- The paper presents a hybrid FHE-MPC framework that minimizes ciphertext repacking to reduce inference latency and communication overhead.
- It establishes robust cross-layer packing protocols and secure conversion boundaries that seamlessly integrate with Transformer architectures like BERT and GPT.
- Empirical results show 1.3×–9.8× latency improvements and minimal accuracy loss, demonstrating practical deployment viability for secure ML inference.
Introduction and Motivation
Machine-learning-as-a-service (MLaaS) deployments of Transformer models for sensitive applications raise significant privacy concerns, as both user inputs and inference outputs are potentially exposed to an untrusted server. Existing approaches for secure inference employ fully homomorphic encryption (FHE), secure multiparty computation (MPC), or hybrid FHE--MPC pipelines, but each carries intrinsic limitations related to efficiency, practicality, or communication overhead. EncFormer proposes an integrated framework for hybrid FHE--MPC Transformer inference that aims to systematically eliminate redundant overhead at packing, boundary, and conversion levels, with robust empirical gains in both latency and communication over prior art.
Hybrid Secure Inference: System Architecture
EncFormer instantiates a two-party protocol, where the client holds the secret key and the private inference query, and the server holds the Transformer model. The inference pipeline consists of composed FHE kernels for wide linear maps, MPC blocks for nonlinear operations (softmax, GELU, layer normalization), and well-defined conversion boundaries. A security proof is established under the semi-honest model, ensuring no leakage beyond intended outputs under standard FHE and MPC assumptions.
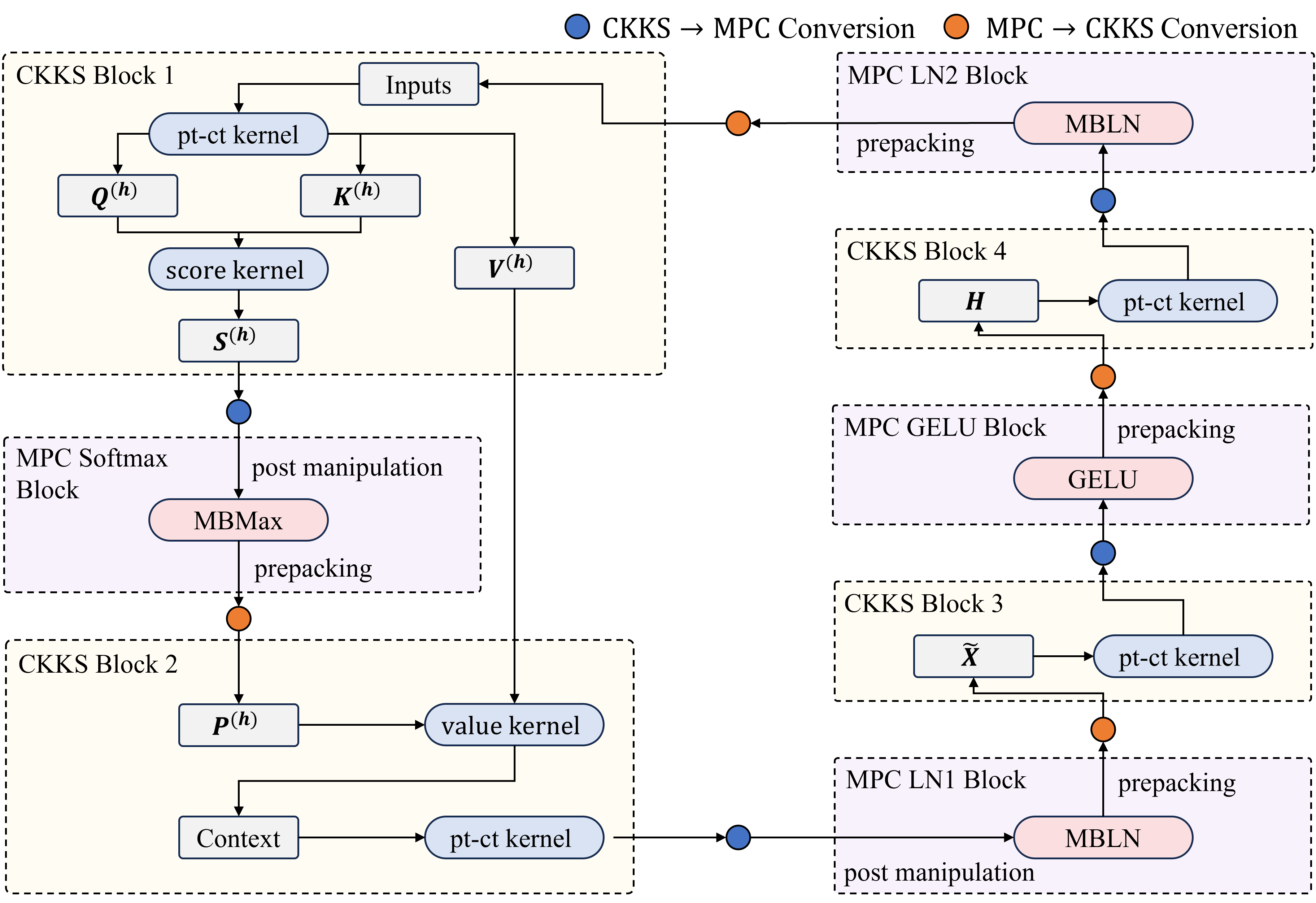
Figure 1: EncFormer encoder block showing FHE kernels, MPC nonlinear blocks, and CKKS--MPC conversion boundaries.
The Transformer backbone (BERT, GPT) is retained without structural modification, with extensive architectural and cryptographic co-design applied to all secure computation layers: packing layouts, attention kernels, and conversion protocols are explicitly orchestrated for minimal representational overhead.
Packing-Co-Designed FHE Kernels
Efficient FHE kernel design in EncFormer centers on two disciplines: stage-compatible packing and minimal conversion. The pipeline restricts ciphertext layout to a small set of canonical forms — segment-column, folded-diagonal, head-major — with each FHE kernel producing outputs