Communication-Efficient Gluon in Federated Learning
Published 12 Apr 2026 in cs.LG | (2604.10689v1)
Abstract: Recent developments have shown that Muon-type optimizers based on linear minimization oracles (LMOs) over non-Euclidean norm balls have the potential to get superior practical performance than Adam-type methods in the training of LLMs. Since large-scale neural networks are trained across massive machines, communication cost becomes the bottleneck. To address this bottleneck, we investigate Gluon, which is an extension of Muon under the more general layer-wise $(L0, L1)$-smooth setting, with both unbiased and contraction compressors. In order to reduce the compression error, we employ the variance reduced technique in SARAH in our compressed methods. The convergence rates and improved communication cost are achieved under certain conditions. As a byproduct, a new variance reduced algorithm with faster convergence rate than Gluon is obtained. We also incorporate momentum variance reduction (MVR) to these compressed algorithms and comparable communication cost is derived under weaker conditions when $L_i1 \neq 0$. Finally, several numerical experiments are conducted to verify the superior performance of our compressed algorithms in terms of communication cost.
The paper introduces a compressed Gluon algorithm that integrates unbiased and contraction compressors with error feedback to enhance communication efficiency.
It leverages SARAH-based momentum variance reduction and layer-wise non-Euclidean smoothness to achieve up to a 65% reduction in communication costs.
The study provides both theoretical bounds and empirical evidence on logistic regression and CIFAR10, demonstrating practical improvements in distributed learning.
Communication-Efficient Gluon for Federated Learning
Introduction
The paper "Communication-Efficient Gluon in Federated Learning" (2604.10689) addresses the communication bottleneck in distributed and federated training of large neural networks. The study extends the Muon and Gluon optimizer frameworks and systematically integrates both unbiased and contraction compressors, as well as momentum variance reduction (MVR) and error feedback (EF) mechanisms, under the generalized layer-wise (L0,L1)-smooth setting. The main thrust is the theoretical and practical analysis of compressed optimization schemes for federated learning, yielding improved bounds for communication cost versus solution accuracy.
Theoretical Framework and Algorithms
The core of the work is the extension of layer-wise Muon-based optimizers (notably Gluon) to efficient distributed regimes under compression. The authors generalize the smoothness assumptions to the (L0,L1)-smooth regime, encompassing practical conditions observed in neural networks, leveraging the LMO framework to perform updates over non-Euclidean norm balls for better adaptation to neural network geometry.
Two classes of compressors are formally developed:
Unbiased Compressors: Defined by the preservation of mean and bounded second moment, covering random sparsification and dithering.
Contraction Compressors: Defined by a contraction property with respect to the Euclidean norm, covering Top-K and related biased methods, with theoretical divergence averted only via error feedback.
Key innovations include:
Compressed Gluon: A SARAH/PAGE-based variance-reduced stochastic estimator and communication scheme, supporting both unbiased and contraction compressors, shown to have improved communication complexity even under limited precision constraints.
Error Feedback Mechanism: Integrated into Gluon to allow contraction compressors without loss of convergence, tracking and compensating compression-induced error.
Momentum Variance Reduction (MVR): Incorporated into compressed optimization, yielding linear speedup in convergence for increasing node counts or batch sizes.
The paper also retrieves several known algorithms (e.g., VR-MARINA, Local Gluon) as special cases and connects to related work on error-compensated SGD.
Communication Complexity and Convergence Analysis
The technical analysis rigorously establishes upper bounds for both oracle and communication complexities across algorithmic variants, leveraging nuanced parameter choices. The main results can be summarized as follows:
Compressed Gluon and Compressed Gluon+MVR (unbiased compressors):
Achieve communication complexity O(ϵ2nd+c2ϵ4n1) to reach ϵ-stationarity.
Linear speedup (in n) is obtained up to the regime n≤O(ϵ−2).
Compressed Gluon with Error Feedback (contraction compressors):
Achieves communication complexity O(ϵ2nd+c2ϵ41) given proper error feedback.
Variance-Reduced Special Cases:
When layer-wise smooth constants Li0≈0, as often observed empirically, the communication complexity can be further reduced.
