- The paper introduces a masked contrastive pre-training framework using vertical patching to capture detailed pitch-sensitive representations essential for accurate key detection.
- It employs a SimpleViT-based Myna-Vertical model and shallow, wide MLPs, achieving strong performance with minimal reliance on complex augmentations.
- Robust invariance to common augmentations and efficient feature extraction are validated on benchmark datasets, challenging augmentation-heavy methods in MIR.
Masked Contrastive Pre-Training for Music Audio Key Detection
Motivation and Positioning
Music key detection demands pitch-sensitive representations due to the central role of harmonic structure in tonality estimation. Previous efforts in Music Information Retrieval (MIR) leveraged either template matching or supervised deep learning, but these paradigms display limited generalization and require extensive expert labeling or intensive genre-specific tuning. While large-scale self-supervised music models now offer competitive performance on MIR tasks such as tagging or instrument recognition, prior work has demonstrated that these do not yield strong results on key detection, specifically due to their insufficient pitch sensitivity. The study under review addresses this gap by systematically investigating how self-supervised pre-training design for music representation learning governs pitch sensitivity, and thus key detection efficacy.
Methodological Framework
The authors introduce KeyMyna, a pipeline utilizing Myna-Vertical, a SimpleViT-based model pretrained via masked contrastive learning on unlabeled music audio. The central innovation lies in the masked contrastive pre-training regime, where random patch masking on Mel spectrograms acts as the sole augmentation. This approach eliminates the need for pitch-shifting or spectral augmentation during pre-training, ensuring that the resulting representations maintain high fidelity to pitch content and are thus well-suited for downstream key estimation tasks.
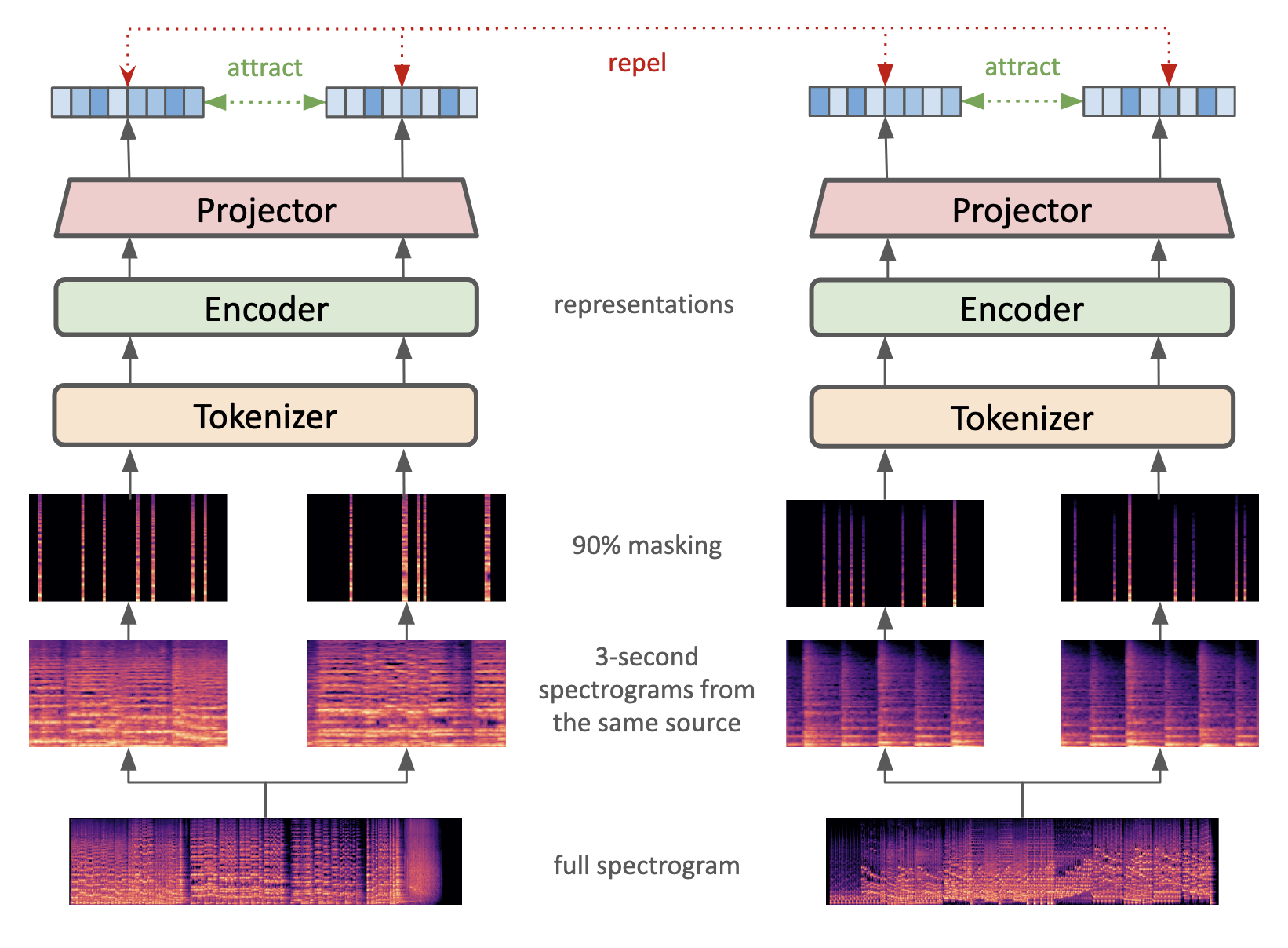
Figure 1: Myna's pre-training framework applies masked contrastive learning with vertical spectrogram patches to capture pitch-sensitive representations for MIR tasks.
