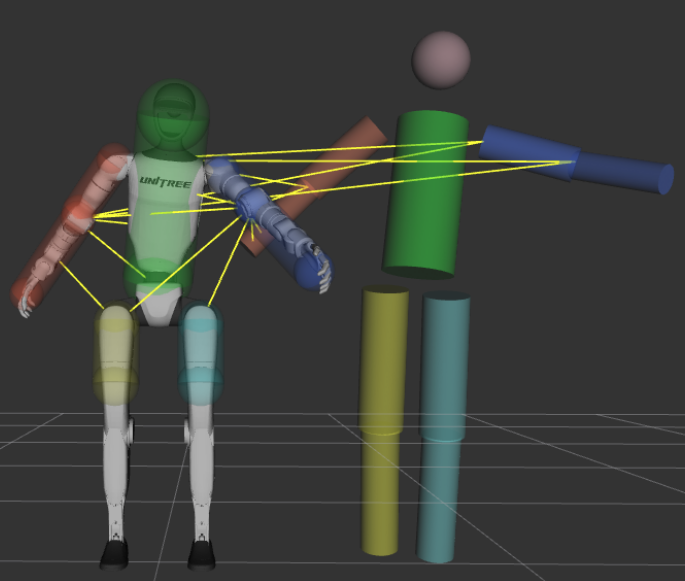
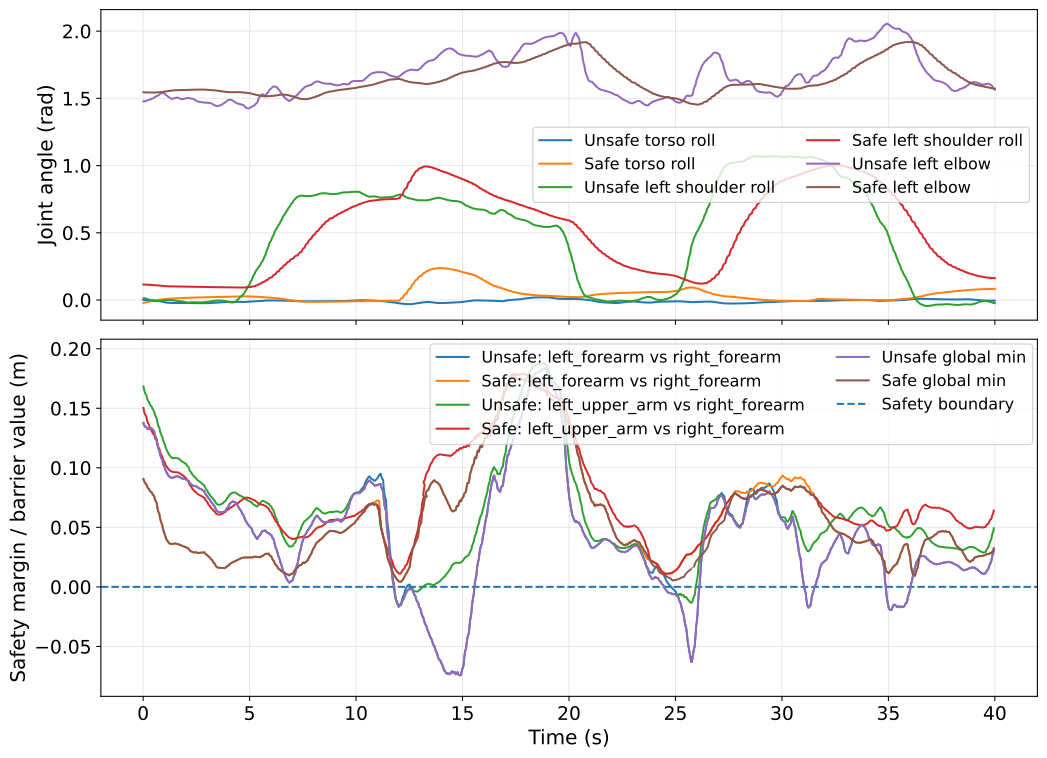
Figure 3: Side-by-side arm raise; yellow segments indicate CBF-monitored capsule pairs, enforcing collision avoidance in proximity to the human.
The results decisively indicate that, without the CBF-QP filter, the robot breaches the safety boundaries in both cases, while the proposed architecture achieves strict collision avoidance. Quantitative safety margins are maintained throughout, with the system flexibly reverting to nominal imitation in non-critical configurations.
Evaluation of Collision Geometry Models and Computational Tradeoffs
A systematic benchmark compares the capsule-based CBF-QP to alternative collision primitives including multi-sphere and bounding-box decompositions. Capsule geometry achieves the best trade-off between model fidelity, number of required constraints, and solve time—especially when leveraging GPU-accelerated computation. Notably, GPU-backed capsule models sustain update rates exceeding 30 Hz, even with all differentiable proximity checks and kinematic derivatives executed in parallel.

Figure 4: Benchmarked collision geometry (sphere, bounding box, and capsule). Lines represent active CBF constraints at run time.
Sphere and box models are computationally competitive only for coarse decompositions, but suffer from combinatorial constraint generation and inferior geometric approximation of elongated robot and human body parts. Capsule models, by contrast, allow for minimal pairwise constraints with high descriptive power and computational tractability.
Implications and Prospects
The integration of differentiable capsule-based CBF-QP safety filtering with vision-driven imitation establishes a scalable paradigm for safe, interactive humanoid control. Practically, this approach can be directly transposed to physical platforms, with the primary bottleneck being the real-time perception and QP solve latency—well within the bounds demonstrated herein when using contemporary GPU computation.
Theoretically, the work clarifies how CBFs, traditionally used for robotic navigation and low-DoF manipulators, robustly generalize to high-DoF, vision-in-the-loop humanoid systems, including the simultaneous enforcement of multiple dynamic separation constraints.
Future directions include heterogeneous collision primitives for finer contact modeling, automatic selection of active constraint pairs to further reduce QP dimensionality, improved imitation fidelity metrics, and large-scale validation on hardware platforms operating alongside uninstrumented humans.
Conclusion
This work delivers a formal vision-to-control pipeline for safe human-to-humanoid motion imitation, unifying real-time pose estimation, joint-space retargeting, and capsule-based CBF-QP safety filtering. The system achieves responsive, collision-aware behavior in simulation, demonstrating clear advantages over existing abstraction and constraint formulations. These results set a baseline for future research on scalable, safe, interactive humanoid operation in unconstrained environments.