- The paper introduces MADRI, a reconstruction-based framework that integrates vision and sensor data for detecting anomalies in human-robot interaction.
- It uses high-level feature extraction with a fine-tuned Swin3D model, sensor fusion, and autoencoder reconstruction to identify deviations in real time.
- Empirical results show improved detection accuracy through sensor integration, while challenges with scene graph augmentation highlight areas for future refinement.
Multimodal Anomaly Detection for Human-Robot Interaction: An Authoritative Synthesis
Introduction
Safe and reliable operation in Human-Robot Interaction (HRI) requires robust mechanisms to detect and respond to anomalous events spanning both environmental and robot-internal domains. While classical safety methods center around predetermined rules and protocols, these typically offer minimal protection against complex, unmodeled failures. The paper "Multimodal Anomaly Detection for Human-Robot Interaction" (2604.09326) introduces MADRI, a multimodal reconstruction-based anomaly detection framework operating on high-level feature representations, integrating vision, robot sensor data, and scene semantics for a more comprehensive approach to anomaly identification in HRI settings.
Problem Framing and Motivation
The limitations of pixel-level anomaly detection—chiefly poor generalization to unseen environments and high computational demands—are well-documented in robotics and computer vision. Additionally, relying solely on visual information can miss critical sensor-level failures or relational anomalies between scene entities. The MADRI framework posits that anomaly detection within a fused, semantically meaningful feature space allows for more robust identification of deviations from nominal behavior. The paper targets not only visually perceptible anomalies but also internal malfunctions (e.g., joint overloads) and incorrect relational configurations, which can be imperceptible in video streams alone.
An illustrative example of critical failure in HRI tasks is shown in the following:


Figure 1: A cup handover failure arising from unexpected human placement, resulting in an unsuccessful robot grasp and subsequent drop.
Framework Architecture and Methodology
At the core of MADRI is a staged architecture comprising:
- High-level Visual Feature Extraction: RGB video streams are processed by a fine-tuned Swin3D backbone, originally trained on the Kinetics dataset. The classification head is removed post-training, and the network outputs a 768-dimensional embedding vector representing each 32-frame action clip. This embedding prioritizes relevant task semantics and suppresses extraneous visual details.
- Sensor Fusion and Scene Graph Integration: Robot joint torques and gripper positions are preprocessed using temporal Max Pooling and concatenated with the vision-derived features. Additionally, object and agent relations extracted via a Scene Graph generator further enrich the feature representation, allowing detection of object/person relation failures.
- Feature-space Autoencoder Reconstruction: The unified multimodal vector is fed into an autoencoder. Anomalies are flagged by comparing input-output reconstruction errors against a task-specific learned threshold. During inference, the system operates on a per-clip basis, offering fine-grained temporal localization of anomalies.
This architecture is visually summarized as follows:
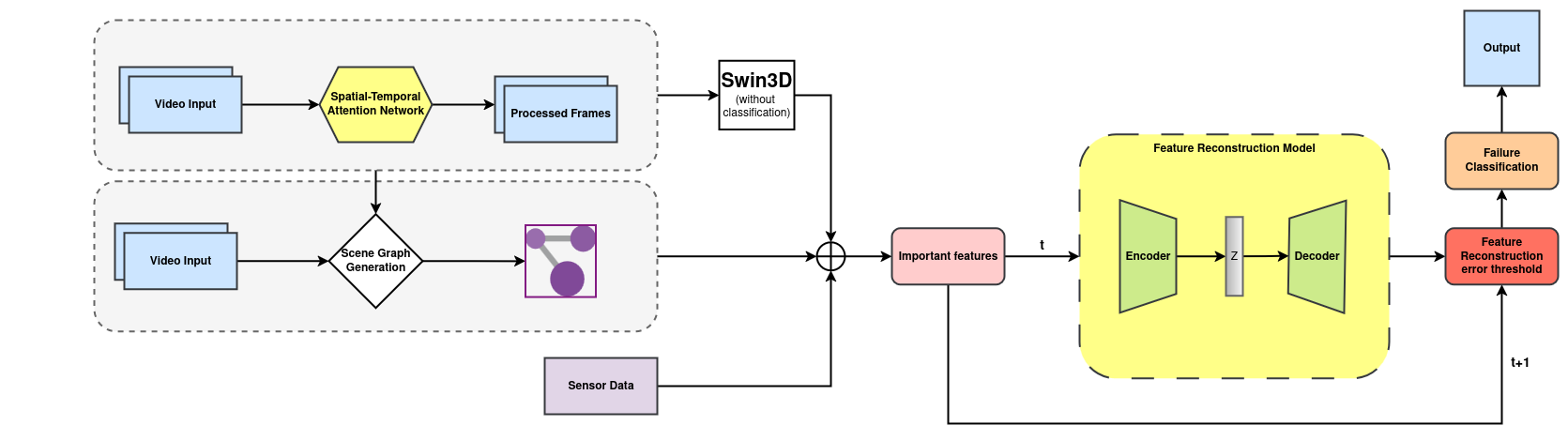
Figure 2: Overview of the MADRI framework highlighting the Swin3D backbone for visual encoding, multimodal feature concatenation, and anomaly score generation via reconstruction error.
