- The paper proposes Visual Late Chunking, a novel method that adaptively aggregates patch-level embeddings to significantly reduce storage requirements.
- It employs hierarchical clustering combined with spatial-semantic fusion to condense representations by about 90% compared to traditional multi-vector approaches.
- Experimental results demonstrate improved retrieval performance, with notable gains such as a 57% relative increase in nDCG@5 on benchmark models.
Visual Late Chunking for Efficient Visual Document Retrieval
Introduction
Multi-vector models set the benchmark for accuracy in Visual Document Retrieval (VDR) by harnessing the fine-grained spatial-semantic structure of visual documents through patch-level embeddings. However, their storage and computational costs, especially with thousands of embeddings per document, severely constrain deployment in large-scale production settings. This paper introduces a contextual chunking paradigm, termed Visual Late Chunking, that leverages hierarchical clustering and spatial-semantic fusion to distill patch-level embeddings into a compact, content-adaptive set of multi-vectors. The approach seeks a practical trade-off: sharply reducing memory footprint while enhancing or preserving retrieval performance over representative single-vector baselines.
Contemporary VDR frameworks can be grouped by retrieval granularities. Single-vector models, including those based on LVLM backbones, often fail to encode sufficiently rich fine-grained semantics present in visually complex documents, resulting in retrieval performance loss. In contrast, multi-vector pipelines, exemplified by ColPali and its variants, achieve state-of-the-art retrieval by representing each document as an unordered set of contextualized patch embeddings and performing late interaction at inference time. Previous attempts to compress such representations—either by merging similar tokens, pruning redundant tokens, or inserting learned summaries—often trade off retrieval quality or require substantial retraining and are sensitive to hand-designed partitioning or token selection strategies.
The text retrieval community has recently explored late chunking, wherein contextual token embeddings are pooled into chunks only as a final aggregation step, ensuring that each chunk encodes complete contextual information. The direct transplantation of this idea to visual documents is challenged by the inherently non-sequential, 2D nature of these substrates. Hence, an efficient approach to contextual chunking must integrate both semantics and layout in an adaptive, training-free fashion.
Methodology
The method processes each visual document as an image, passing it through a pre-trained LVLM encoder to yield patch-level contextual embeddings. To address the spatial-semantic entanglement of visual information, patch embeddings are fused with 2D sinusoidal positional encodings, balanced by a hyperparameter ω. Hierarchical Agglomerative Clustering (HAC) is then applied to these fused vectors. This clustering is run until only K clusters remain, each representing a chunk. The embedding for each chunk is subsequently formed by pooling (mean aggregation) the semantic embeddings of its constituent patches, followed by L2 normalization.
The approach’s distinctiveness lies in its adaptive chunk granularity—clusters can correspond to a handful of sparse elements or aggregate dense regions such as paragraphs or charts—enabling robust compression without sacrificing the preservation of critical semantics or spatial continuity. Theoretical support is outlined via the Information Bottleneck (IB) principle: the pipeline approximates an objective that maximizes retained salient information relevant to potential future queries while sharply minimizing embedding storage.
Experimental Results and Analysis
Evaluation on 24 VDR datasets, using five leading single-vector models as backbones, demonstrates pronounced improvements in both efficiency and retrieval efficacy. By representing each document page with only 40 multi-vectors (a ∼90% reduction from the default 768 in architectures such as ColQwen2.5), Visual Late Chunking yields an average improvement of 9 points in nDCG@5 compared to single-vector baselines.
