- The paper presents a multi-modal, semantically grounded pretraining framework that aligns diverse remote sensing modalities using agentic captioning.
- The methodology leverages multi-pretext masked autoencoding, JEPA-based predictive learning, and image-text contrastive loss for robust feature learning.
- Empirical evaluations on datasets like BigEarthNet20k and So2Sat20k demonstrate notable improvements in performance metrics, ensuring cross-modal robustness.
Authoritative Summary of "GeoMeld: Toward Semantically Grounded Foundation Models for Remote Sensing"
Introduction and Motivation
The paper introduces GeoMeld, a multi-modal, semantically grounded dataset and pretraining framework tailored for remote sensing (RS) foundation models. Traditional RS datasets and pretraining approaches exhibit modality fragmentation and insufficient semantic grounding, largely relying on vision-only or annotated label structures. By contrast, GeoMeld aligns heterogeneous modalities—optical (Sentinel-2), SAR (Sentinel-1), DEM, canopy height, land-cover maps, and location metadata—at scale, pairing each spatial anchor with a verified natural-language caption derived through a structured agent-based pipeline. The resulting dataset contains approximately 2.5 million samples, offering broad biome and geographic diversity (Figure 1).
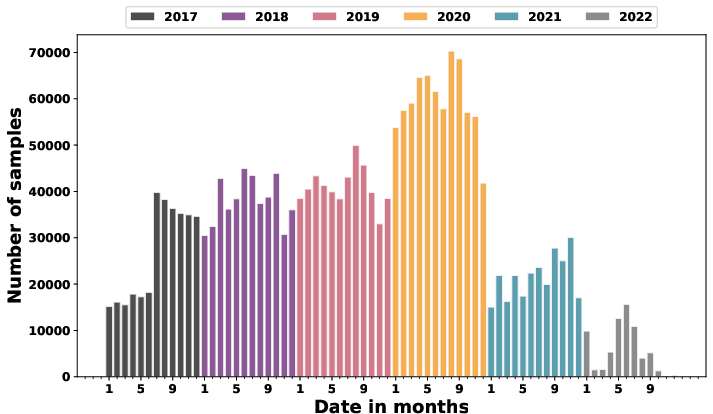
Figure 1: Temporal distribution of GeoMeld samples, showing the number of samples per month and overall seasonal coverage.
GeoMeld-FM, the accompanying foundation model, is pretrained using multi-pretext masked autoencoding, JEPA-based predictive representation learning, and caption–vision contrastive alignment. This enables the joint representation space to capture cross-modal physical consistency and semantic grounding, facilitating downstream transfer and robustness.
Dataset Construction and Modality Alignment
GeoMeld's coordinate pool is instantiated from three strategies: biome-stratified sampling for ecological diversity; incorporation of spatial anchors from existing RS datasets (e.g., MMEarth, SkyScript) without overlap; and targeted sampling of underrepresented regions (Africa, South America, Asia) to address geographic bias. Each spatial anchor defines a standardized 1280×1280 m field of view, harmonized to 128×128 arrays at 10m GSD across modalities. Temporal alignment is achieved via anchor-based retrieval windows, ensuring sensor coherence and seasonal coverage.

Figure 2: A sample from GeoMeld showing spatially aligned multi-modal inputs derived through a unified alignment protocol.
Agentic Caption Generation Framework
Captions in GeoMeld are synthesized through a sequence of agentic operations:
- Orchestrator: Aggregates modality-specific signals and metadata, constructing structured prompts.
- Captioner: Generates multiple conditioned candidate captions, incorporating visual and metadata signals.
- Evaluator: Ranks captions based on vision–text alignment, prioritizing cross-modal consistency.
- Verification Agent: Enforces semantic consistency by cross-checking textual claims with geospatial attributes (land-cover, hydrological, terrain), correcting inconsistencies.
This multi-agent approach surpasses conventional templated or annotation-based captions, integrating relational, cross-modality information and reducing hallucination.
