- The paper demonstrates that careful protocol tuning (geometry, tiling, normalization) can induce up to 33× error variation, making protocol design a key factor in performance.
- The study evaluates 24 pretrained matchers in a zero-shot setting across three datasets, highlighting how preprocessing choices and RANSAC filtering affect registration accuracy.
- The findings reveal that frozen DINOv2-based architectures exhibit emergent cross-modal invariance, establishing them as strong candidates for operational satellite registration.
Evaluation of Pretrained Image Matchers for SAR-Optical Satellite Registration
The paper investigates the effectiveness of current off-the-shelf, pretrained image matchers for the challenging problem of cross-modal satellite registration between optical and Synthetic Aperture Radar (SAR) imagery. This task is critical in disaster response where optical imagery is often degraded by atmospheric effects (e.g., cloud cover), necessitating registration of SAR images to pre-existing optical basemaps for timely georeferenced analysis. The difficulty is exacerbated by significant modality-induced appearance gaps: SAR and optical images capture fundamentally different radiometric and geometric properties, leading to distinctive sensor-driven artifacts such as speckle noise, geometric layover, and contrast inversion.
Methodology
The study evaluates twenty-four pretrained matcher models encompassing detector-based, detector-free dense, and 3D-reconstruction-derived paradigms. No fine-tuning or domain adaptation is performed, creating a strict zero-shot transfer regime. Evaluation focuses on three datasets:
- SpaceNet9: Manual tie-point supervision over large, orthorectified satellite scenes for labeled train/test splits.
- SRIF: 600 affine-labeled cross-modality image pairs.
- SARptical: Retrieval-style patch matching with 40 queries and 525 candidate pairs per query.
The protocol involves optional normalization (identity, percentile, z-score, CLAHE), tiling with overlap, RANSAC-based robust geometric filtering (affine or homography models), and displacement computation for metric reporting. Metrics include mean tie-point error, Success@τ (the proportion of tie points below τ pixel error), and failure rates.
Key Findings
A dominant theme is the high protocol sensitivity: intra-matcher accuracy variance due to protocol shifts often matches or exceeds differences induced by swapping models, establishing protocol design as a first-order determinant of operational performance.
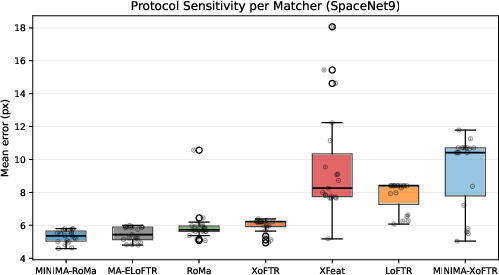
Figure 1: Protocol sensitivity per matcher, showing intra-matcher variance from protocol choices often equals or exceeds inter-matcher differences.
Top Model Performance: Despite being trained exclusively on ground-level, single-modality imagery, RoMa achieves state-of-the-art mean error (3.0 px) on SpaceNet9, matching XoFTR (trained for visible–thermal cross-modality), and closely followed by cross-modal variants like MINIMA-RoMa and MatchAnything-ELoFTR (3.4 px). Notably:
- XoFTR and RoMa share the lowest error (3.0 px, 78.9–78.4% Success@5, <0.01 failure).
- MA-ELoFTR and MINIMA-based variants maintain competitive performance within 1 px of the leaders.
Protocol Dominance: Ablations reveal that protocol shifts—specifically, model geometry (affine vs. homography), tile size/overlap, normalization, and inlier gating—can induce up to 33× variation in mean error for a given matcher.
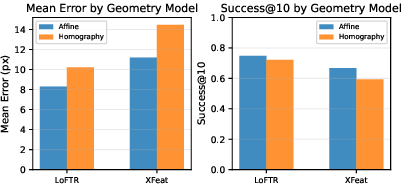
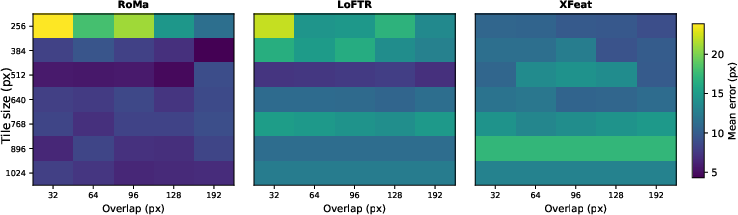
Figure 2: Comparing affine versus homography geometry models; affine is consistently superior due to the true orthorectified transform being approximately affine.
