- The paper demonstrates that a tiny attention-only decoder achieves nearly 90% of full-data accuracy with just 30% of the training data.
- It employs rigorous methodology by training on nested, power-of-two data subsets under fixed-epoch and fixed-computation regimes.
- Empirical results reveal that in compute-limited settings, data volume, not model capacity, primarily drives performance improvements.
Dataset Scaling Laws in Tiny Attention-Only Decoders: Analysis and Implications
Introduction
The paper "Is More Data Worth the Cost? Dataset Scaling Laws in a Tiny Attention-Only Decoder" (2604.09389) presents a rigorous investigation into the persistence and manifestation of scaling laws for LLM pretraining in the low-capacity, data- and compute-constrained regime. The study deviates from the dominant trend of jointly scaling LLM parameter count and dataset size at industrial scale, instead focusing on an attention-only decoder architecture derived from GPT-2 with significant reductions: frozen embeddings/output projections and removal of all MLP sublayers, yielding approximately 2.4M trainable parameters. The primary aims are to isolate self-attention-driven learning, examine representative and distributional properties of training subsets, quantify cost-performance tradeoffs, and evaluate the practical limits of dataset scaling in compute-limited environments.
Minimal Attention-Only Decoder Architecture
The architectural reductions are central to the experimental design. The model retains the GPT-2 attention-only decoder backbone but excises the MLP components and freezes both token and positional embeddings, as well as the output projection, restricting all learning to the parameters of the (single-layer) self-attention module. The resulting model enables controlled analysis of scaling phenomena, absent the confounding effects of representation learning and deep nonlinear transformations across layers.
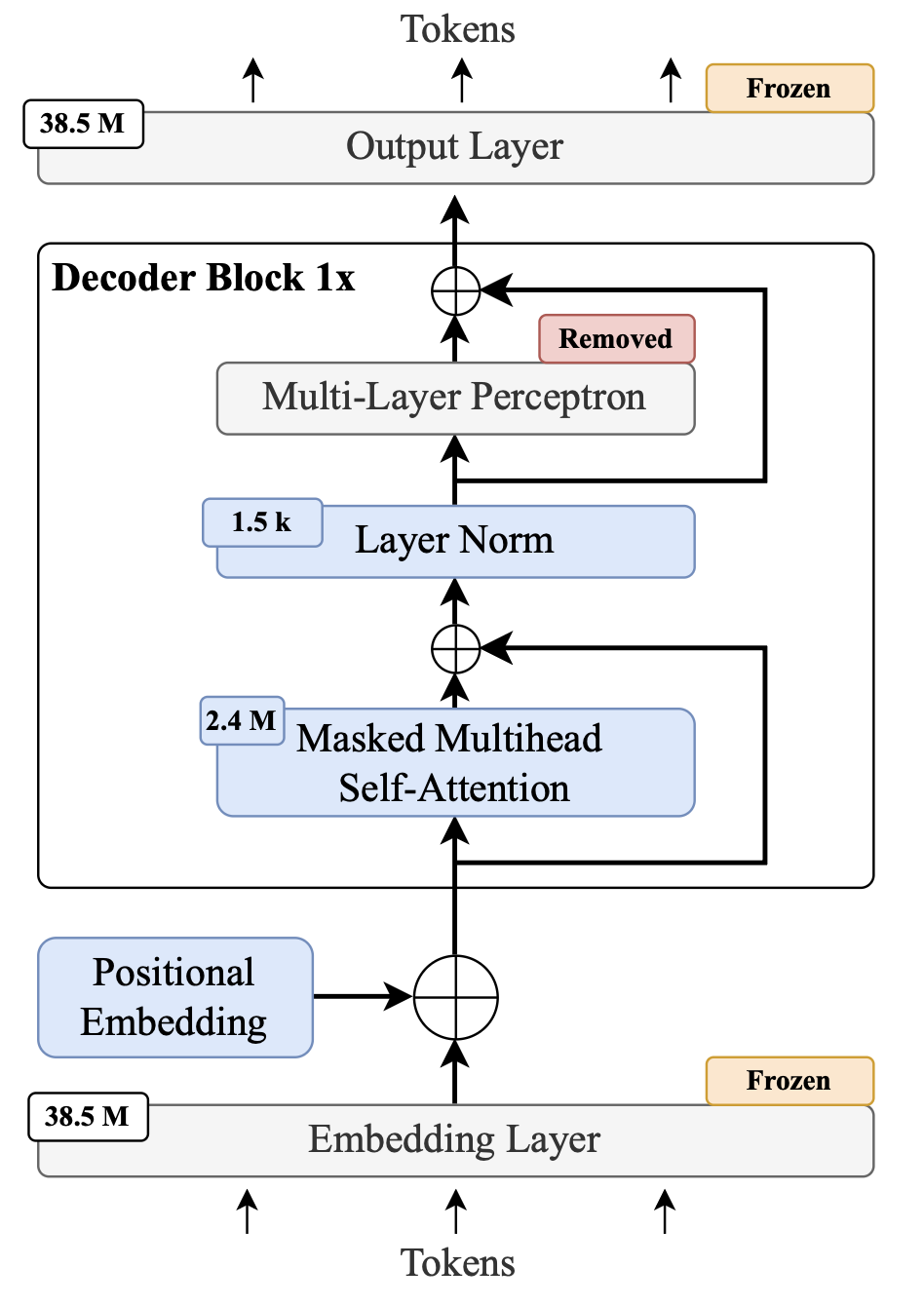
Figure 1: Architecture graph of the attention-only architecture with individual layers.