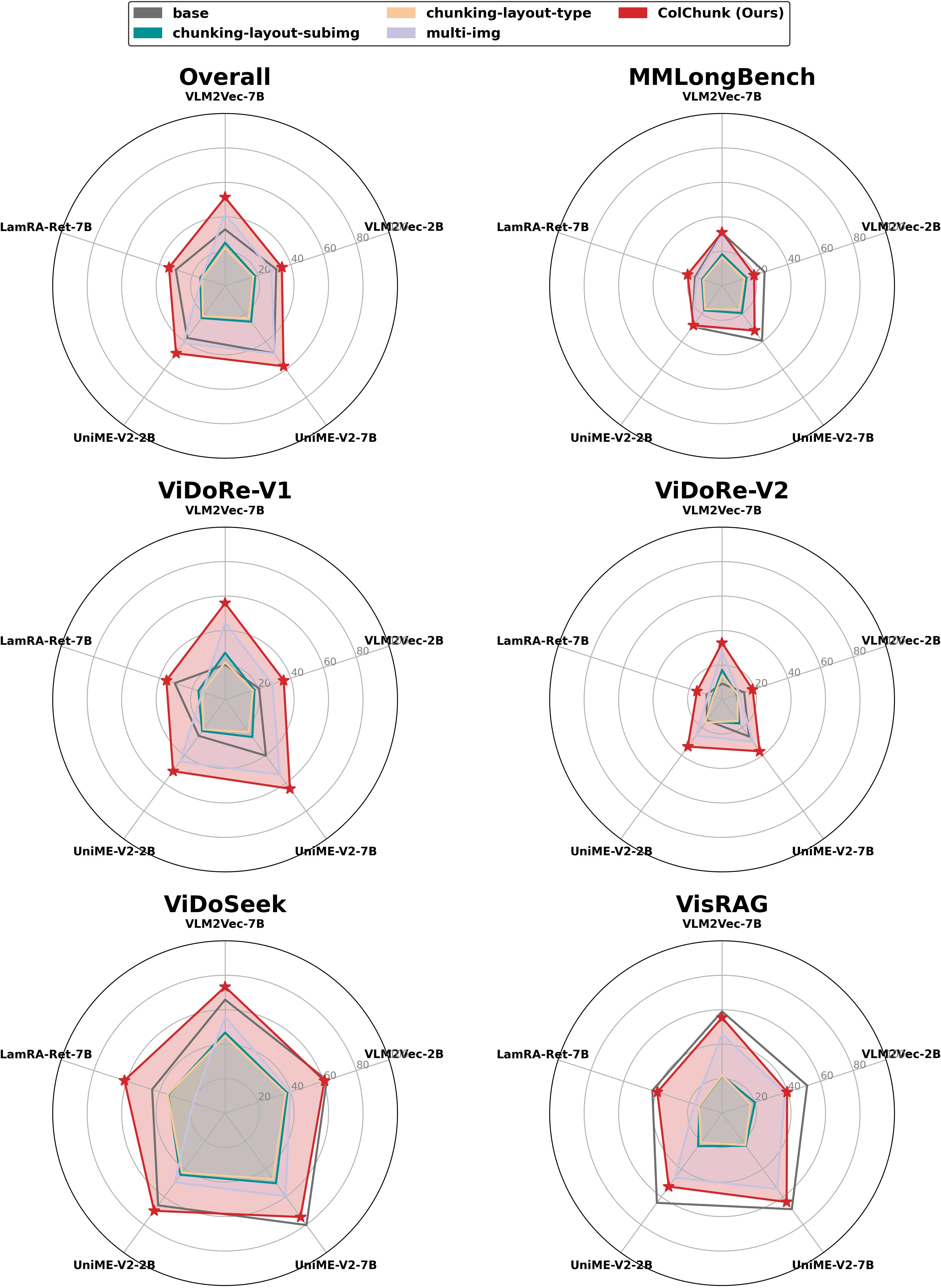
Figure 1: Retrieval performance on five VDR benchmarks comparing five single-vector retrieval models and their late chunking variants.
Performance gains are observed consistently across models and benchmarks. For instance, VLM2Vec-7B sees a relative nDCG@5 improvement of nearly 57% (from 32.74 to 51.32). Notably, late chunking outperforms explicit layout-based chunking schemes. On ViDoRe-V1, the method achieves a score of 55.89 versus 21.63 and 27.12 for type- and subimage-based grouping, respectively, indicating the superiority of clustering-driven, implicit partitioning over parsing-dependent approaches.