directly consumable by its downstream consumer, obviating costly ciphertext repacking between successive FHE stages. Packing contracts, denoted as Stage Compatible Patterns (SCP), are rigorously enforced.

Figure 2: Illustration of RNS--CKKS, showing the residue representation and the modulus-chain progression under rescaling.
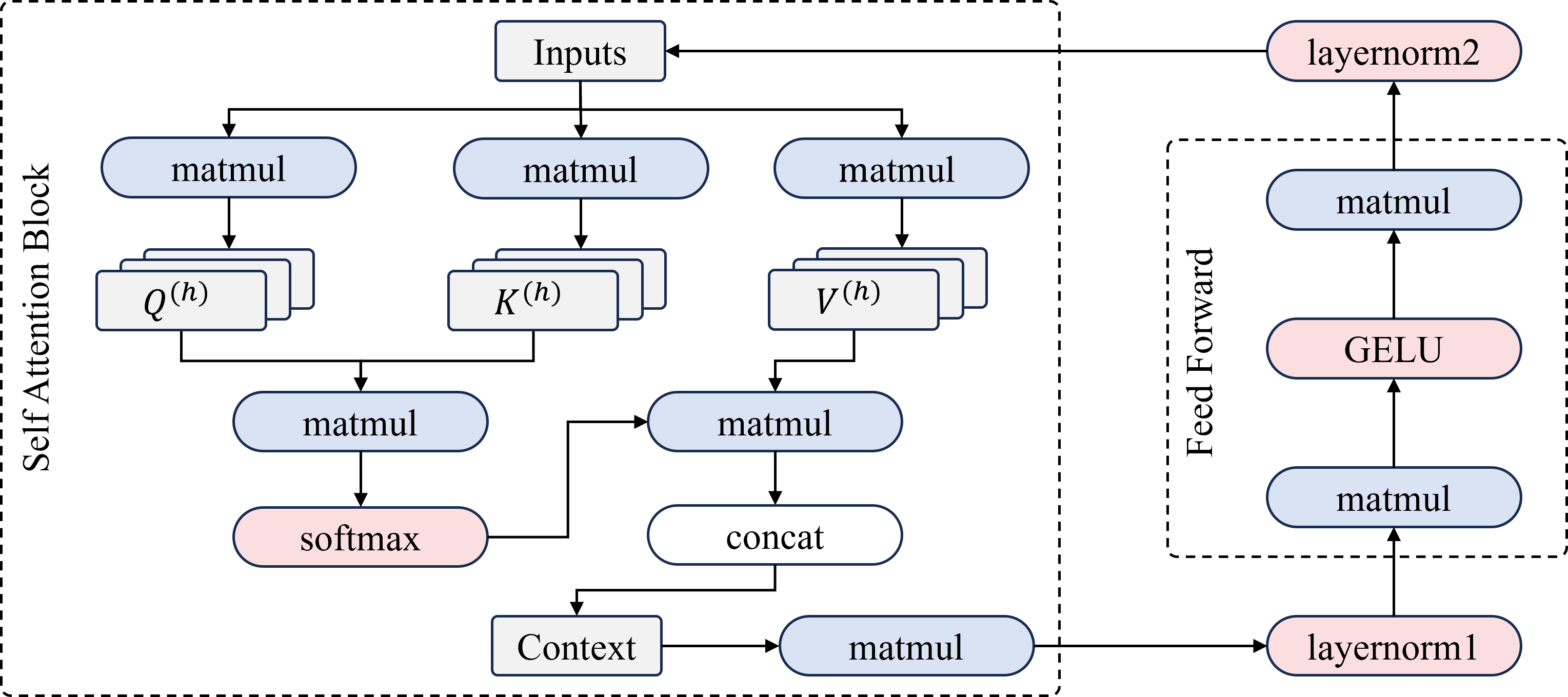
Figure 3: Reference Transformer architecture used in this work, highlighting attention, feed-forward layers, and the output head.
Minimal and expanded packing variants are quantitatively analyzed (Figure 4), and ciphertext count at MPC boundaries is always minimized unless an expanded packing is analytically justified by the downstream computational cost model.

Figure 4: Packing comparison for a 2×4 matrix with n=4 slots per ciphertext. Minimal packing uses Kmin ciphertext.
EncFormer's attention mechanisms implement specialized folded-diagonal and head-major packing layouts for QK⊤ computation and PV, reducing key-switches compared with generic blockwise representations. Toy examples in Figure 5 illustrate these packing strategies.
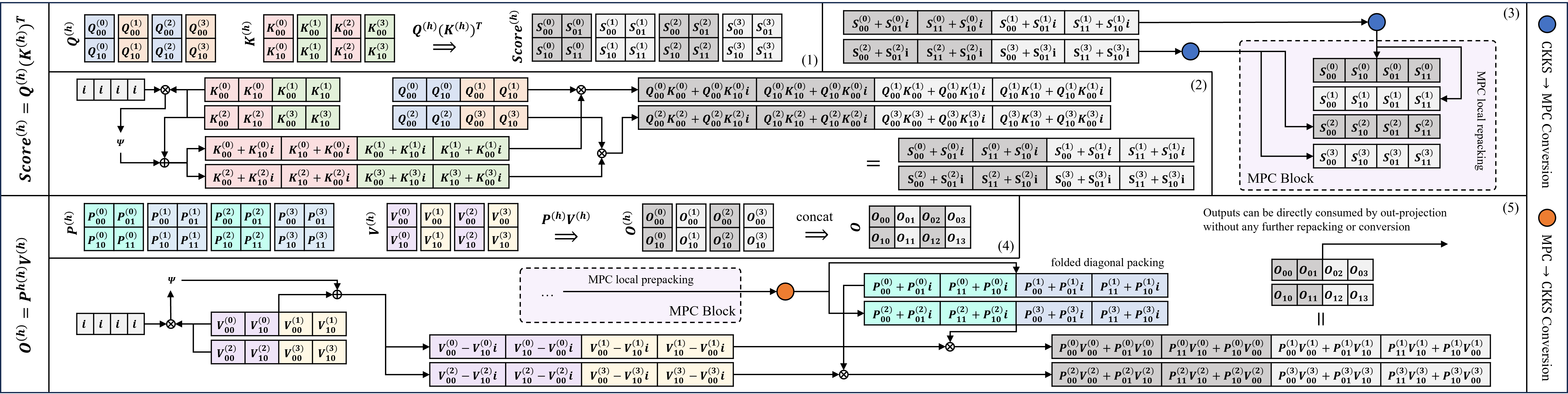
Figure 5: Toy example of the attention kernels with H=4, m=2, dh=1, and n=4 slots. Each ciphertext contains Nseg=2 segments.
