- The paper introduces a context-aware KG visualization framework integrating LLM-driven user preference extraction, ontology-guided spatial layout, and iterative contextual refinement.
- The methodology employs robust clustering with DBSCAN and K-means as well as modified force-directed layouts, yielding high extraction fidelity and superior subcluster quality confirmed by user studies.
- The approach scales efficiently for large graphs and bridges automated insight generation with human-guided exploration, enhancing interpretability and semantic clarity.
Context-KG: A Context-Aware Knowledge Graph Visualization Framework
Introduction
Context-KG addresses persistent deficiencies in conventional knowledge graph (KG) visualization, which typically disregards user context and the semantic, ontological structure inherent to KGs. Prevailing visualization tools rely on force-directed, topology-centric layouts that fail to incorporate user preferences, semantic context, or explanations for node placement, thereby impeding user understanding and effective exploration. Context-KG introduces a unified framework integrating LLM-driven user preference extraction, ontology-guided spatial arrangement, and LLM-based automated insight generation. The system facilitates context-driven, semantically interpretable KG visualizations tailored to each query, supporting an iterative, user-adaptive exploration paradigm.
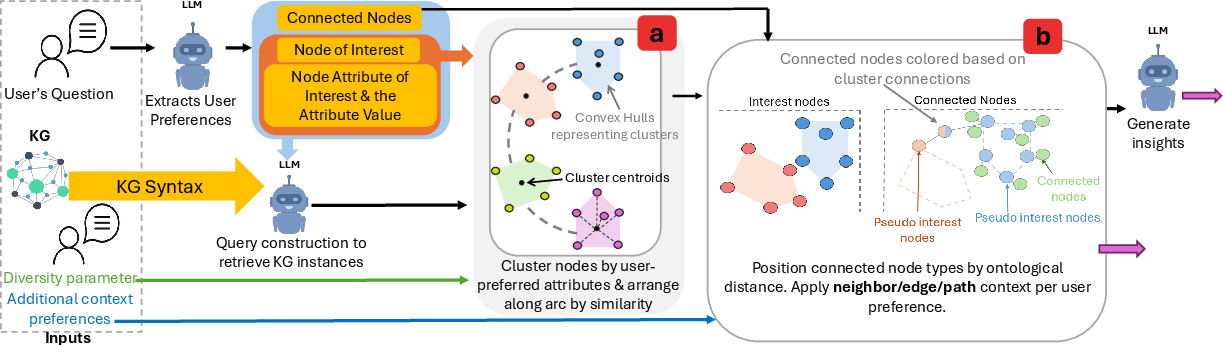
Figure 2: The Context-KG overview depicting the LLM-driven pipeline from user question and preference extraction to ontology-guided clustering and contextually scoped layout.
Methodological Advances
LLM-Driven User Preference and Context Extraction
Context-KG leverages state-of-the-art LLMs to interpret natural language questions and context descriptions. The pipeline extracts four core intent elements: primary node type of interest, key attribute, attribute value, and connected node types. This approach transcends previous fixed-label or behavioral-log-based preference extraction, supporting both broad and multi-stage, open-ended information-seeking intents. Subsequent context descriptions are iteratively mapped to visualization modifications using three refined context primitives: Neighbor, Edge, and Path Context. These facilitate dynamic refinement of the displayed subgraph in accordance with user input.
Ontology-Guided Visualization and Clustering
The visualization pipeline establishes a global spatial layout based on the shortest-path distances in the KG's ontology, cleanly partitioning node types into interpretable, type-aware regions. Within these, nodes of interest are clustered on user-preferred attributes using DBSCAN (for numeric attributes) or K-means (for textual ones), and arranged along an arc to minimize occlusion and maximize region interpretability. The diversity parameter governs instance sampling, facilitating scalable visualization and diverse insights. Connected nodes are spatially organized via modified force-directed layouts anchored on the clusters, with multi-cluster nodes visually encoded as pie charts, immediately exposing cross-cluster associations. This design fundamentally improves explainability and interpretability of node positioning relative to baseline methods.
Iterative Contextual Refinement
Through additional user-provided context, the LLM classifies visual adjustments as neighbor-, edge-, or path-centric and applies semantically meaningful modifications accordingly. Figure 3 provides examples of iterative context refinement via edge highlighting, path-finding, and neighbor emphasis, respectively.
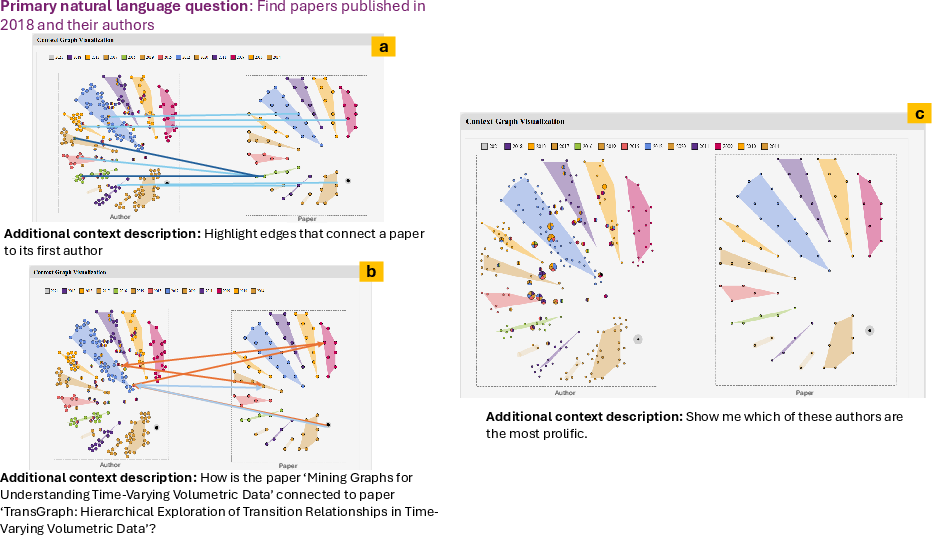
Figure 1: Iterative context refinement in Context-KG for edge, path, and neighbor contexts in response to user-provided context statements.