This reduction is motivated both by prior work demonstrating robust language modeling capacity in attention-only transformers [bermeitingerReducingTransformerArchitecture2024] and by the propensity of token embeddings to dominate the trainable parameter budget in minimal models, resulting in undesirable instability and overfitting when not frozen. The architectural choice precludes model capacity scaling within these experiments, focusing the analysis solely on dataset size and its interaction with limited attention model capacity.
Scaling Laws, Data Subset Construction, and Distributional Analysis
The empirical backbone of the paper is a detailed scaling sweep: models are trained on power-of-two-sized, nested random subsets of the AllTheNews2.0 corpus, ranging from 27 (128) to 217 (131,072) sequences, with a uniform minimum article length and the standard GPT-2 tokenization. Padding is fixed to minimize confounding, and all evaluation is performed on a held-out validation partition.
To ensure observed learning behaviors are attributable to dataset size rather than random selection bias, the subset sampling process and resulting statistical properties of each subset are rigorously characterized. Crucially, the convergence of subset token frequency distributions to that of the full corpus is quantified via Jensen–Shannon (JS) divergence, showing that even moderate subset sizes (212 and up) are statistically indistinguishable from the full dataset in unigram distribution, and that inter-seed variance vanishes as subset size increases.
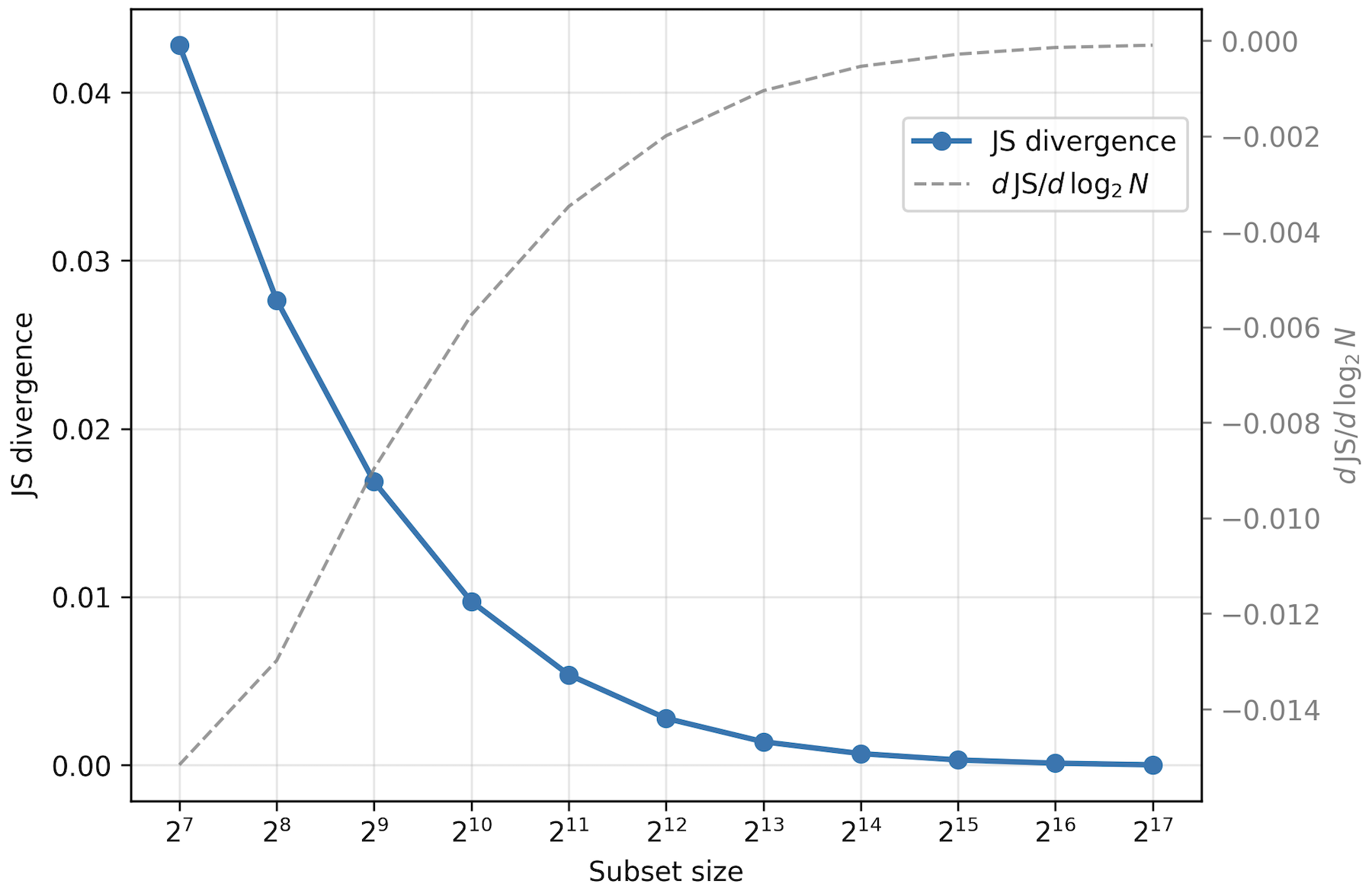
Figure 2: Jensen--Shannon divergence between token distributions of training subsets and the full dataset. The dashed curve shows the first derivative.