Dataset, Experimental Protocol, and Action Recognition
Due to the scarcity of HRI anomaly datasets with diverse modalities, the authors curate a custom dataset featuring a challenging pick-and-place scenario, including both regular operation and organically occurring failure modes (e.g., dropped objects, collisions, and unexpected human interventions). Action classes are meticulously defined, and the Swin3D model is fine-tuned for discriminative feature extraction.
Action recognition performance is quantified, showing high intra-class accuracy, with some confusion observed between visually and kinematically similar classes, as visualized below:
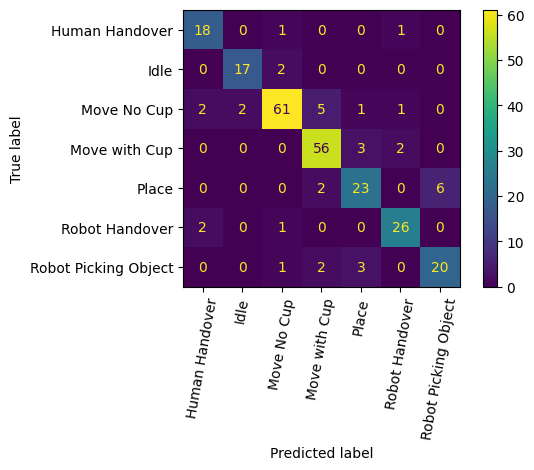
Figure 3: Confusion matrix demonstrating action recognition accuracy and class ambiguities, highlighting strong discrimination for motion-centric actions.
Accompanying qualitative samples showcase both nominal and anomalous behaviors:




