- The paper proposes a dual cross-attention graph learning framework that fuses sMRI and rs-fMRI for robust MDD detection.
- It employs ROI extraction, ViT-based encoding, graph construction with GATs, and reciprocal attention to model bidirectional structural-functional interactions.
- The framework outperforms traditional methods, achieving up to 84.71% accuracy on functional atlases with statistically significant improvements.
Dual Cross-Attention Graph Learning for Multimodal MRI-Based MDD Detection
Introduction
Major Depressive Disorder (MDD) is associated with nuanced alterations in both structural and functional brain networks. While single-modality neuroimaging has unveiled discriminative markers for MDD, combining modalities such as structural MRI (sMRI) and resting-state functional MRI (rs-fMRI) offers a more integrative view of the disorder's neurobiological underpinnings. However, most prior multimodal frameworks rely on simplistic fusion strategies (e.g., feature concatenation) that disregard the intricate, bidirectional relationships between modalities. The current work proposes a dual cross-attention graph learning framework that explicitly models bidirectional structural–functional interactions at the node level, leveraging both sMRI and rs-fMRI data for robust MDD detection (2604.10116).
Methodological Framework
The proposed architecture features a unified and modular approach that comprises four main stages: atlas-based ROI extraction, deep feature encoding, graph construction, and multimodal fusion via dual cross-attention.
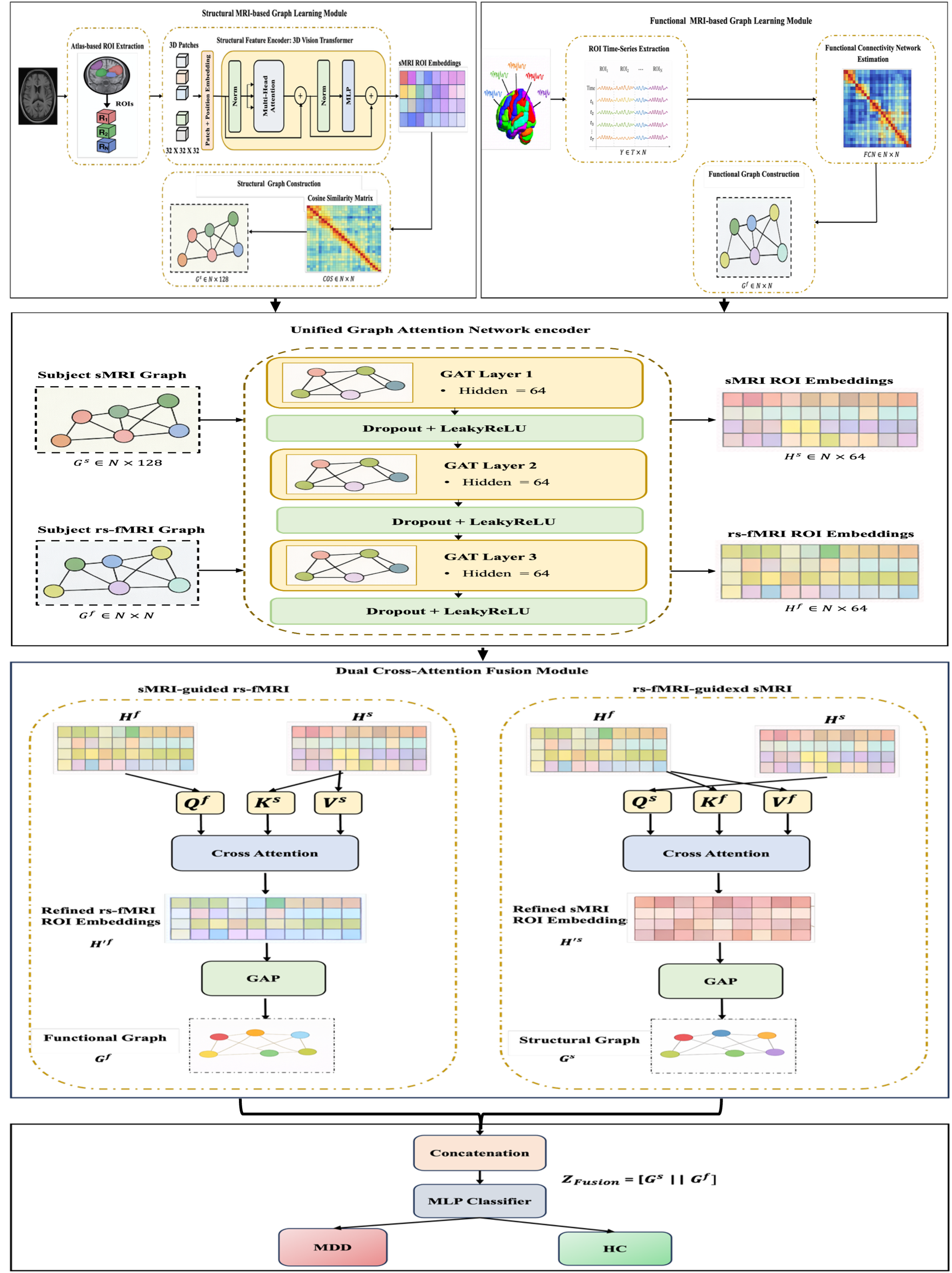
Figure 1: The architecture extracts ROI-level embeddings from sMRI and rs-fMRI, constructs structural and functional graphs via ViT and connectivity, processes them with GATs, and fuses through dual cross-attention prior to MDD/HC classification.