Myna-Vertical employs vertical patching (128×2 time–frequency dimension per patch), ensuring that each patch encompasses all frequency bins at a discrete time step. This configuration contrasts with conventional square patching, which entangles harmonic and temporal content and impedes pitch-specific learning. The pretrained encoder (projector discarded post-pretraining) serves as a fixed feature extractor for downstream supervised models.
For the downstream key detection head, the study systematically explores shallow (1–2 hidden layer) but wide (2048–8192 hidden units) MLPs with high dropout rates, optimizing for sample efficiency and generalization. The approach leverages grid search over architecture and optimization hyperparameters and investigates the impact of MixUp augmentation, finding its effects dataset-dependent.
Experimental Evaluation and Results
The method is evaluated on GiantSteps (electronic dance music) and McGill Billboard (pop/rock) datasets. Strong performance is achieved via linear classifiers atop frozen Myna-Vertical features, outperforming linear probes on MERT and matching or surpassing results from state-of-the-art deep CNNs with more complex architectures and heavy augmentation pipelines. Notably, SOTA results are demonstrated by shallow, wide MLPs, with minimal need for augmentation beyond pitch shifting, contrasting with the augmentation-heavy prior SOTA (e.g., InceptionKeyNet).
KeyMyna achieves 75.91% weighted accuracy on GiantSteps and 84.35% on McGill Billboard, outperforming prior public systems and challenging augmentation-heavy InceptionKeyNet, despite using less labeled data and simpler architectures.
Analysis of Representation Robustness
An additional contribution is the demonstration of robust invariance of Myna-Vertical embeddings to common augmentations. T-SNE visualization confirms that augmented variants of audio samples map to proximate locations in the embedding space. Linear transformations trained to emulate augmentations in embedding space yield accurate results, suggesting that such invariance is explicitly encoded and can be exploited for downstream robustness.