Figure 4: Representative actions spanning robot object pickup, handover, and movement sequences with/without the object.
Empirical Evaluation and Ablation
MADRI is systematically evaluated on the collected dataset to assess: (a) the benefits of semantic feature-space reconstruction over traditional pixel-based approaches, and (b) the incremental contributions of sensor and relational modalities. Reconstruction errors during representative anomalies, such as joint torque exceedances or dropped objects, are analyzed:
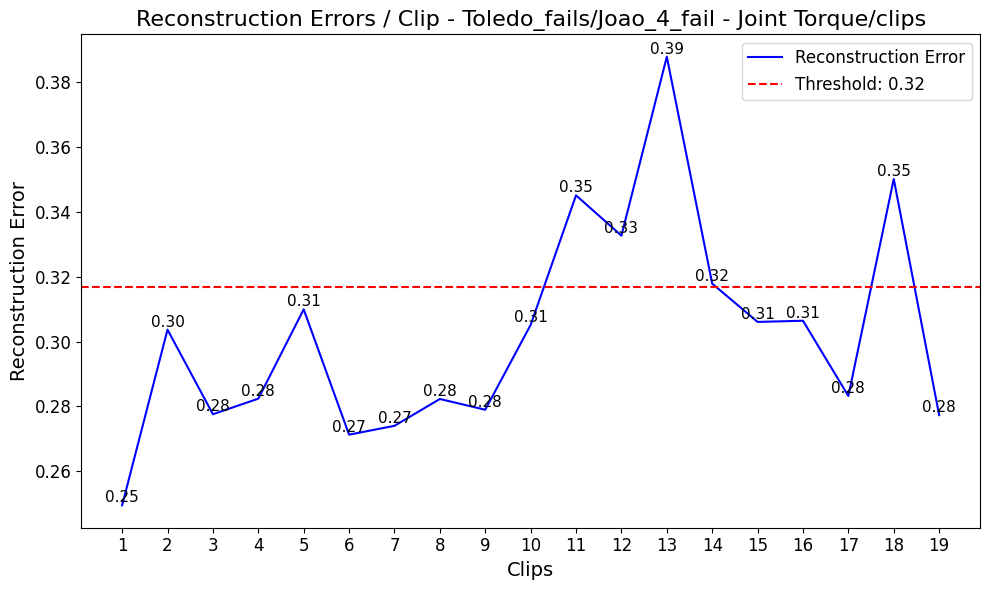
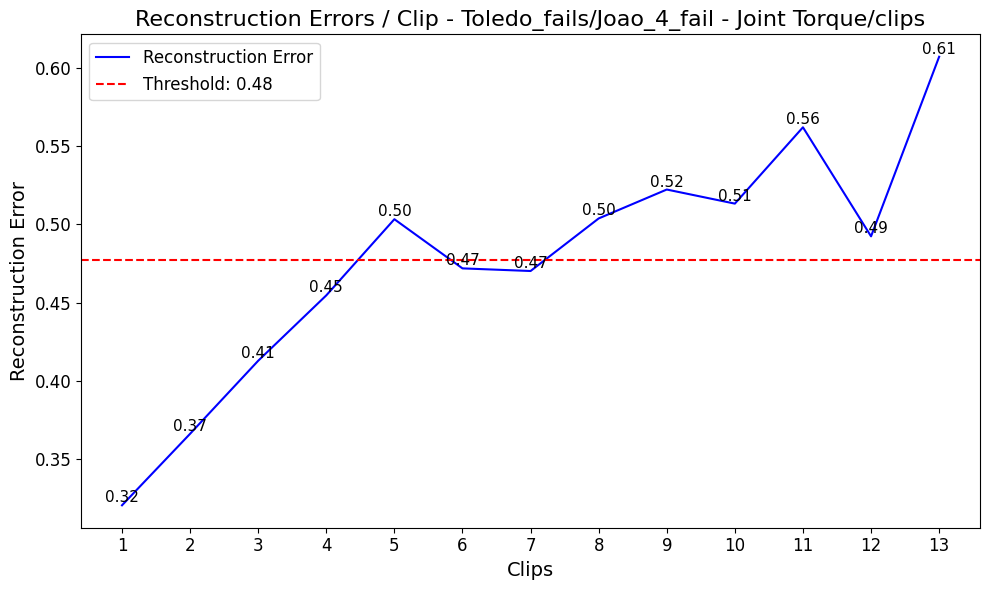
Figure 5: Comparison of clip-wise reconstruction errors in joint torque failure scenarios. The multimodal model demonstrates higher anomaly sensitivity and specificity.
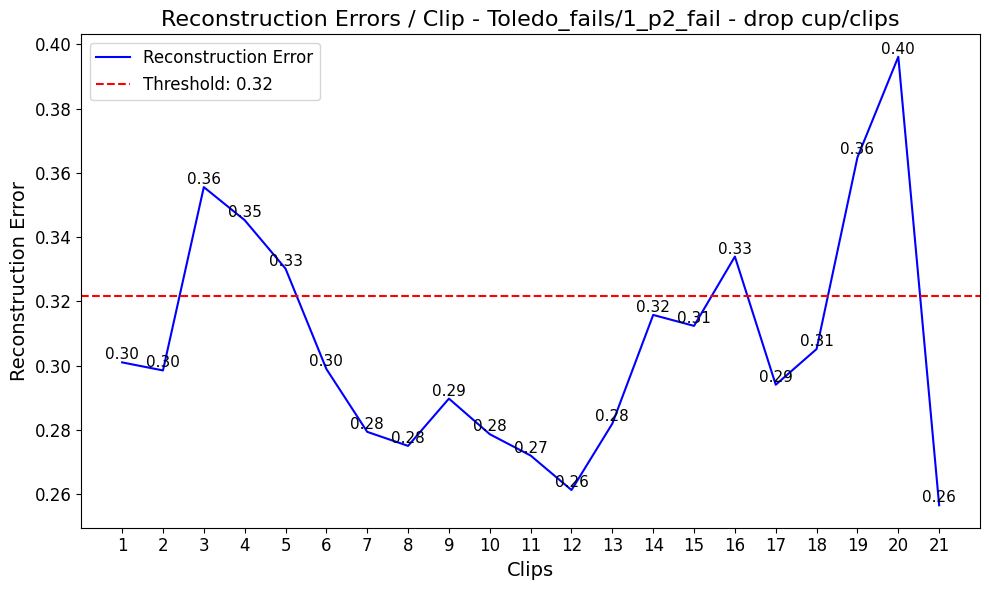
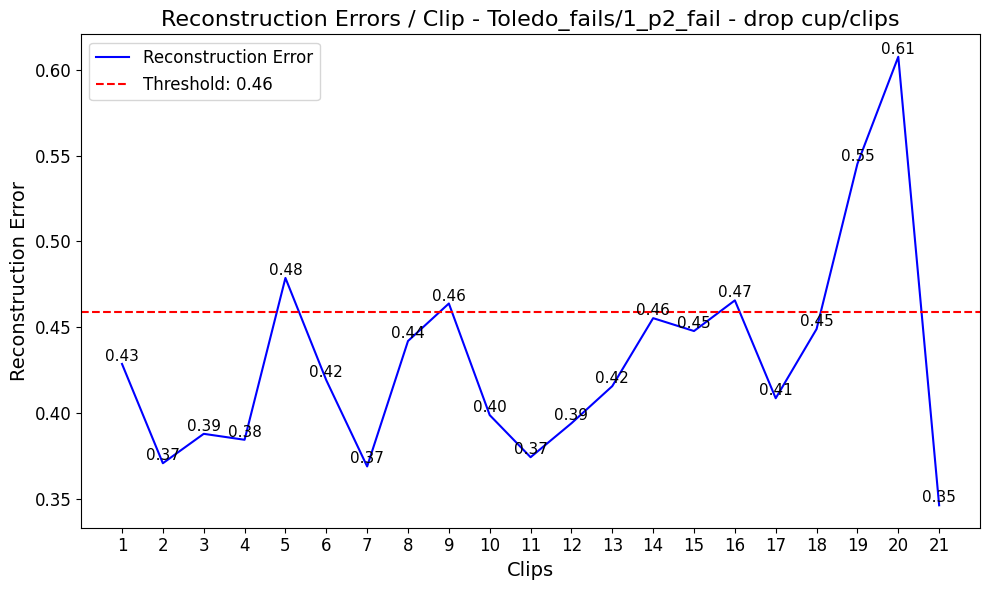
Figure 6: Reconstruction error trajectories for a robot drop event, showing sharper anomaly onset detection in the multimodal fusion model.