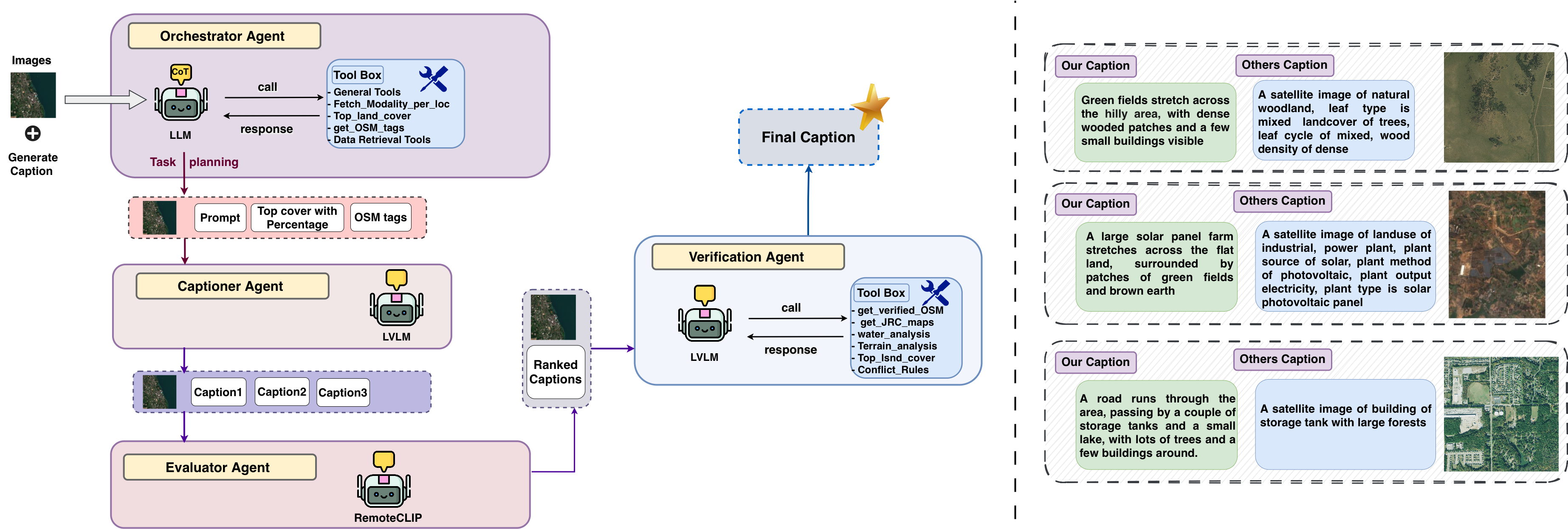
Figure 3: Agentic framework for generating semantically grounded captions and caption quality comparison.
Foundation Model Architecture: GeoMeld-FM
GeoMeld-FM utilizes a ConvNeXtV2 backbone, applying patch-based masking to Sentinel-2 imagery, and lightweight decoders for reconstruction or prediction across aligned modalities. Multi-pretext masked autoencoding (MP-MAE) forms the first major component, targeting pixel-wise cross-modality structure.
A JEPA branch introduces high-level latent-space predictive learning, creating context and target views of Sentinel-2 tiles under distinct masks, with a predictor mapping context representation to target latents from an EMA teacher.
Caption embeddings, produced by a Transformer, are aligned with pooled vision representations using a symmetric InfoNCE contrastive objective, directly embedding visual and textual signals in a joint space. The model is jointly trained with MP-MAE, JEPA, and ITC (image–text contrastive) losses.