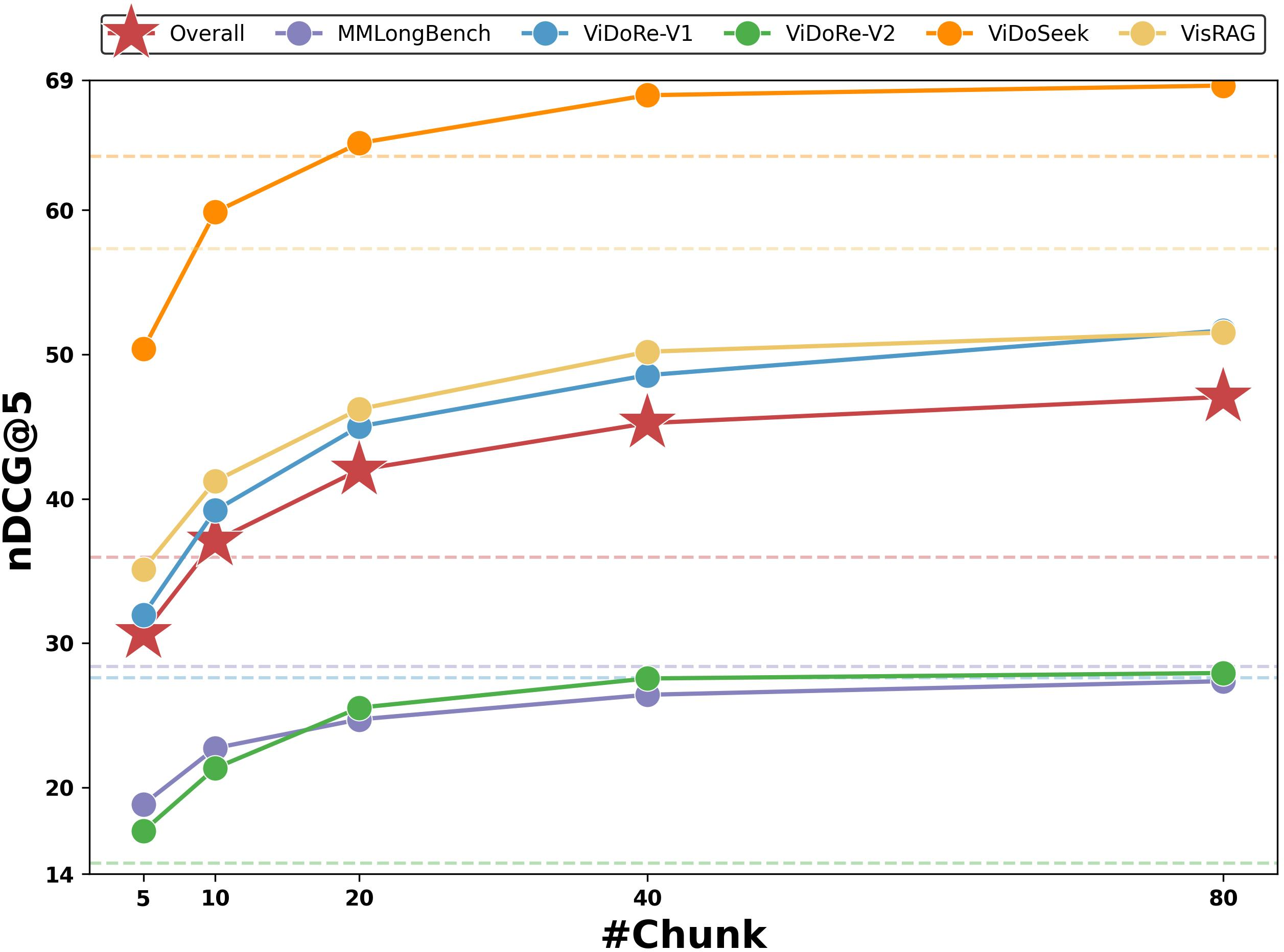
Figure 2: Average retrieval performance as a function of chunk size, with base model results shown as dashed lines.
Scaling ablation reveals that increasing chunk count monotonically increases retrieval performance, but gains diminish beyond moderate values (see Figure 2). Empirically, setting K in the range 40–80 provides near-optimal trade-offs, while undersized chunk counts (K≤5) can depress performance well below the original single-vector baseline, due to overmerging semantically disparate content.