The paper also proves the existence of new variance-reduced distributed algorithms with convergence rate O(n−1/3K−1/3), which had not been previously established for this regime.
Empirical Validation
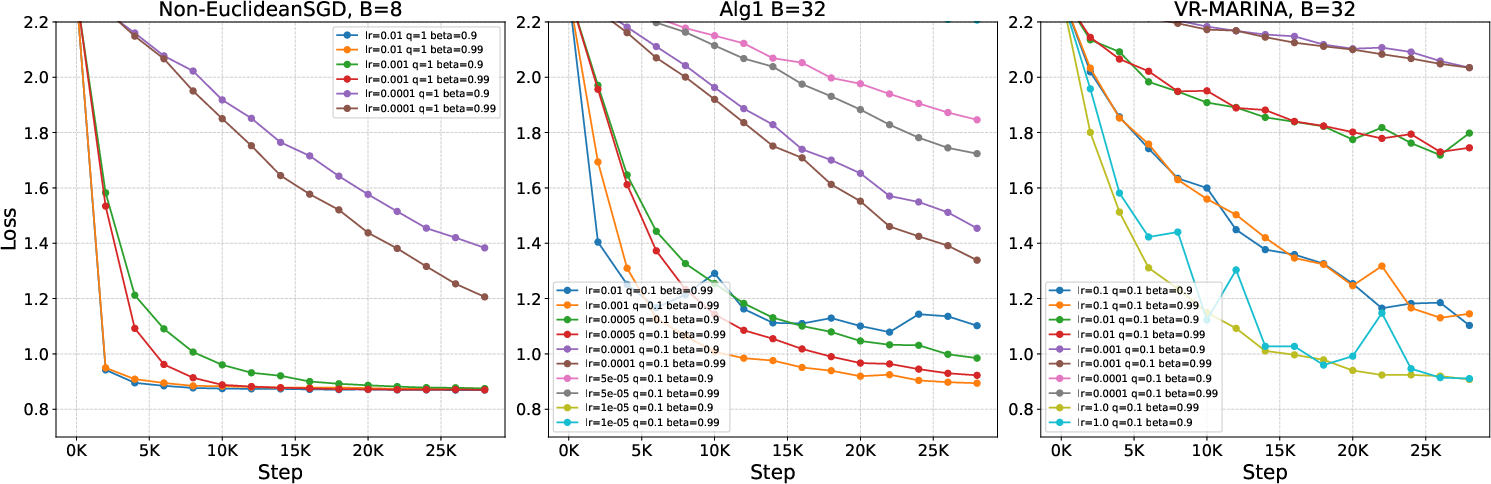
Extensive experiments are conducted on logistic regression (a5a dataset) and convolutional neural networks (CIFAR10) with both unbiased and contraction-based compressor schemes. Key figures support the communication-efficiency claims:
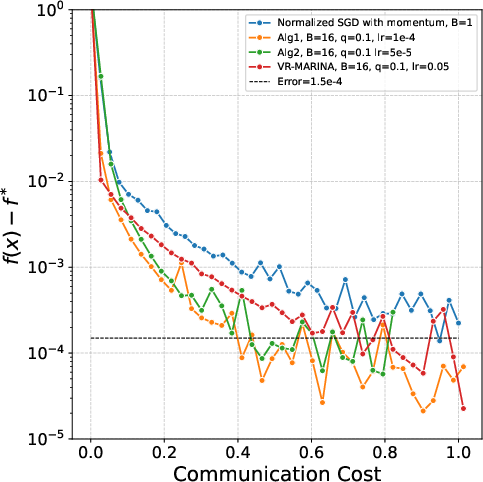
Figure 1: Communication efficiency analysis—f(x)−f∗ versus communication cost for compressed Gluon variants using logistic regression on a5a. All compressed methods utilize (L0,L1)0.