This exhaustive distributional convergence analysis validates the use of random subsets for data-scaling experiments in this regime and confirms that performance trends can be attributed to the effects of data volume rather than distributional artifacts or sampling variance.
The paper centers its results on accuracy, cross-entropy loss, and computational cost under two regimes: (1) fixed epoch training (in which larger subsets mean more optimization steps), and (2) fixed computation regime (equal steps for all). Across both regimes, model performance increases monotonically—but with clear diminishing returns—as subset size grows. Notably, attaining 90% of the full-data validation accuracy requires only ≈30% of the training data and 26% of the training time; even smaller subsets recover 80% of maximal accuracy for 7% of total computational cost.
This pronounced effect demonstrates that, in the tiny-model regime, most of the useful learning signal is saturated in the first fraction of the dataset, and beyond-moderate subset sizes, additional data and compute yield sublinear gains.
Theoretical Context: Scaling Law Comparisons
To position empirical outcomes within the larger scaling-laws literature, the study overlays its loss curves with predictions from the canonical scaling-law equations [kaplanScalingLawsNeural2020a], using the relevant parameter and data budgets. The results reveal two key findings:
- In this minimal-parameter regime, loss is much closer to the infinite-model-capacity asymptote (for fixed available data) than to the infinite-data asymptote (for fixed model capacity), demonstrating that performance is fundamentally data-limited.
- Empirical loss saturates before the theoretical scaling prediction, primarily because fixed-epoch schedules entail undertraining for larger subsets, while the scaling laws presume full convergence at every scale.