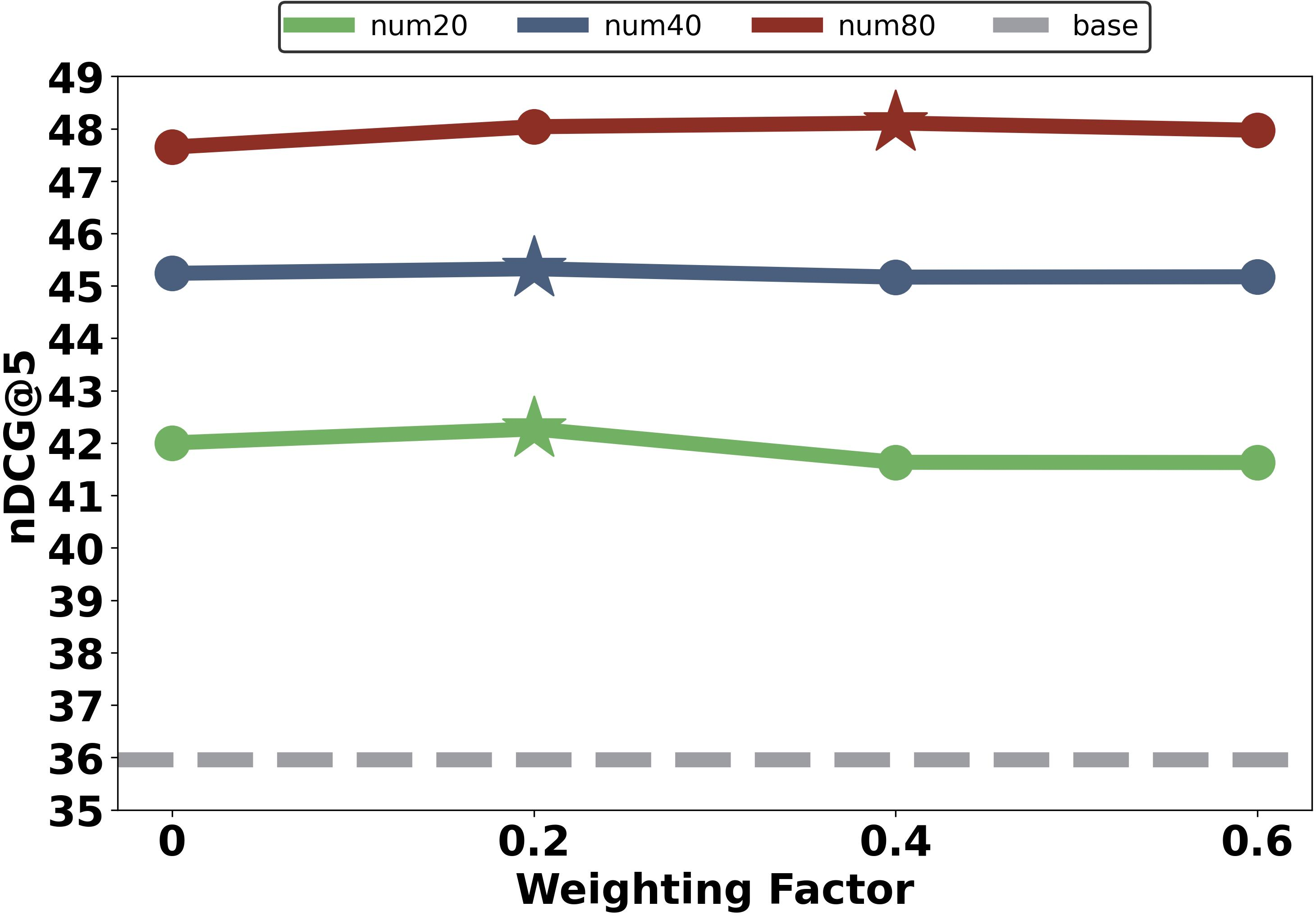
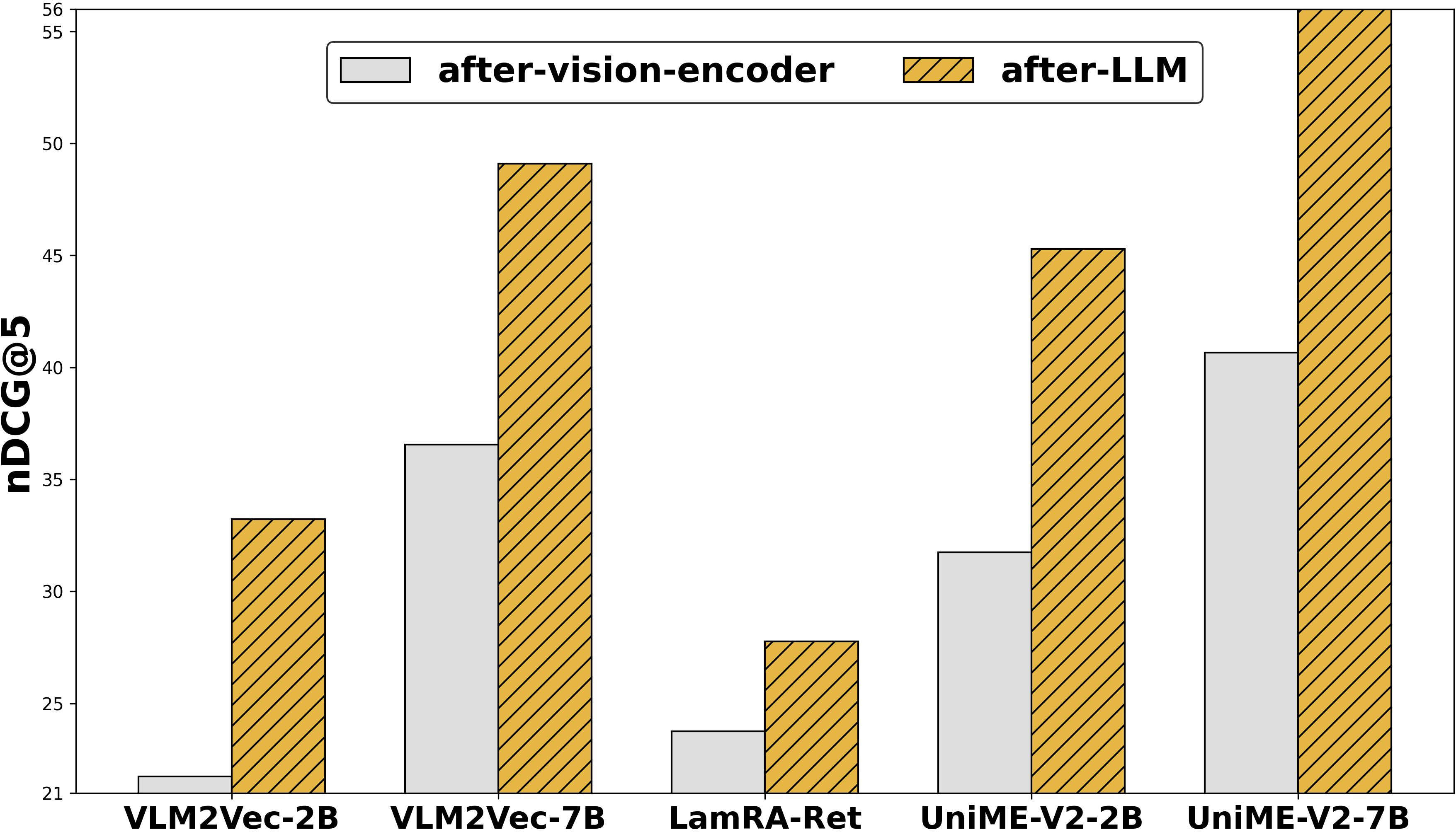
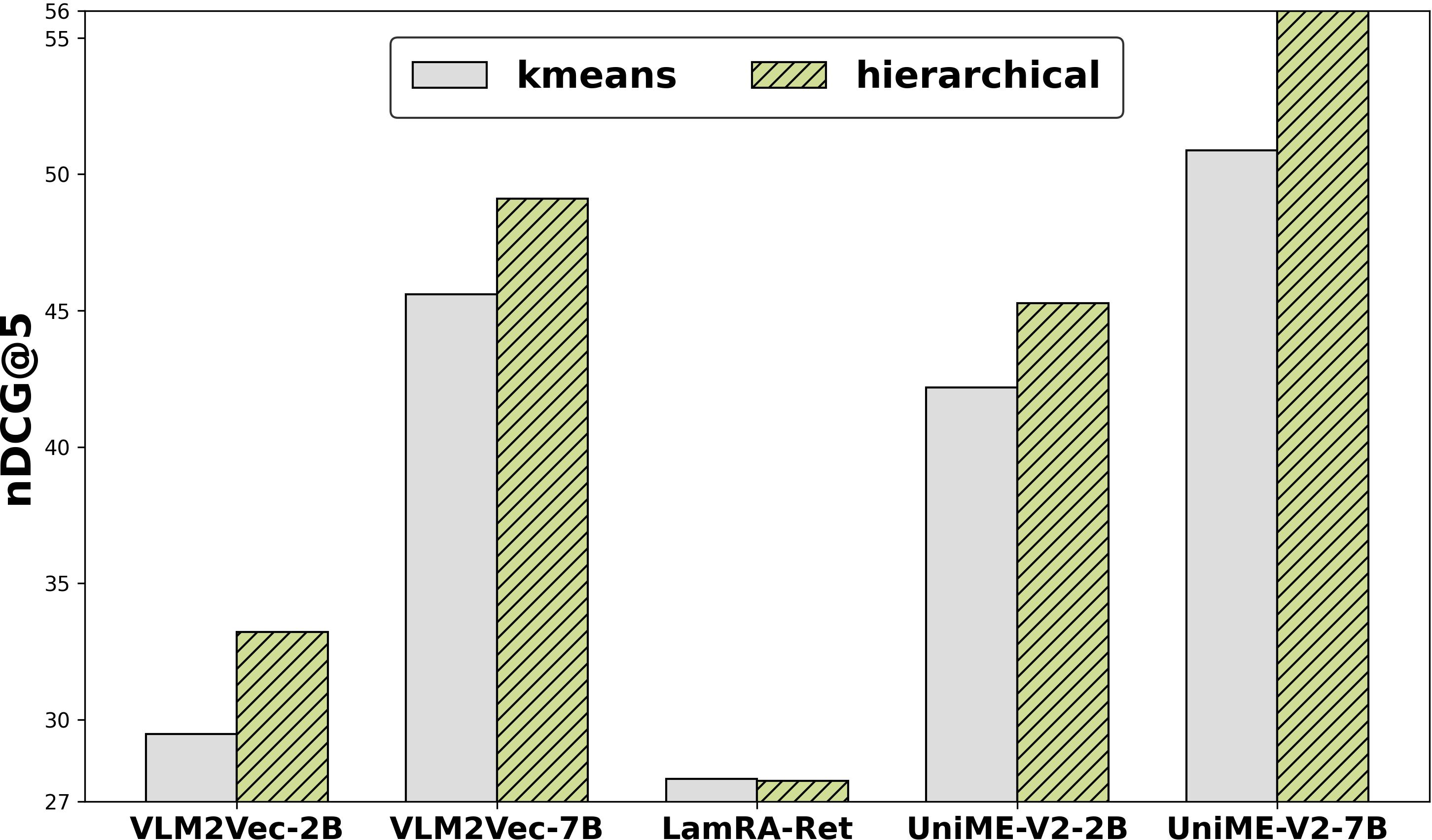
Figure 3: Analysis of (Left) weighting factor ω, (Middle) chunking stage (post-vision encoder vs. post-LLM backbone), and (Right) clustering method (k-means vs. hierarchical) on retrieval performance.
Ablation on key hyperparameters, visualized in Figure 3, elucidates critical design principles:
- Moderate spatial weighting (ω≈0.2) yields the best results, as overemphasis of layout degrades semantic coherence.
- Performing chunking post-LLM backbone is essential; chunking after the vision encoder sacrifices high-level context, yielding inferior embeddings.
- HAC consistently surpasses k-means in cluster quality and downstream retrieval performance, owing to its capacity to adapt to heterogenous semantic region scale and shape.