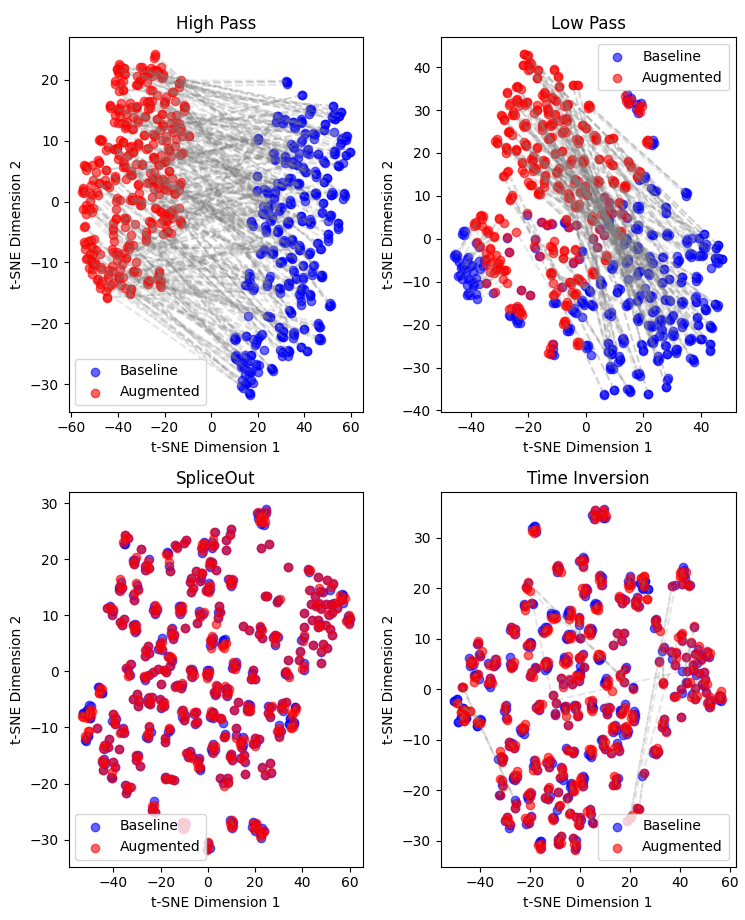
Figure 2: Myna-Vertical’s embedding space demonstrates robust clustering of original and augmented audio samples, supporting linear separability and invariance.
This property indicates that the approach not only avoids the destructive effects of pitch-invariant pretraining seen in prior work but also confers robustness to timbral and spectral artifacts without explicit supervision or augmentation tuning.
Theoretical Implications and Future Prospects
The study offers strong empirical evidence contradicting the common assumption that large foundation models pretrained for global invariance, or heavily augmented pipelines, are necessary for high performance in pitch-centric MIR tasks. Instead, architecture and pre-training strategy alignment with the target task is essential—here, masked contrastive learning with vertical patching is critical for capturing harmonic structure. This framework sets a precedent for domain-aligned architectural choices in self-supervised MIR research.
The findings suggest several directions for advancing the field:
- Model Scalability vs. Efficiency: While scaling model or data size may yield marginal accuracy boosts, practicality for real-time or resource-constrained applications remains paramount.
- Key Modulation and Sequential Modeling: The current approach predicts a piece-level global key; modeling dynamic key changes (modulations) or local harmonic contexts will likely require temporal aggregation (e.g., with sequence models over patchwise embeddings).
- Fine-tuning and Adapter Layers: Incorporating lightweight fine-tuning could enhance adaptation, e.g., via prompt-tuning or adapter layers.
- Beyond Western Tonality: Extending to microtonal, modal, or polytonal contexts represents a significant theoretical and practical challenge not addressed in the current paradigm.
Practical and Theoretical Implications
Practically, this work demonstrates that robust, generalizable MIR key detectors can be built with minimally supervised pipelines, scalable across large, unlabeled music corpora. For real-world MIR systems—playlisting, recommendation, music search, and interactive DJ tools—this enables strong accuracy without costly labeling or complex engineering.
From a theoretical standpoint, the results empirically isolate the causal effect of pre-training method on pitch sensitivity and MIR task transfer in foundation models, pointing to a requirement for harmonically-aligned pre-training—even when transferability and generalization are the goals.
Conclusion
This study systematically establishes that masked contrastive pre-training, when paired with vertically patched ViT encoders, produces pitch-sensitive embeddings essential for accurate music key detection. Shallow, wide MLP heads trained on frozen embeddings rival or surpass the performance of deep, augmentation-heavy models, shifting the paradigm for MIR model design. The approach offers robust, efficient alternatives for MIR applications, and charts a clear trajectory for future work—spanning architectural fine-tuning, sequence modeling, and the adaptation to non-Western harmonic contexts.
Citation: "Masked Contrastive Pre-Training Improves Music Audio Key Detection" (2604.10021)