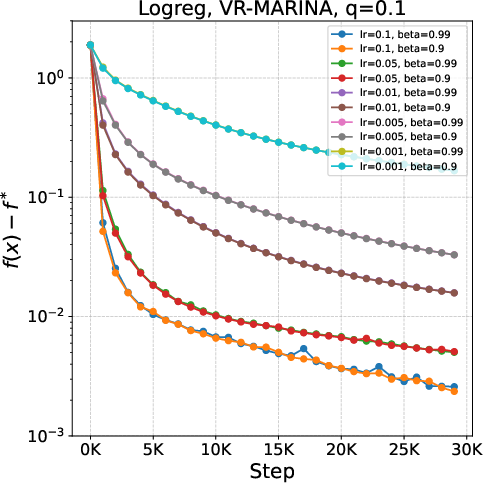
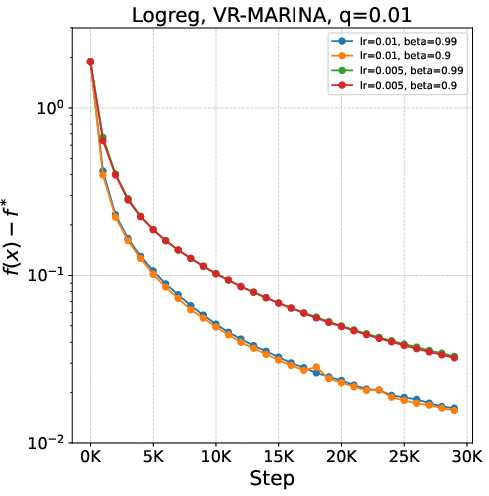
Figure 2: Stability and convergence for VR-MARINA with (L0,L1)1 and Rand(L0,L1)2 compression.
The communication-efficient compressed Gluon achieves approximately (L0,L1)3 reduction in communication cost versus baselines in logistic regression.
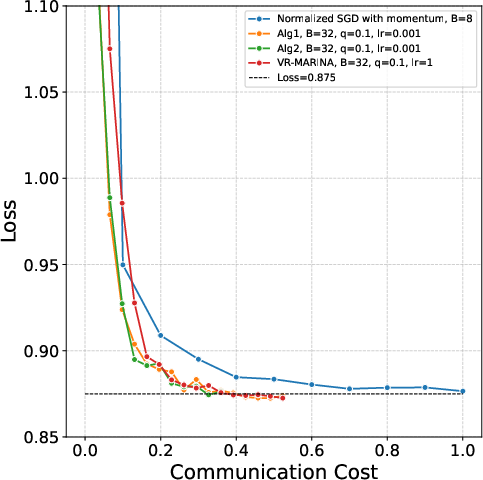
Figure 3: Loss as a function of training step for CIFAR10, with (L0,L1)4 and various momentum/lr choices for Non-Euclidean SGD baseline.
On CIFAR10, compressed Gluon yields approximately (L0,L1)5 communication cost reduction, validating the theoretical findings on practical non-convex models.
Algorithmic and Practical Implications
The derived algorithms have immediate impact for communication-bounded federated learning, including but not limited to large-scale LLM training across distributed heterogeneous workers, on both centralized and device-edge regimes. The layer-wise, norm-adaptive nature of Gluon harmonizes well with the empirical landscape of neural network optimization, particularly as batch sizes and node counts increase.
The theoretical developments, in particular the decoupled error compensation architecture and SARAH-based variance reduction, are of independent interest for the construction of future communication- and memory-efficient algorithms. The layer-wise generalization facilitates deployment in Transformer-style and multi-modal architectures where block-wise non-Euclidean geometry is present.
Future Directions
Potential directions for future work include:
Extension to fully asynchronous federated settings, accounting for stragglers and unreliable communication.
Framework generalization to heterogeneous devices with per-layer and per-worker compression and local adaptation.
Tightening lower bounds and seeking tighter empirical-complexity correspondence for practical large-batch LLM training.
Incorporation of adaptive error feedback and online compressor selection schemes leveraging gradient statistics and communication states.
Conclusion
This study delivers a comprehensive mathematical and empirical treatment of compressed, communication-efficient federated neural optimization via Gluon, raising both theoretical and practical standards in communication-efficient large-scale distributed learning. The explicit handling of compression error, variance reduction, layer-wise adaptation, and convergence guarantees positions these algorithms for widespread adoption in modern AI infrastructure.