Boundary Co-Design and Secure Conversion
Conversion between FHE and MPC domains is a major performance determinant in hybrid pipelines. EncFormer introduces a secure complex CKKS--MPC conversion protocol, exploiting both real and imaginary parts of each CKKS slot to halve conversion payload per boundary. The protocol produces two independent real vector shares per ciphertext, fully compatible with real-valued MPC nonlinearities.
A calibrated cost model is built around a minimal-conversion baseline, parameterized in terms of the number of MPC blocks, ciphertext shape, CKKS parameterization, and network bandwidth/RTT. This model enables principled, data- and backend-aware selection of expanded packing/conversion when such deviation yields a net reduction in end-to-end latency.
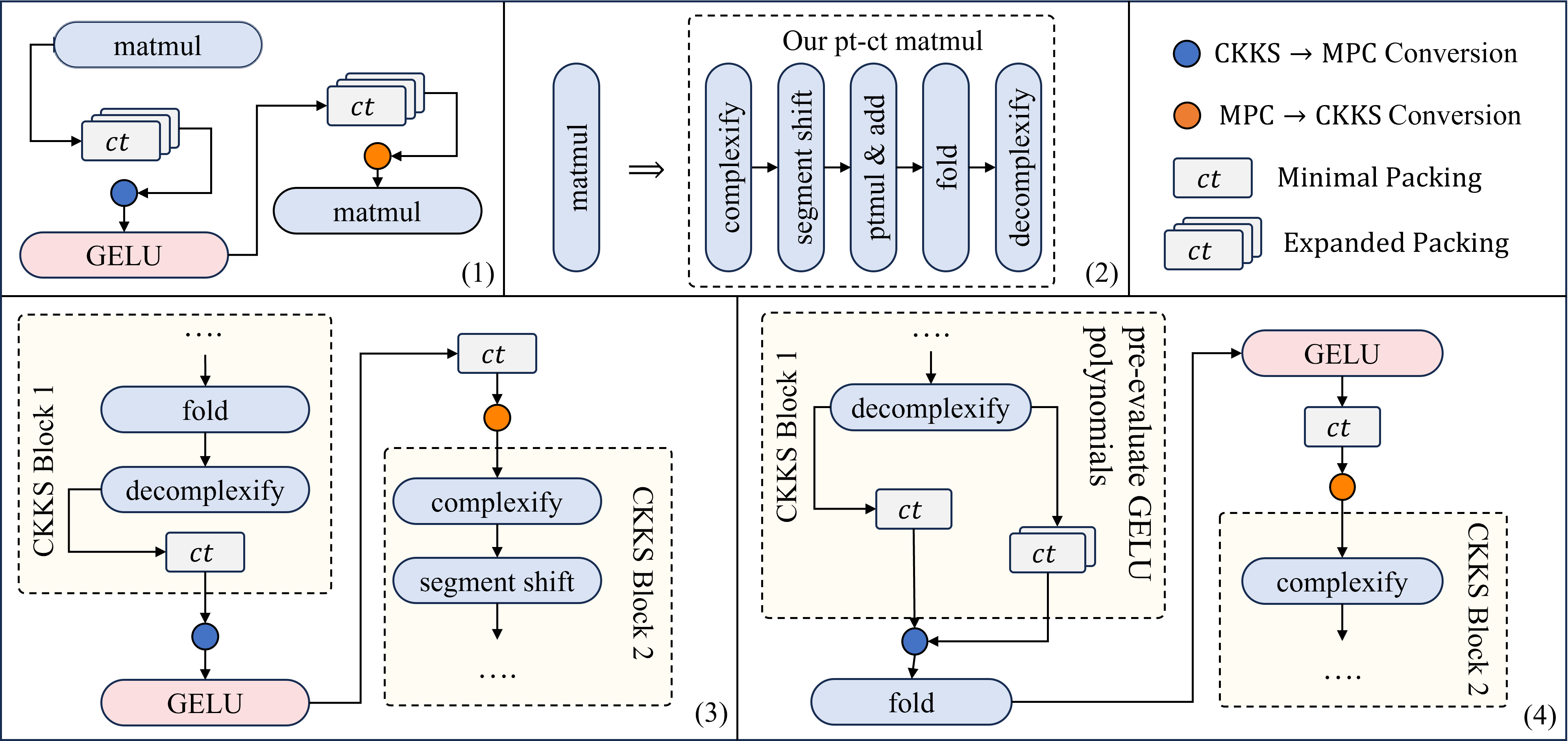
Figure 6: Architecture comparison for hybrid inference. (1) Prior layerwise hybrid pipeline with expanded packing. (2) Component view of a plaintext--ciphertext projection kernel. (3) Minimal baseline using minimal packing at conversions. (4) EncFormer pre-evaluates GELU polynomials in CKKS with expanded boundary packing for lower MPC cost.
Communication-Efficient MPC Blocks