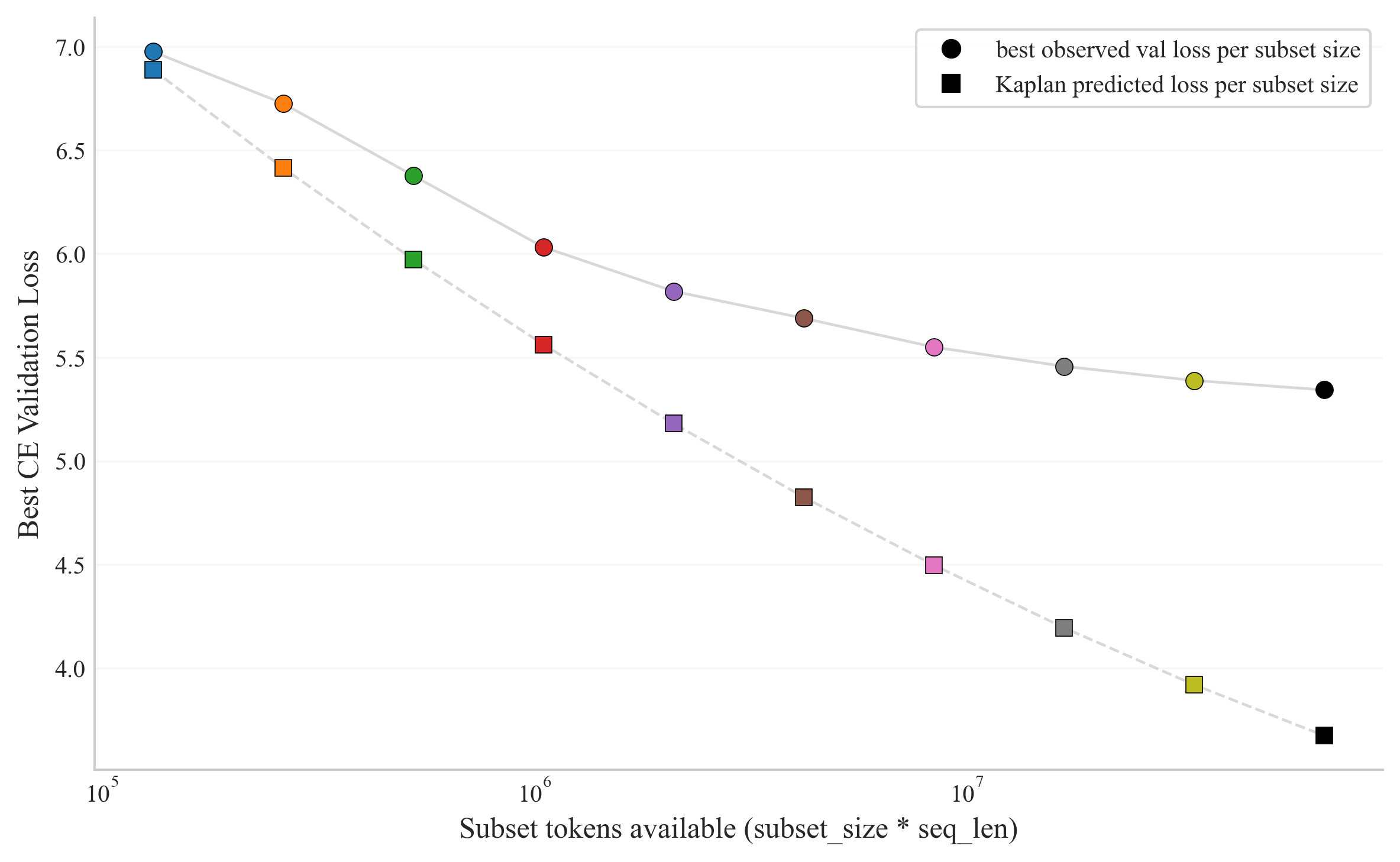
Figure 3: Empirical best validation CE loss per subset size compared to the Kaplan scaling-law prediction on AllTheNews2.0.
This comparative analysis underscores that further increases in trainable parameter count (within this setup) would yield only negligible improvements unless additional data is also available, directly aligning with compute-optimal pretraining prescriptions [hoffmannTrainingComputeOptimalLarge2022a].
Implications and Future Directions
The findings have strong implications for the design and resource allocation of pretraining pipelines, especially in small-lab or rapid-experiment contexts:
- Subset-based pretraining and early stopping are validated as effective strategies for achieving near-saturated performance with radically reduced cost.
- Architectural simplification (removal of MLPs and freezing of embeddings) does not preclude the manifestation of scaling-law behavior; self-attention alone suffices to drive scaling curves similar to those documented in full models.
- Data selection matters: random subsets of moderate size are reliably representative, but further work (e.g., on non-random, influential subset selection or curriculum learning) is motivated by the rapid early saturation.
- Data-limited regimes dominate in these small models; parameter-scaling is unproductive without simultaneous data scaling.
These results reinforce recent analyses emphasizing data efficiency [muennighoffScalingDataConstrainedLanguage2025, sporerEfficientNeuralNetwork2024] and point to principled lower bounds for training cost in practice, with theoretical insights about phase changes in scaling curves. They highlight promising paths for structure-based pretraining, including alternative scheduling, adaptive optimization targeting small models, and data-centric training set design.
Conclusion
The study conclusively demonstrates that established scaling-law dynamics and diminishing returns curves persist in tiny, attention-only, decoder-only architectures. Statistical representativeness of random subsets is rapidly achieved, and performance is overwhelmingly data-limited. The results are directly actionable for researchers and practitioners aiming to optimize for data and compute efficiency: moderate subset sizes suffice for robust language modeling performance, and aggressive further scaling is cost-ineffective in this regime.
Future research can extend these analyses to richer data selection strategies, alternative sequence modeling domains (e.g., code, low-resource languages), and further architectural simplification, all within the framework provided by principled scaling-law predictions.

