- The paper introduces a generative framework that treats multi-stem music source separation as a conditional sequence generation problem using discrete tokens.
- It combines a Conformer-based encoder, dual-path neural audio codec with RVQ, and a LLaMA-style decoder to autoregressively generate tokens for reconstructing vocals, drums, bass, and other stems.
- Experimental results demonstrate competitive perceptual scores with robust vocal separation, though transient percussive elements pose challenges.
Discrete Token Generative Modeling for Multi-Stem Music Source Separation
This paper introduces a discrete token-based generative framework for multi-stem music source separation (MSS), fundamentally reimagining MSS as a conditional sequence generation problem. Traditional discriminative architectures, whether operating directly in the frequency or time-frequency domains, regress spectral masks or waveforms directly. In contrast, this work leverages recent advances in neural audio codecs and language modeling to map the complex separation problem onto a discrete, autoregressive language modeling paradigm.
The model structure comprises three core components: a Conformer-based conditional encoder for extracting continuous mixture features, a dual-path neural audio codec (HCodec) employing residual vector quantization (RVQ) for discrete tokenization, and a decoder-only LLM (LLaMA architecture) to autoregressively synthesize discrete token streams for each source. The conditional encoder captures mixture-level cues, while the LLM conditions on these features to generate token sequences for four stems—vocals, drums, bass, and other. Generated tokens are ultimately mapped to waveforms using the neural codec decoder.
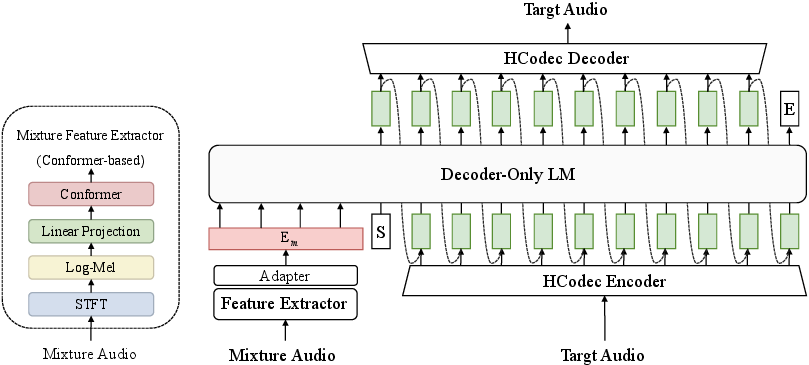
Figure 1: Architecture of the proposed token-based generative source separation model. The Mixture Embedding Em is conditioned by the Decoder-Only LM, which autoregressively generates discrete audio tokens.
Discrete Tokenization and Autoregressive Language Modeling
The dual-path HCodec encodes each track into intertwined acoustic and semantic streams via acoustic (ConvNeXt-Transformer) and semantic (HuBERT-based) branches, each quantized with a 16-layer RVQ (codebook size 1024, frame rate 12.5 Hz). Interleaving these token streams allows the LLM to capture both content and texture at each timestep, essential for high-fidelity music reconstruction.
The LLM input sequence consists of a projected mixture embedding, followed by shared start symbols and tokenized sequences for each stem. The model is trained to minimize the negative log-likelihood of each token, using a causally masked teacher-forcing setup, with increased loss weighting on the most significant RVQ layer. At inference, cross-track dependencies are exploited by generating the four stems sequentially, sharing the internal cache across tracks.
Training Regime and Data Augmentation
Training is performed on a large-scale composite dataset (~23,000 hours) synthesized using BS-RoFormer pseudo-labels, since isolated ground-truth stems are absent. Leverages comprehensive data augmentation: per-track loudness scaling, polarity inversion, and parametric equalization. Rigorous training and high-resolution (48 kHz) audio facilitate realistic evaluation of the generative pipeline's performance boundaries.