EncFormer refines MPC blocks for nonlinear operations:
- Softmax/MBMax: Batch Power-Max with public normalization, distilled parameters; 3 rounds per layer.
- LayerNorm (MBLN): Linearized to public affine maps with locally computed mean subtraction, eliminating interactive rounds.
- GELU: Supports both CKKS pre-evaluation and MPC-only evaluation, with full conversion payload analysis guiding design choice.
These choices minimize interaction and data transferred, a critical factor for practical WAN deployments.
PhantomFHE and EzPC/SCI are used for backend implementation; all FHE computation is GPU-accelerated. EncFormer is evaluated on standard models (GPT2-base, BERT-base, BERT-large) on selected GLUE tasks, with multiple network configurations ranging from LAN to high-latency WAN.
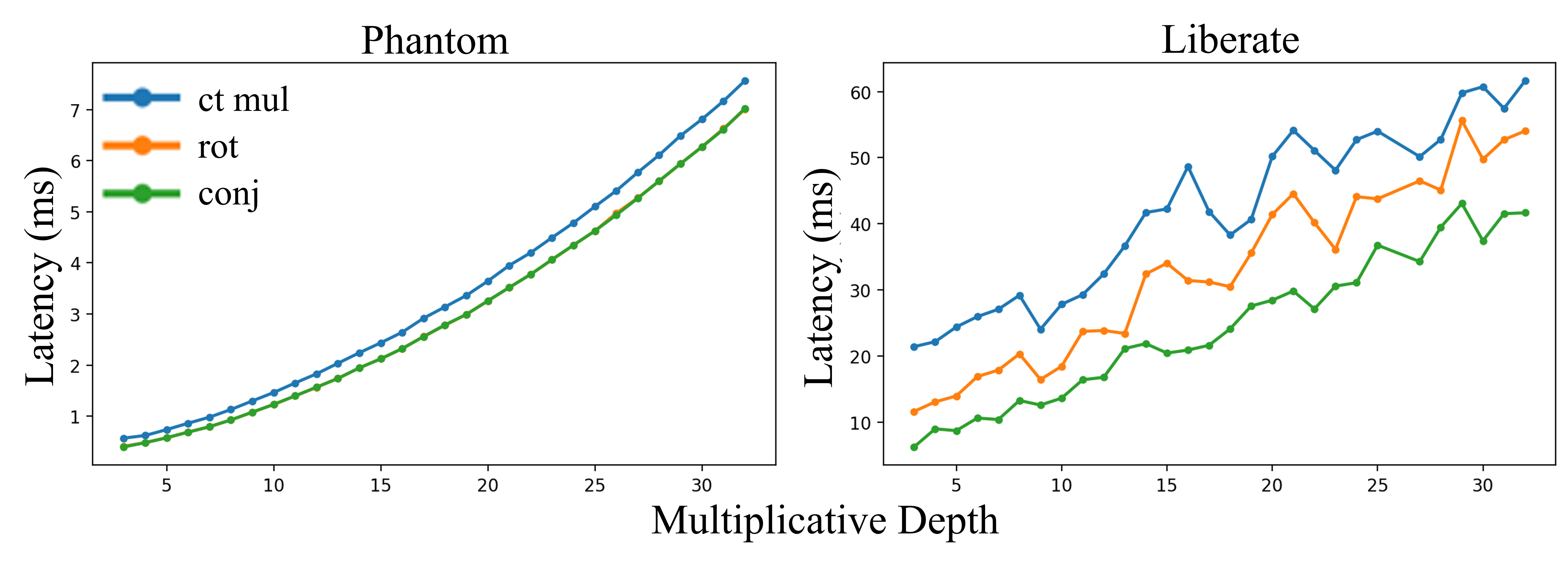
Figure 7: CKKS primitive latency vs.\ multiplicative depth for PhantomFHE and Liberate.FHE.
The empirical evaluation demonstrates:
- End-to-end latency improvement over prior FHE--MPC hybrid systems: 1.4n=40–30.4n=41 reduction in online MPC communication and 1.3n=42–9.8n=43 decrease in overall latency.
