- The paper introduces a novel method for synthesizing robot wrist-view observations and trajectories directly from egocentric human demonstrations.
- It employs advanced vision models and differentiable Gaussian Splatting to achieve robust hand-object tracking and high-fidelity retargeting.
- Experimental results show a 5–8× faster data collection with comparable or superior performance to conventional teleoperation across diverse tasks.
WARPED: Wrist-Aligned Rendering for Policy Learning from Egocentric Human Demonstrations
Introduction and Motivation
Autonomous robotic manipulation via visuomotor policy learning traditionally incurs significant overhead in demonstration data collection, commonly demanding teleoperation and specialized multi-sensor setups. WARPED introduces a monocular, RGB-only methodology that synthesizes robot wrist-view observations and end-effector-aligned action trajectories directly from egocentric human video. The approach notably eliminates dependencies on multi-view sensing, depth sensors, or custom data collection hardware, thus drastically reducing task-specific data collection effort and supporting rapid bootstrapping of new manipulation capabilities. By leveraging advanced vision foundation models for scene understanding, hand-object tracking, and differentiable rendering via Gaussian Splatting, WARPED establishes a robust pipeline for translating human demonstration into high-fidelity robot data suitable for direct policy learning.

Figure 1: WARPED: A framework that warps egocentric human demonstrations into wrist-camera observations and trajectories for training robot policies.
WARPED Pipeline Overview
The WARPED system is composed of five key sequential modules:
- Data Collection: The workspace is initially scanned with a monocular egocentric RGB camera for static scene geometry reconstruction. Subsequently, task demonstrations are collected at high speed via human hand using only a head-mounted camera.
- Interactive Scene Initialization: Static scene geometry is constructed with Structure-from-Motion, and interactive object/hand poses are initialized leveraging vision foundation models (e.g., Grounding DINO, SAM2, SAM3D, MegaPose).
- Hand-Object Optimization: A differentiable, two-stage optimization refines hand-object poses, integrating occlusion-aware mask, depth, and DINOv2-based feature losses with geometric constraints, yielding accurate 3D tracking even under severe occlusion.
- Retargeting & Rendering: Human hand trajectories are mapped to robot end-effector references via a kinematic alignment approach using thumb/index contacts. The pipeline interpolates these for smooth robot execution and employs Gaussian Splatting to render photo-realistic wrist-aligned synthetic images for each trajectory step.
- Policy Training & Deployment: A diffusion policy is trained on the synthesized wrist observations and proprioceptive encodings, with heavy data augmentation to mitigate sim-to-real transfer and enhance generalization.
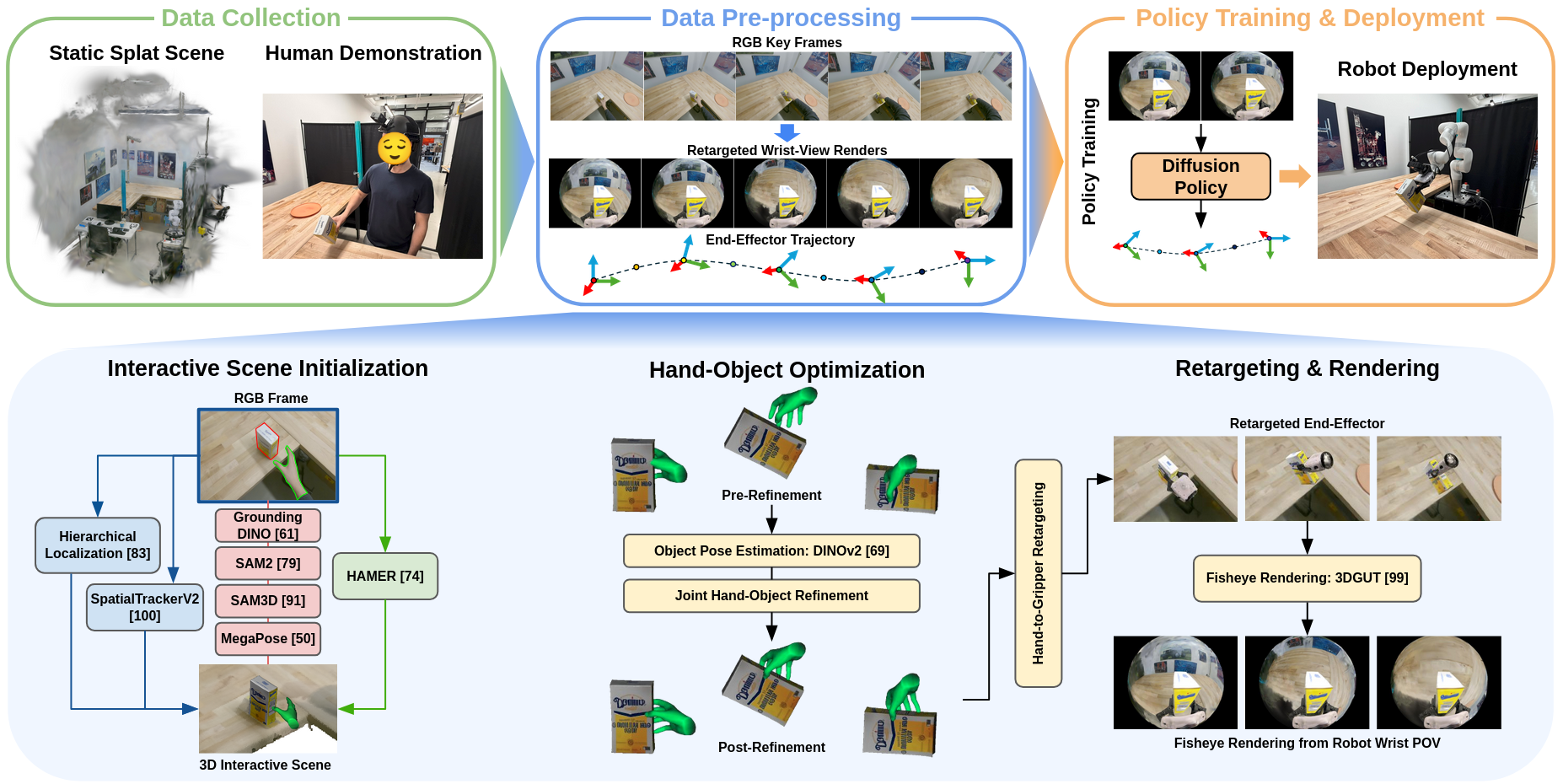
Figure 2: Overview of WARPED pipeline stages: monocular workspace scanning, egocentric human demonstration, scene alignment, vision model-based object localization, hand-object optimization, wrist-view rendering, and policy deployment.
Hand-Object Optimization Details
The system avoids reliance on extrinsic depth sensing by leveraging a hand-object interaction framework. Object pose is initialized per-frame via differentiable rendering, using occlusion-masked mask, depth, and DINOv2 feature alignment losses. Subsequently, a joint optimization is performed across all frames, adding physically informed constraints: contact maintenance between finger vertices and object surface, TSDF-based collision avoidance, temporal grasp stability, and scene contact (to mitigate floating artifacts).