Implications and Future Directions
The framework sets a new practical baseline for memory-efficient, high-performance VDR, with immediate applicability to large-scale enterprise search and web-scale document understanding, where storage constraints are acute. Its plug-and-play, training-free nature enables seamless integration with a wide array of pretrained vision-language backbones and multimodal embedding systems.
From a theoretical standpoint, the results validate the efficacy of content-aware, spatially-informed aggregation strategies for non-sequential modalities. This paradigm is likely to be extensible to other non-textual domains—e.g., radiology, floor plans, or scientific diagrams—where variable-scale semantic regions exist.
Future research may refine both clustering protocols (e.g., via self-supervised objectives or reinforcement learning) and fusion strategies for even tighter bounds on the performance-to-efficiency Pareto front. Moreover, applying late chunking jointly in query and document space, or in online/adaptive regimes, could yield further advances for retrieval-augmented reasoning agents operating over long-horizon, visually rich contexts.
Conclusion
Visual Late Chunking presents a principled, empirical improvement to visual document retrieval by fusing spatial and semantic signals, flexibly chunking patch-level embeddings, and drastically reducing vector footprint without sacrificing—indeed, often improving—retrieval accuracy. Its methodologically robust, yet architecture-agnostic, approach provides a compelling avenue for future research at the intersection of efficient multimodal retrieval and large-scale document intelligence (2604.10167).