- Comparison against FHE-only systems: For BERT-base, EncFormer yields 1.9n=44–3.5n=45 lower latency than FHE-only pipelines on identical backends, due to avoidance of bootstrapping operations and strict packing compatibility.
- Minimal accuracy loss on all tasks, with error induced almost entirely by surrogate approximations to nonpolynomial functions, not by encrypted computation.
Ablation and Boundary Optimization
Ablation studies dissect the savings from each core optimization: disabling complex conversion or SCP packing (Figure 8) increases boundary payload and FHE compute cost, respectively, confirming the necessity of co-design at the boundary and packing levels.
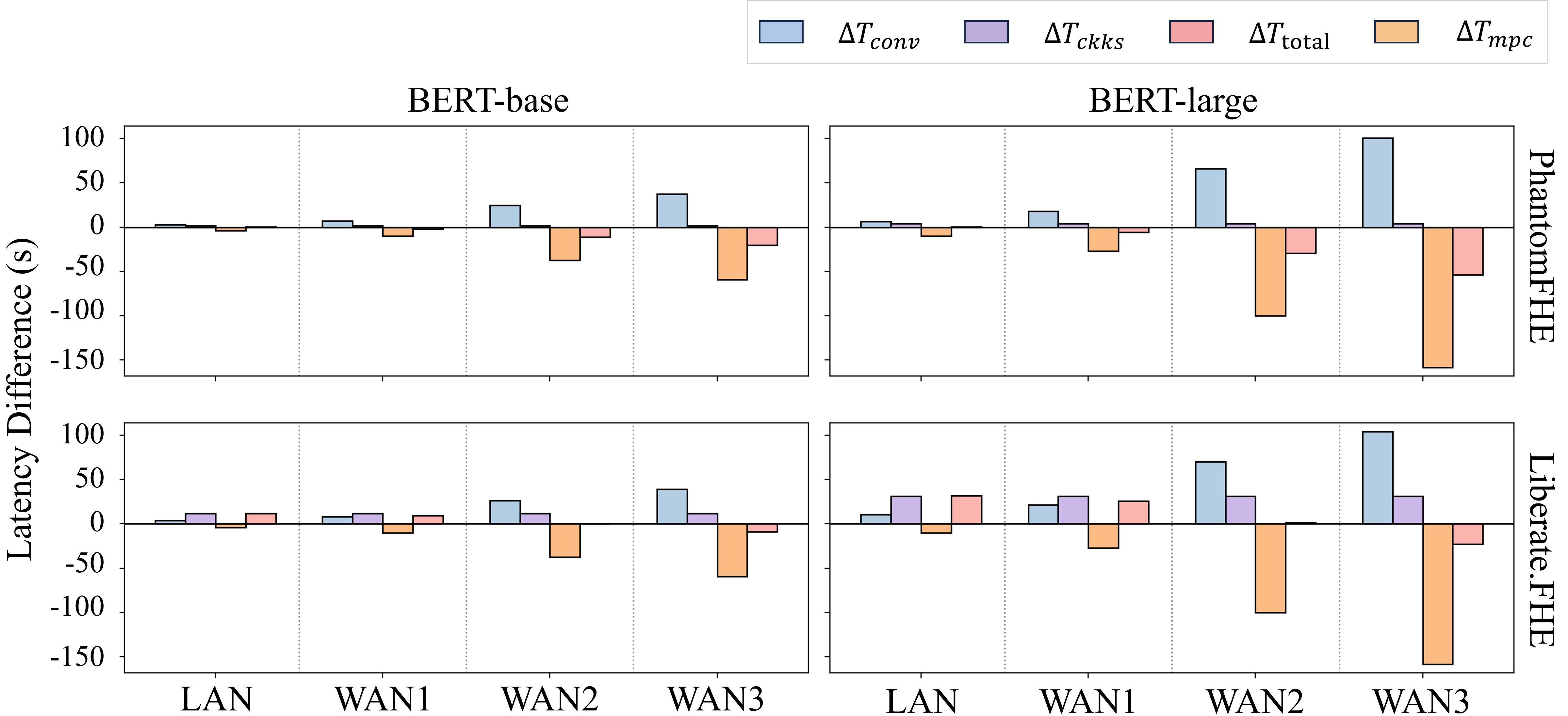
Figure 8: GELU latency deltas between EncFormer and the minimal baseline, split into computation savings and boundary conversion overhead.
Practical and Theoretical Implications
EncFormer positions itself as a template for future hybrid, pipeline-level secure inference frameworks. The work suggests that optimal secure ML inference cannot be approached as the sum of FHE and MPC optimizations; rather, efficiency gains are realized by designing around cross-layer compatibility and conversion economics. The modular encapsulation of packing, conversion, and boundary analysis generalizes to other multi-stage inference pipelines and motivates richer system-level cost modeling beyond primitive benchmarking.
Future Directions
Critical limitations remain, notably the need for surrogate-aware retraining to match cryptographically tractable nonlinear operators, and the semi-honest model assumption. Opportunities for extension include full malicious security, automatic boundary optimization under nonstationary network conditions, and application to even broader model architectures. Furthermore, scaling complex conversion and packing strategies to support larger Transformer variants and non-NLP domains is a promising avenue.
Conclusion
EncFormer provides a comprehensive, technically sophisticated hybrid FHE--MPC Transformer inference framework that delivers strong practical improvements on both communication and latency metrics, while maintaining accuracy. Its main advancement lies in the explicit, mathematically grounded co-design of packing contracts, boundary conversion, and MPC protocol structure, as visualized in its modular system architecture and supported by robust cost analysis.