Evaluation and Experimental Results
Evaluation employs perceptual metrics robust to small sample misalignments inherent in autoregressive generation: ViSQOL for holistic perceptual audio quality across all stems, DNSMOS, and NISQA for vocals. The model attains a mean ViSQOL of 3.55, showing competitive separation quality against strong discriminative systems (e.g., BS-RoFormer, HTDemucs) across vocals, bass, and other. Human-salient stem—vocals—achieves the highest NISQA score (2.50), outperforming all discriminative baselines. The approach demonstrates comparable bass separation to top discriminative methods and is on par for "other" instruments. Notably, a marked performance drop on drums (ViSQOL: 3.44 vs. 3.77–3.88) reveals limitations of token-based autoregressive decoders for transient-laden percussive content.
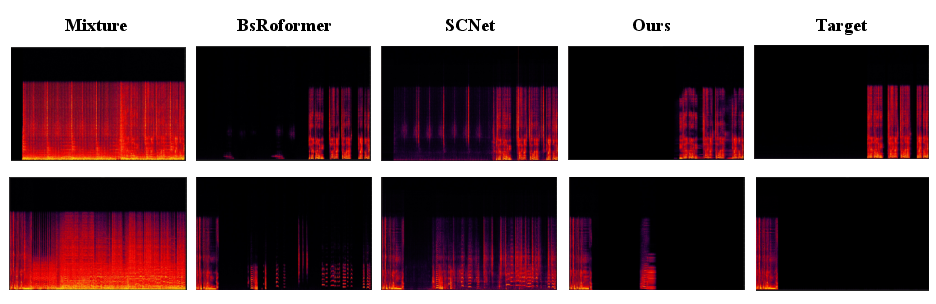
Figure 2: Qualitative spectrogram visualization of source separation results for the vocals track.
Qualitative spectrograms further evidence improved source selectivity for vocals—less accompaniment leakage and artifacting compared to spectrogram-masking baselines.
Ablation and Design Analysis
Three ablations probe the importance of architectural and procedural choices:
- Conditional Encoder: Replacing the learnable Conformer with a frozen HuBERT, a speech representation model, results in a notable ViSQOL decrease (3.55→3.37 avg), particularly for drums, indicating the need for learnable mixture-aware encoders.
- RVQ Loss Weighting: Alternative loss weighting across RVQ layers marginally impacts performance, suggesting robustness to this hyperparameter.
- Parallel vs Sequential Generation: Forcing parallel (track-independent) decoding degrades vocals and "other" scores, validating the importance of cross-stem dependencies captured by sequential decoding.
Limitations and Theoretical Implications
Several practical limitations are discussed:
- Transient Modeling: Token-based autoregressive generation underperforms for percussive sources, presumably due to the granularity and causal context limitations within sequence generation frameworks.
- Quality Ceiling: Supervision via pseudo-labels constrains potential upper-bound separation quality. Further, cumulative quantization and generation errors across layered RVQ stacks hinder reconstruction fidelity.
- Inference Efficiency: Sequential stem generation, though beneficial to quality, incurs latency.
From a theoretical perspective, this work bridges advances in neural audio coding and sequence modeling, and demonstrates that generative modeling on discrete audio representations can rival, and in some aspects surpass, regression-based discriminative methods for complex structured audio generation tasks. The explicit treatment of the MSS as a sequence generation problem admits new hybrid training objectives, joint conditional tasks, and potentially extends to multimodal grounding.
Conclusion
This paper formalizes multi-track music source separation as conditional autoregressive discrete token generation, leveraging a hybrid architecture of conditional encoding, neural audio tokenization, and LLM-based decoding. Results on MUSDB18-HQ validate the generative paradigm, with segmentation fidelity and perceptual quality approaching or exceeding that of state-of-the-art discriminative models, especially for vocals. The analysis suggests that further performance gains on transient-rich content require advances in codec design, tokenization schemes, or non-autoregressive generative paradigms. The framework provides a robust platform for extensions incorporating symbolic, textual, or multimodal conditioning, and for future research on generative modeling of structured acoustic scenes.