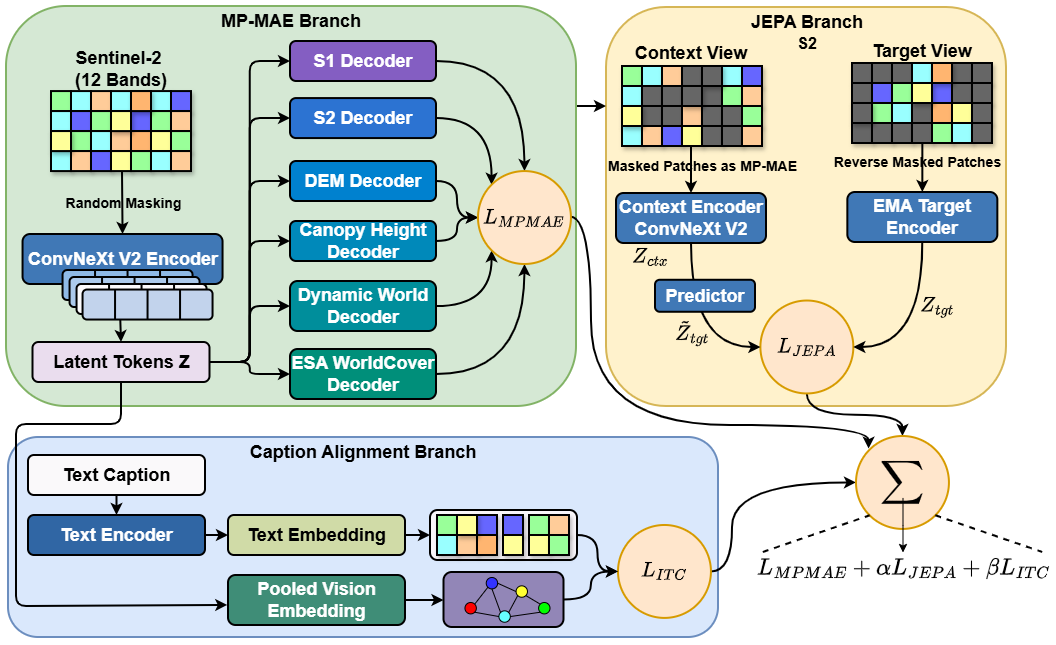
Figure 4: GeoMeld-FM pretraining architecture integrating multi-pretext masked autoencoding, JEPA prediction, and vision–language contrastive alignment.
Experimental Evaluation
GeoMeld-FM is evaluated on the GeoBench suite, including BigEarthNet20k (land-cover multi-label), So2Sat20k (urban land-use), Cashew1k (semantic segmentation), and SAcrop3k (crop-type segmentation), using both linear probing (LP) and full fine-tuning (FT).
Significant gains are observed versus optical-only and prior multi-modal pretraining baselines, particularly in linear probing: GeoMeld-FM achieves $49.6$ (F1) on BigEarthNet20k and $50.2$ (accuracy) on So2Sat20k, surpassing MMEarth (MP-MAE) and S2-only models. Dense prediction tasks (Cashew1k, SAcrop3k) show improved IoU scores, demonstrating cross-sensor robustness.
Ablation studies reveal complementary contributions of MP-MAE, JEPA, and ITC. Cross-modality reconstruction yields major improvements; JEPA further enhances semantic structure; ITC enables meaningful bidirectional retrieval (R@5 up to $39.6$ for text-to-image), validating language grounding. The full model achieves the strongest downstream performance across modalities and tasks.
Practical and Theoretical Implications
GeoMeld establishes a new reference for scalable, semantically grounded RS foundation modeling. By directly incorporating richly aligned modalities and validated language supervision, the dataset supports the construction of vision-only, vision–language, and multi-agent models suited for geospatial understanding. The pretraining framework demonstrates superior transferability, spatial robustness, and improved semantic retrieval, essential for applications in Earth monitoring, biophysical modeling, and environmental AI. The agentic caption protocol reduces hallucination and ensures interpretability.
The architecture points toward future developments in RS-AI, including multi-temporal and multi-resolution modeling, fine-grained spatial grounding, interactive vision–language interfaces, and instruction-tuned foundation models optimized for global environmental monitoring.
Conclusion
GeoMeld, together with GeoMeld-FM, provides a large-scale, modality-aligned, semantically verified dataset and pretraining framework for remote sensing foundation models. Empirical results confirm that joint cross-modal reconstruction, predictive latent learning, and caption grounding substantially improve downstream performance and retrieval. GeoMeld offers a robust foundation for subsequent research in multi-modal, vision–language, and agentic AI for geospatial domains (2604.10591).