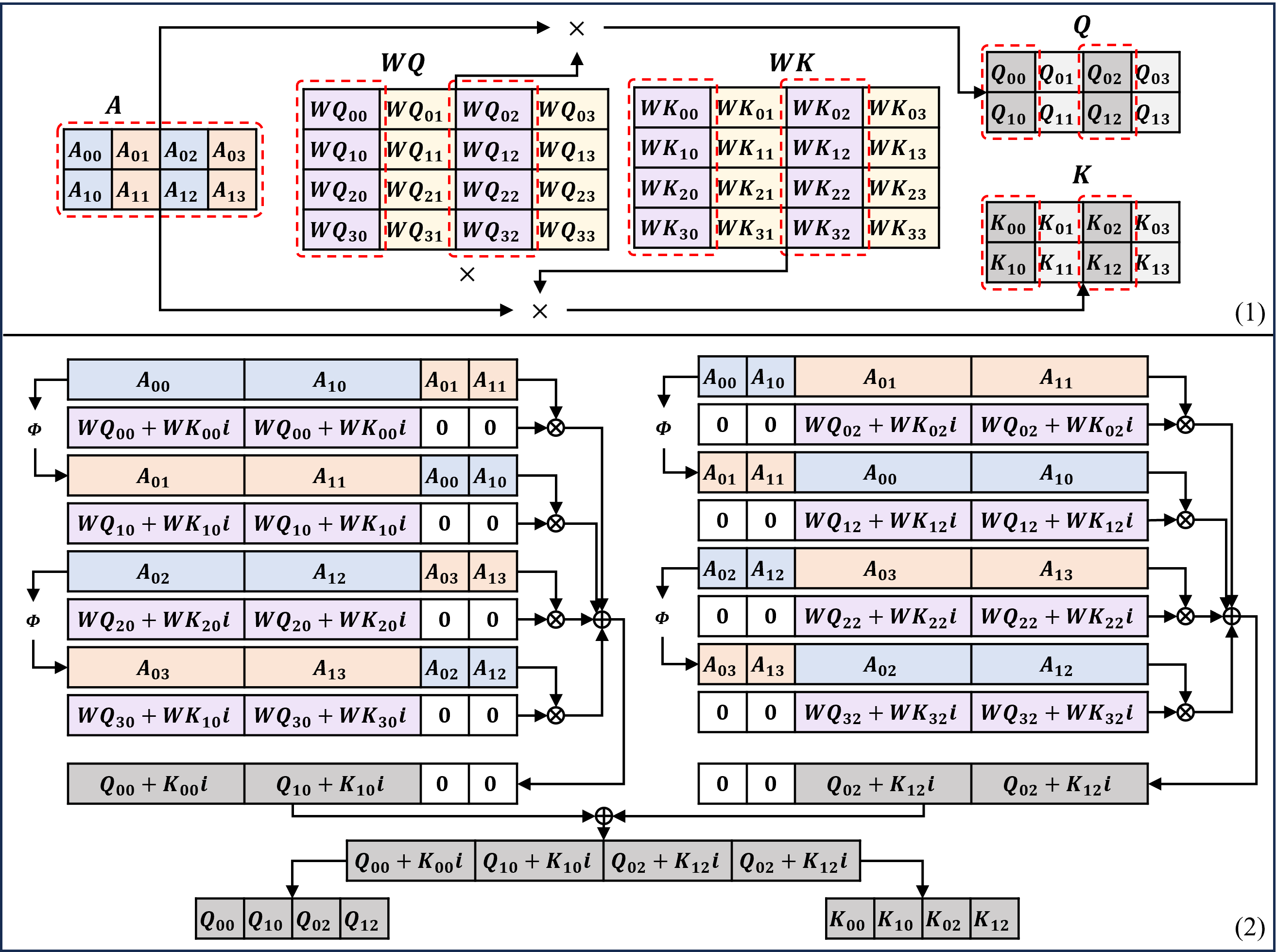
Figure 9: Plain matrix multiplication for n=46 and n=47 with n=48 and n=49.
By enforcing cross-stage layout invariants and leveraging a secure, low-payload conversion channel, EncFormer transforms the practical feasibility of privacy-preserving inference for complex deep learning models, setting a new bar for deployment-oriented cryptographic ML system design.