Figure 3: Hand-object optimization pipeline: initial object pose via mask, depth, DINOv2, then joint refinement of hand and object for visual and geometric consistency.
Contact inference additionally determines pre-contact, contact, and post-contact windows, allowing different retargeting strategies for each regime. The result is temporally consistent 3D trajectories suitable for direct mapping to robot manipulation spaces.
Retargeting and Wrist-View Rendering
Retargeting leverages a fine-grained kinematic mapping from hand TCP to robot end-effector via thumb/index: the relative position and orientation of these points in the hand pose are transferred to define the desired robot gripper pose, with further optimization to ensure contact points are maintained and physically plausible. Pre-contact segments are optimized to avoid premature collisions, while post-contact frames follow object kinematics rigidly.
Synthetic wrist-view observations are rendered along the entire retargeted trajectory via 3D Gaussian Splatting over the jointly refined hand, object, and scene meshes. Extensive appearance, pose, and viewpoint domain randomization are applied for augmentation, including retexturing, scene scaling, and gripper pose noise.

Figure 4: (a) Hand contact points. (b) TCP mapping. (c)-(f) Contact optimization aligns the robot gripper with hand-object interface.

Figure 5: Demonstration and rendered wrist-view frames with augmentations of object appearance, pose, and gripper configuration.
Experimental Results
Experiments were conducted on five diverse tabletop manipulation tasks with a real robot platform, using only monocular human demonstrations as input data. Policies trained with WARPED achieve success rates comparable to or exceeding those trained on teleoperated data across most tasks:
- Rotate Box: 20/20 success (WARPED), outperforming teleoperation due to smooth kinematics from natural hand demonstrations.
- Pour Mug, Bottle from Rack, Can on Plate: Comparable success to teleoperated policies.
- Wipe Brush: Slightly underperforms teleoperation, attributable to small-object tracking challenges.
Data collection with WARPED is 5–8× faster than teleoperation, demonstrating a dramatic reduction in labor time.
Notably, WARPED policies display strong generalization to novel objects (category unseen during training) and also to out-of-distribution scene variations, with high robustness to background distractors not present during the scene initialization phase.

Figure 6: (a) Egocentric demonstration setup, (b) wrist camera on robot, (c) training objects, (d) novel objects for evaluation.

Figure 7: Policy rollouts on all evaluated tasks.