Ablation experiments, visualized via ROC curves, provide empirical evidence that the inclusion of joint torque sensor data yields substantial improvements in both true positive detection rates and false positive suppression. Notably, the addition of a Scene Graph—while conceptually beneficial—degrades performance given suboptimal scene graph generator reliability and the non-relational nature of the anomalies present in this dataset.
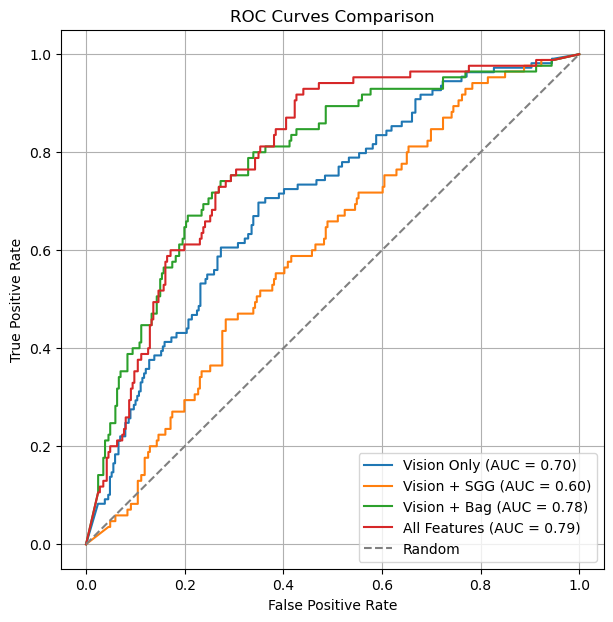
Figure 7: ROC Curves from ablation studies, demonstrating superior AUC for models incorporating sensor data, with Scene Graph integration providing minimal or negative effect in the current task context.
Strong Results and Bold Claims
- The authors claim and demonstrate that feature-space reconstruction (versus per-pixel) is both computationally efficient and more robust to irrelevancies in the environment, outperforming visual-only anomaly detection approaches in both accuracy and computational cost.
- The integration of proprioceptive (sensor) modalities significantly boosts anomaly identification in cases where visual evidence is ambiguous or altogether absent.
- Scene Graph augmentation does not always confer benefits, underscoring the importance of the upstream relational model and dataset characteristics. The paper candidly reports negative results in this dimension.
Implications and Future Directions
The proposed multimodal approach provides a plausible path toward real-world deployment of anomaly detectors in collaborative, partially unpredictable environments, such as automated factories, healthcare, and logistics systems. By demonstrating that high-level, fused semantic features improve robustness to environmental variation and task complexity, the work suggests a broader trend in robotics toward architectural designs that blend vision, proprioception, and scene understanding at the representation level.
Practically, the ability to detect subtle mechanical or relational anomalies in real time can materially decrease the incidence of unnoticed damages, mishandled objects, or unsafe states, supporting both autonomy and human safety. Theoretically, these results call for additional research into principled multi-view feature fusion, automated threshold selection, and trust calibration in HRI systems.
Expansion to larger, more varied datasets and the inclusion of richer relational causality are highlighted as future priorities. Model improvements could include the use of attention-based fusion mechanisms, robust relational learning, and finer anomaly taxonomies for not just detection, but categorization and explanation of failures.
Conclusion
MADRI, as presented in "Multimodal Anomaly Detection for Human-Robot Interaction" (2604.09326), provides compelling evidence that semantic multimodal feature reconstruction is an effective, extensible strategy for anomaly detection in HRI. By fusing task-relevant vision, sensor, and scene relational cues, the framework achieves robust performance across a range of failure scenarios, setting a foundation for future real-world safe HRI deployments and further research into multimodal anomaly detection architectures.