Automated Insight Generation
By encoding topological and cluster-centric features of the context KG, the system prompts the LLM to synthesize comparative, structured, and contextually relevant insights. Rather than generate speculative summaries, insights reflect objective graph properties such as the existence of hubs, bridging nodes, cluster statistics, and attribute distributions, all grounded in the system-generated structural encoding.
Empirical Evaluation
Experiments conducted with GPT-4 Turbo on a manually labeled dataset (135 queries) exhibit high extraction fidelity: F1 scores exceed 98% for node and connection types, with attributes of interest reaching up to 94%. These figures reflect robust semantic alignment and minimal ambiguity, outperforming rule-based and heuristic extraction schemes.
Subcluster and Layout Quality
Cluster formations within connected node regions were quantitatively assessed using K-Means and agglomerative clustering, with Adjusted Rand Index and NMI both at 1.0 and Silhouette Scores ≥0.72 for relevant tasks, confirming preservation of intuitive substructure.
Scalability
Profiling over increasing KG sizes (up to 1,000 nodes) demonstrates sublinear increases in computation and memory footprint, with time and LLM token usage both growing moderately, validating the approach's scalability for practical KG sizes.
User Study: Interpretability and Usability
A systematic user study (N=15, 12 tasks) benchmarked Context-KG against Neo4j and KinGVisher. Context-KG received the highest Likert-scale and task completion ratings across all categories—the superiority was particularly pronounced in tasks requiring cluster/ontological reasoning, placement interpretation, and exploration contextualization.
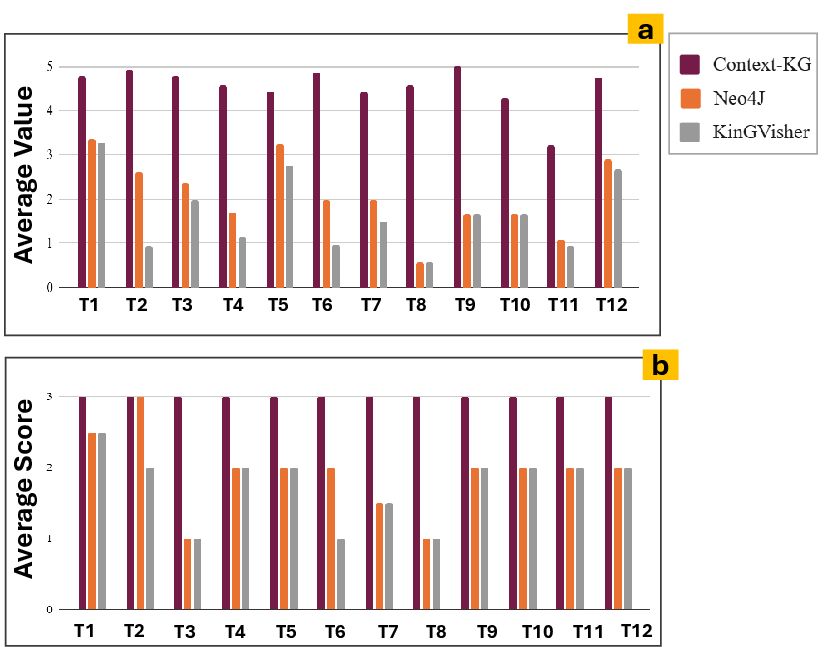
Figure 5: User study evaluation results demonstrating both subjective ratings and objective task completion for Context-KG and baseline systems.
Qualitative feedback highlights clarity in region separation, semantic proximity cues, and effectiveness of pie-encoding for multi-cluster nodes. Only minor limitations surfaced in densely connected contexts or where LLM-generated insights did not capture all desired statistics.
LLM-Generated Insight Reliability
A separate evaluation over 50 queries exhibited no hallucination or factual error, attributed to the system’s constraint of LLM generations by explicit graph encodings.
Practical and Theoretical Implications
Context-KG establishes a technical blueprint for KG exploration systems that:
- Align graph structure and visualization with user intent: Graph regions and clusters directly mirror semantic and ontological context, reducing cognitive mismatches and supporting faster, more accurate mental model construction.
- Support iterative, user-driven exploration: Dynamic refinement based on both explicit and implicit context signals widens the range of supported information-seeking strategies, with potential applications in scientific discovery, literature analysis, and multi-domain KGs.
- Bridge robust automation with human insight: The combination of LLM-guided extraction and algorithmic layout creates a closed loop supporting both naive and expert exploratory behavior.
- Lift the cognitive barrier for non-expert users: By situating query answers in larger semantic context and providing actionable LLM-driven summaries, the tool democratizes access to complex, highly relational datasets.
The work posits further research directions: decoupling the insight-generation backend from a single LLM, extending context integration to richer relational structures (beyond primary node types), and deepening the use of relational attributes in both cluster computation and visual encoding.
Conclusion
Context-KG introduces a comprehensive, ontology- and context-aware KG visualization paradigm that systematically integrates LLM-driven user preference extraction, semantically grounded spatial layout, and automated, interpretable insight generation. Empirical results demonstrate significant advantages over topology-based baselines in interpretability, task completion, and user satisfaction. As KGs become increasingly central to large-scale data reasoning, systems in the mold of Context-KG will serve as foundational infrastructure for context-sensitive, adaptive, and explainable visual analytics.