ROI Extraction and Feature Encoding
Brain ROIs are delineated using both structural (AAL, HO) and functional (Dosenbach, Craddock) atlases to scrutinize the effect of parcellation schemes on model performance. For sMRI, 3D patches are fed into a Vision Transformer (ViT), yielding high-dimensional ROI embeddings that capture both global and region-specific morphological features. For rs-fMRI, voxelwise time series within each ROI are averaged, and functional connectivity matrices are computed via Pearson correlation, followed by Fisher’s z-transformation for variance stabilization.
Graph Construction
Subject-specific graphs are constructed for both modalities. In the structural branch, ROI embeddings serve as nodes, with edges reflecting cosine similarity to capture anatomical co-variations. For the functional branch, nodes are assigned the ROI’s connectivity profile (i.e., one FCN row), and edges are determined by top-K functional connectivity values. KNN sparsification (K=10) is applied to both graphs for computational efficiency and reduction of noisy relationships.
Unified Graph Attention Encoding
A shared Graph Attention Network (GAT) encoder is independently applied to both modality-specific graphs. Attention coefficients enable adaptive, data-driven weighting of inter-regional interactions, thus modeling topological variability and subject-specific brain organization within each modality.
Multimodal Fusion: Dual Cross-Attention
The core innovation lies in the dual cross-attention fusion mechanism. For each subject, structural and functional GAT embeddings undergo two complementary interactions:
- sMRI-guided fMRI attention: Structural node features act as keys and values to refine functional node queries.
- fMRI-guided sMRI attention: Functional node features serve as keys and values for the structural queries.
Each branch produces modality-refined node embeddings, aggregated via global average pooling and concatenated for downstream classification with an MLP. This reciprocal attention enables dynamic, region-wise calibration of multimodal features, enhancing the model's ability to identify coupled disruptions in MDD.
Experimental Evaluation
Dataset and Preprocessing
The evaluation leverages the REST-meta-MDD consortium dataset, encompassing 1,563 subjects from 16 imaging sites with harmonized sMRI and rs-fMRI data. Comprehensive demographic, clinical, and imaging covariates are harmonized via ComBat for batch effect mitigation, and confounders are regressed using Gaussian process models.
Comparative Analyses
Experiments systematically compare the proposed dual cross-attention fusion against feature-level concatenation across both structural and functional atlases. Stratified 10-fold cross-validation is employed for robust performance estimation.
Key Results:
- For functional atlases (e.g., Dosenbach), the dual cross-attention model yields the highest accuracy at 84.71%, sensitivity at 86.42%, specificity at 82.89%, precision at 84.34%, and F1-score at 85.37%.
- For structural atlases, dual cross-attention achieves parity with concatenation, demonstrating high stability but less pronounced gains.
- Statistical analyses (two-sample t-tests) reveal that improvements with dual cross-attention are significant (p < 0.05) for accuracy, specificity, and F1-score—especially with functional parcellations.
Benchmarking Against Prior Work
The dual cross-attention architecture matches or outperforms leading multimodal and unimodal deep learning approaches [alotaibi20263dvit; alotaibi2025multi; zheng2023attention; yuan2023cross; chen2025mmdd; fan2025classifying; li2024evolutionary]. Notably:
- The proposed model surpasses previous state-of-the-art methods, such as the Brain Dynamic Attention Network yuan2023cross and federated contrastive approaches [fan2025classifying], on all primary performance metrics.
- Performance margins over single-modality networks (ViT-GAT for sMRI: accuracy ≈ 74–78%) are particularly substantial for functional ROI models, reflecting the crucial role of cross-modal interaction modeling.
Implications and Future Directions
The dual cross-attention scheme establishes a formal mechanism for reciprocal information flow between structural and functional representations, demonstrating that explicit graph-level bidirectional attention enhances classification for neuropsychiatric disorders. The results underscore the inadequacy of mere feature concatenation, especially when functional atlases are used, and suggest that cross-modal dependencies are critical to accurate characterization of MDD-related brain alterations.
Practically, this approach supports the development of neuroimaging-based biomarkers with greater specificity and sensitivity, potentially facilitating earlier and more reliable identification of MDD. The framework’s modularity also invites extensions to further imaging modalities (e.g., DTI), longitudinal cohort analysis, and graph-based interpretability.
Theoretically, these findings highlight the importance of modeling inter-modality dependencies at the level of brain network organization, suggesting that optimal representations for psychiatric phenotyping are neither solely local nor entirely global, but contingent upon dynamic inter-modal synergy.
Future research should pursue multi-atlas integration within the cross-attention framework to exploit complementary parcellation schemes, investigate alternative attention mechanisms (e.g., transformer blocks at the graph level), and incorporate explainability modules for region-specific relevance mapping.
Conclusion
This study introduces a dual cross-attention graph learning framework for multimodal MRI-based MDD detection, achieving state-of-the-art performance on a large, multi-site dataset by explicitly modeling bidirectional structural–functional interactions. Superior numerical results—most saliently for functional atlas configurations—underscore the value of graph-level cross-modal attention. This work provides an extensible foundation for interpretable, transdiagnostic neuroimaging biomarker development in MDD and related disorders.