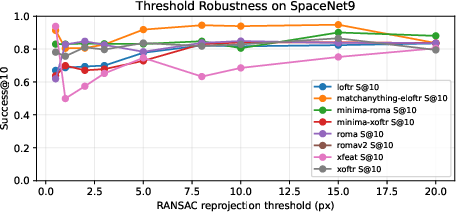
Figure 3: RANSAC threshold robustness curves showing that matcher sensitivity to the reprojection threshold often dominates overall registration reliability.
Qualitative Insights
The qualitative gallery illustrates that top matchers yield dense, geometrically consistent inlier correspondences (green lines), whereas less robust or mismatched architectures yield more outliers (orange lines), underscoring the interaction of backbone architecture and protocol tuning.









Figure 4: Qualitative correspondence gallery for SpaceNet9, highlighting matcher-dependent variation in inlier/outlier distribution.
Cross-Dataset and Generalization Analysis
The empirical ranking on SpaceNet9 is consistent on SRIF and SARptical, demonstrating robustness in zero-shot cross-dataset transfer. MINIMA-RoMa shows the best trade-off between accuracy and zero-failure on SRIF (mean corner error 47.0 px, 0% failure), aligning with its top-tier ranking on SpaceNet9 and competitive AUROC on SARptical.

Figure 5: Normalization × matcher heatmap on SRIF; normalization affects matchability differently across architectures, with MINIMA-RoMa + Z-Score normalization yielding lowest error.
Sparse detectors with graph matchers (e.g., XFeat, SuperPoint-LightGlue) trail dense correspondence models; 3D-reconstruction models (MASt3R, DUSt3R) are notably brittle, as their architectural priors (depth, perspective) mismatch the weakly perspective, domain-specific geometry of overhead imagery.
Implications
Practical
- Deployment protocols (geometry model, tiling, normalization, inlier gating) must be tailored to satellite data; defaulting to homography or untuned thresholds degrades performance.
- Strong zero-shot performance with RoMa and its variants, pointing to the potency of foundation model features (e.g., DINOv2/3) in providing emergent partial modality invariance—even without explicit cross-modal supervision.
- For immediate deployment, the best baseline is MINIMA-RoMa or RoMa under affine geometry, with 7682 px tiles, >128 px overlap, percentile or CLAHE normalization, and RANSAC threshold ≤ 10 px.
Theoretical
- The success of frozen DINOv2-based architectures (despite a lack of explicit cross-modal data) suggests dense backbone feature pretraining learns invariances that are at least partially cross-modal. This challenges the notion that cross-modal supervision is always required, although the exact mechanism (architecture or pretraining corpus diversity) is unresolved.
- Architecture–protocol interactions (e.g., correspondence density, RANSAC robustness) remain poorly understood for remote sensing and cross-modality in general.
Limitations
- Only three labeled scenes on SpaceNet9 limits statistical power; results are best interpreted as operational diagnostics rather than population estimates.
- Evaluation is restricted to pretrained models; fine-tuning or recent models integrating satellite/SAR losses (e.g., MapGlue) are not considered.
- The findings pertain to orthorectified satellite data; extension to non-orthorectified (e.g., raw slant-range SAR) regimes is untested.
Speculation on Future Directions
- Protocol optimization (e.g., adaptive thresholding, geometry selection) and hybrid pipelines (multi-stage candidate selection + geometric verification) could surpass further gains from changing matchers.
- Satellite-specific fine-tuning and data augmentation remain likely to yield incremental improvements, especially for classes of scenes (e.g., dense urban, mountainous) poorly represented in web-trained foundation backbones.
- Deeper exploration of foundation model pretraining corpora, architectural ablations, and joint hybrid approaches (combining explicit cross-modal supervision with robust, protocol-aware matching) will elucidate mechanisms underlying the success of present approaches.
Conclusion
Pretrained image matchers—if coupled with careful protocol design—are sufficient for accurate zero-shot registration of SAR and optical satellite imagery at sub-8 px accuracy. Protocol factors (geometry, tiling, normalization) dominate performance variation, and foundation model backbones (e.g., DINOv2-based architectures) exhibit strong modality-invariant properties even without explicit cross-modal training. The combination of dense correspondence architectures with protocol-robust deployment forms the foundation for operational satellite registration pipelines, although statistical generality and adaptability to new or extreme domains require further research.