Figure 8: Robustness test: background distractor rollout for the Can on Plate task.
Comparison and Ablation
- Baselines: Policies using the Alter approach or naively overlaid rendered images significantly underperform WARPED, confirming the necessity of accurate hand-object geometry and photorealistic renderings.
- Teleoperation + WARPED: Combining both types of demonstrations yields maximal performance, indicating that wrist-aligned synthetic demonstrations are complementary to standard robot data.
- Ablations: Without data augmentation, performance drops precipitously. Without hand-object optimization, tracking quality (especially under occlusion) is severely degraded, impairing downstream manipulation.
Discussion and Limitations
WARPED conclusively demonstrates that high-fidelity wrist-view policy data can be synthesized from simple monocular, head-worn demonstration videos. This enables rapid scaling of robot manipulation capabilities in arbitrary environments without specialized hardware or sensors.
However, the system is currently limited to rigid object manipulation and quasi-static scenes. Articulated or deformable objects, and operation in dynamic settings, remain open challenges. Full occlusions of the manipulated object still cause failures; addressing these will require advances in monocular tracking and possibly integration with dynamic 3D scene representations.
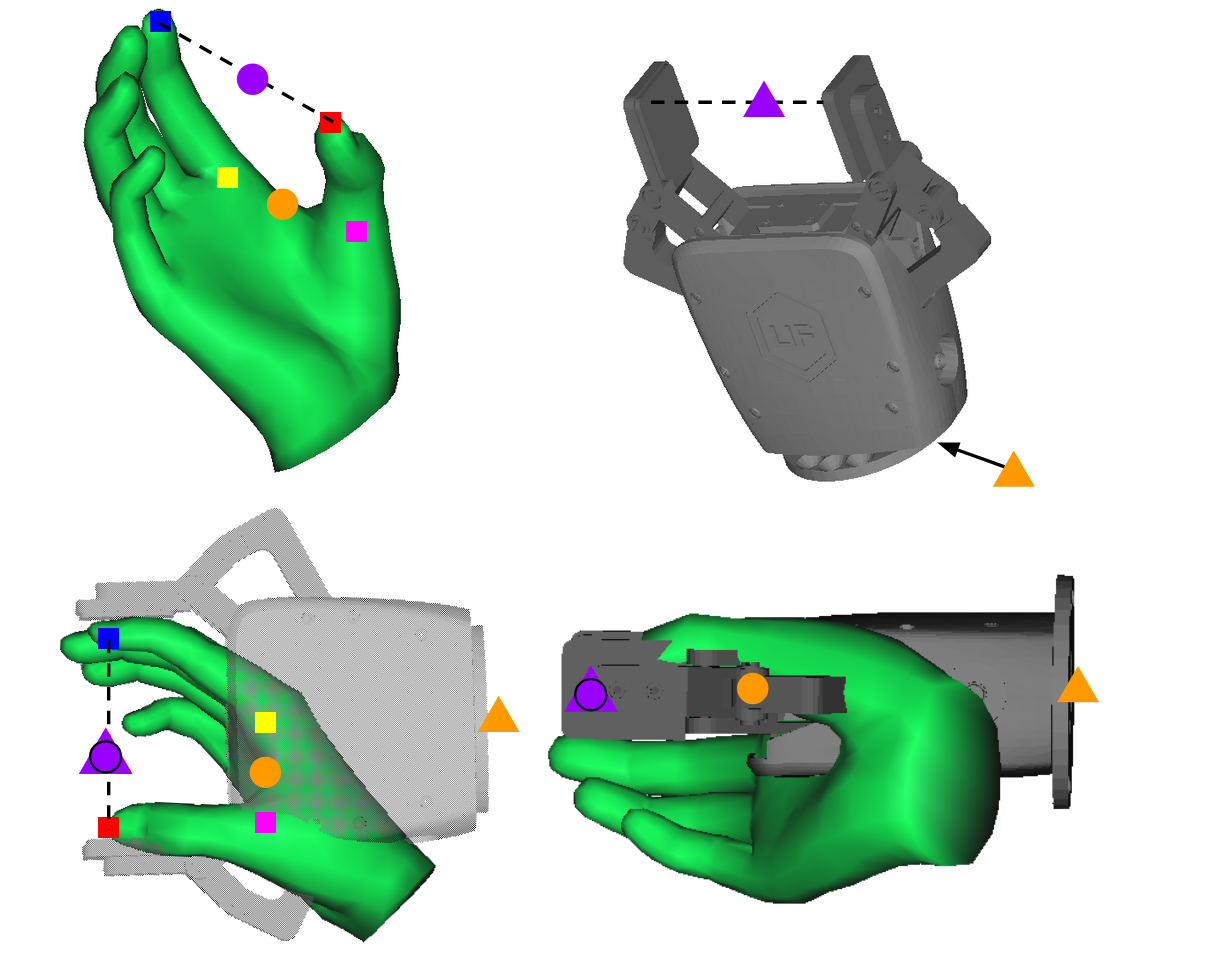
Figure 9: Hand-to-end-effector TCP/keypoint mapping and alignment in front and side views for robust retargeting accuracy.


Figure 10: Diversity of training and out-of-distribution test scenes for the Can on Plate generalization experiments.
Conclusion
WARPED establishes a robust, scalable, and hardware-minimal framework for robot policy learning from human egocentric video. It matches or exceeds teleoperated data policy performance in most scenarios, with an order-of-magnitude reduction in data collection overhead and no dependency on complex sensor setups. Future research will focus on relaxing assumptions regarding object rigidity and static scenes, extending to longer-horizon and articulated/deformable manipulation, and further improving sim-to-real fidelity and generalization.

