- The paper introduces Rein3D, a framework that couples 3D Gaussian Splatting with panoramic video diffusion models to produce globally consistent 3D indoor scenes.
- It employs a radial exploration strategy and spherical-conditioning techniques to enhance temporal coherence and significantly improve WS-PSNR/SSIM metrics.
- The method leverages the curated PanoV2V-15K dataset to robustly train models for both text- and image-conditioned 3D scene synthesis under open-world conditions.
Rein3D: Reinforced 3D Indoor Scene Generation with Panoramic Video Diffusion Models
Introduction
Rein3D introduces a novel methodology for synthesizing globally consistent and photorealistic 3D indoor scenes from sparse modalities such as single panoramas or text prompts, targeting the core limitations in current embodied AI and VR pipelines. The framework explicitly couples 3D Gaussian Splatting (3DGS) with panoramic video diffusion models (VDM) conditioned on temporally coherent priors, and is supported by the construction of the PanoV2V-15K dataset comprising paired clean/degraded panoramic videos. This work positions itself as an explicit solution to the geometric and consistency constraints inherent in image-based, local, and multi-view synthesis pipelines under large-scale, open-world conditions.

Figure 1: Overview of the Rein3D framework, demonstrating the initialization, radial video rendering, video diffusion restoration, and iterative 3DGS refinement.
Methodology
Coarse Initialization and Radial Exploration
The pipeline commences with a coarse 3DGS scene estimated via the unprojection of a text-guided or user-specified panorama and its depth map, leveraging pretrained models such as DiT360 and DA2 for robust panoramic and depth inference. Each panoramic pixel is mapped into 3D space, initializing each Gaussian as a fully opaque, isotropic sphere with spatial and color priors fixed by the panoramic RGB-D input.
Expanding beyond localized, incremental camera translation, Rein3D implements a radial search strategy for exploration. From the scene center, panoramic RGB-Alpha videos are rendered outward on multiple uniformly distributed trajectories, designed to maximize the recovery of occluded or unobserved geometry.
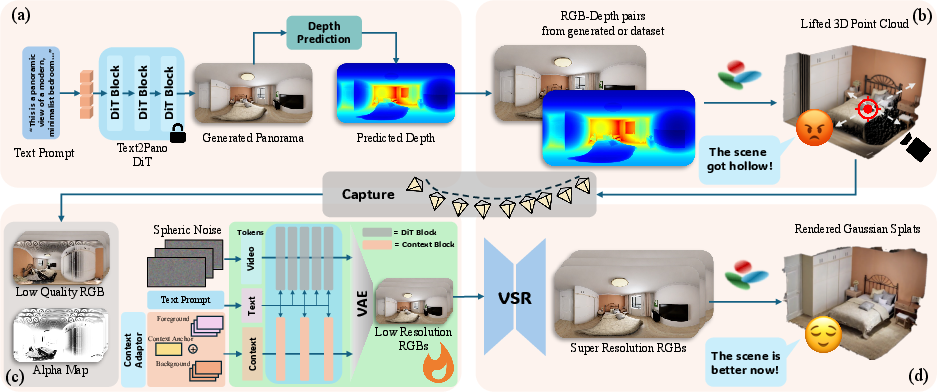
Figure 2: Schematic of the Rein3D pipeline—showing initial panorama and depth prediction, 3DGS initialization, trajectory rendering, video diffusion, VSR enhancement, and iterative update.
Panoramic Video Diffusion and Spherical Conditioning
The impairment of the rendered panoramic sequences—resulting from missing geometry and incomplete textures—is addressed via a V2V diffusion model, adapted from the Wan2.1-1.3B backbone. Input videos are decomposed into background and foreground using opacity, encoded separately, and concatenated with an explicit Context Anchor, the initial panoramic view, along the temporal axis. This anchor is crucial for maintaining long-term temporal coherence and mitigating geometric drift, as ablation substantiates a marked FVD and WS-PSNR degradation without it.
A key component is the spherical adaptation: latitude-aware noise sampling is applied to counteract equirectangular distortion, and a latitude-decay loss reweights pixel contributions based on geodesic area, optimizing reconstruction fidelity on the 3D sphere. This approach significantly boosts spherical metrics (WS-PSNR/SSIM) versus standard latents.
High-Fidelity Video Fusion and Scene Refinement
Post-diffusion, video clips undergo FlashVSR-based upscaling, restoring high-frequency detail to panoramic frames. These refined sequences act as pseudo-ground truth for subsequent 3DGS parameter optimization, incorporating perspective projections for rasterization and anti-aliasing to suppress structural artifacts. The iterative restore-and-refine loop enables robust recovery of unobserved regions, progressive reduction of geometric artifacts, and maintenance of view-consistent scene representations under wide camera trajectories.
PanoV2V-15K Dataset
To surmount data scarcity for panoramic V2V restoration, PanoV2V-15K is curated: 15,050 indoor scenes with paired degraded/clean panoramic video sequences sampled along linear trajectories. This dataset enables robust training for panoramic VDM, filling the critical gap between narrow-FoV, fragmented datasets, and the requirements for global and immersive restoration.

Figure 3: Illustration of dataset construction covering scene, trajectory sampling, ground truth panoramic videos, and explicit 3D prior renderings.
Experimental Results
Against ProPainter and VACE (with and without panoramic fine-tuning), Rein3D achieves superior WS-PSNR/SSIM and FVD scores, demonstrating effective handling of polar distortion, improved temporal consistency, and fidelity in panoramic restoration. Ablations confirm the necessity of the Context Anchor and latitude-decay loss for optimal spherical and temporal metrics; λ=0.1 yields the best trade-off.
Text/Panorama-to-3D Scene Generation
In text-to-3D synthesis benchmarks, Rein3D surpasses WorldGen, EmbodiedGen, and DreamScene360, delivering continuous, coherent, and complete 3D scenes even under extensive viewpoint shifts. In image-conditioned 3D reconstruction on Structured3D, both visual alignment (Q-Align, CLIP) and perceptual quality (NIQE, BRISQUE) metrics validate consistent outperformance across origin and far-apart viewpoints, corroborating the efficacy of the radial exploration and panoramic restoration paradigm.

Figure 4: Qualitative comparison for novel view synthesis under text prompts; Rein3D yields coherent and structurally plausible geometry where alternatives falter.

Figure 5: Perspective view reconstruction from panoramic input—Rein3D suppresses floating artifacts and geometric drift highlighted in baselines.

Figure 6: Panoramic rendering quality under wide camera motion; Rein3D preserves global and local consistency even at far-field viewpoints.
Implications and Future Directions
Rein3D advances 3D content creation for embodied AI, VR, and AR, enabling the direct synthesis of immersive, traversable worlds from sparse cues. It resolves the geometric ambiguity and inconsistency that impede naïve image or multi-view based pipelines when coverage, global topology, and photorealism are simultaneous constraints. The integration of panoramic VDM with explicit geometry sets a scalable precedent for generative scene modeling. Practically, the release of PanoV2V-15K and the pipeline's composability facilitate further research in semantic editing, long-range exploration, and dynamic scene augmentation.
Conclusion
Rein3D operationalizes a cyclic restore-and-refine paradigm, robustly synthesizing photorealistic, 360° consistent 3D indoor scenes from extremely sparse input. The method’s explicit coupling of 3D Gaussian Splatting and panoramic video diffusion—enhanced by data-driven spherical adaptations—enables significant improvements over prior works in accuracy, realism, and stability under long-range camera motion. The proposed framework and dataset lay essential groundwork for generative 3D content creation with strong implications for embodied reasoning and virtual simulation (2604.10578).

