- The paper proposes a novel decoupling architecture (DecoupleVS) that separates vector data and index metadata, enabling tailored compression and storage strategies.
- It achieves up to 58.7% space reduction and 2.18× higher search throughput, significantly improving performance over conventional co-located systems.
- Batched updates and adaptive I/O handling reduce write amplification and enhance concurrent search and update performance.
Decoupled Vector Data and Index Storage: A Technical Overview of DecoupleVS
Motivation and Analysis of Existing ANNS Storage Limitations
Disk-based Approximate Nearest Neighbor Search (ANNS) systems have become central to large-scale vector retrieval tasks in AI-driven applications. Most high-performing systems (e.g., DiskANN, SPANN) simplify their implementations by co-locating vector data and auxiliary index metadata in persistent storage. However, empirical analysis demonstrates that this design introduces three primary limitations:
- High storage overhead: Auxiliary index metadata (e.g., neighbor lists in graph indices) often surpasses the vector data in storage consumption. Escalating SSD prices driven by AI workloads amplify this overhead.
- Read amplification: Similarity search queries entail large numbers of disk reads, leading to I/O queue saturation, high I/O wait times, and reduced query throughput.
- Write amplification: Updates force repeated rewriting of significant portions of the index structure, increasing disk bandwidth utilization and degrading update performance.
The core insight driving DecoupleVS is that vector data and auxiliary index metadata are semantically and operationally distinct, warranting specialized compression, layout, and access strategies. However, naive decoupling incurs new challenges, including complexity in managing variable-length compressed data, potential I/O locality loss, and consistency issues in updates.
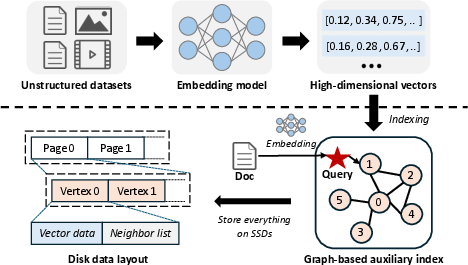
Figure 1: Basic workflow of a disk-based ANNS system, illustrating a monolithic design relying on a graph-based auxiliary index.
Architectural Design: DecoupleVS
DecoupleVS introduces architectural decoupling of vector data and auxiliary index metadata, enabling component-specific optimizations. The framework encompasses four principal technical contributions:
- Tailored Lossless Compression: Exploits the locality and entropy characteristics of vector data (XOR-based delta compression plus Huffman encoding) and auxiliary index metadata (Elias-Fano encoding after sorting of neighbor IDs) for superior space reduction.
- Hierarchical Storage Layouts: Segments and chunks subdivide vector data, maintaining efficient metadata for fast lookups and bounded decompression cost; block-based storage structures efficiently support variable-length entries.
- Latency-aware Search Mechanisms: Differentiated I/O handling for vector and index data, with priority caching and adaptive prefetching to mask the impact of decoupling on search latency.
- Batched Update Mechanisms: Separates update handling for vectors (append-only, log-structured with background garbage collection) and indices (periodic batch merges for graph integrity), addressing write amplification efficiently.
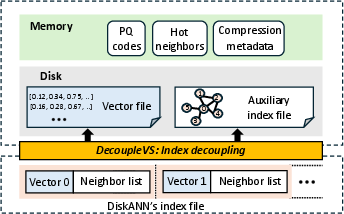
Figure 2: DecoupleVS architecture: decoupling and specialized pipelines for vector data and index metadata.
The hierarchical segmentation, combined with entropy-driven delta compression, allows the system to strike an optimal trade-off between access efficiency and space saving.
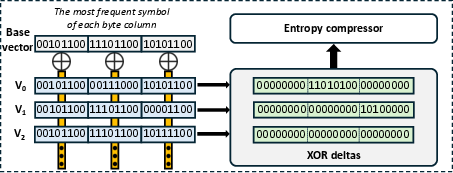
Figure 3: Delta compression for multi-dimensional vectors as realized in DecoupleVS: most frequent byte-per-position forms the base vector, with deltas XOR-compressed per vector.
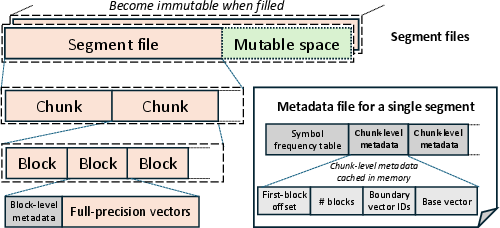
Figure 4: Hierarchical storage layout for vector data supports scalable, high-throughput search and efficient garbage collection.
Compression Analysis and Implementation
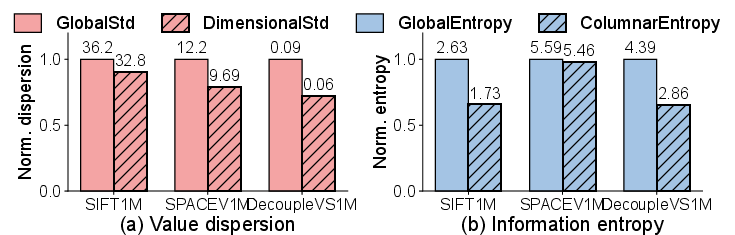
Empirical examination of real-world datasets—both public (e.g., SIFT1M) and proprietary—yields two primary observations:
Consequently, DecoupleVS generates a base vector using the most frequent byte per position and applies XOR-based delta compression with vector-wise Huffman encoding per segment. For the index, ascending-order conversion of neighbor ID lists enables high-compactness Elias-Fano encoding, benefiting further from a blockwise layout and a sparse cacheable index.
Macro- and microbenchmarking are conducted on both proprietary and public billion-scale datasets (e.g., SIFT1B, SPACEV1B). Compared to DiskANN, PipeANN, and SPANN, DecoupleVS demonstrates:
- Space efficiency: Reductions up to 58.7% (100M-scale), 42.6% (billion-scale) in overall storage size compared to DiskANN. Both the vector data and auxiliary index show substantial gains, especially on full-precision datasets.

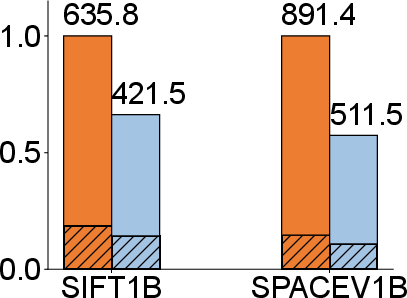
Figure 6: Space efficiency—DecoupleVS minimizes storage across both vector and auxiliary index components; normalization accentuates improvements beyond DiskANN and SPANN.
- Search throughput and latency: Up to 2.18× throughput over existing graph-based solutions; lower P99 search latencies across recall settings on 100M- and billion-scale datasets. Gains become more prominent at higher recall levels.
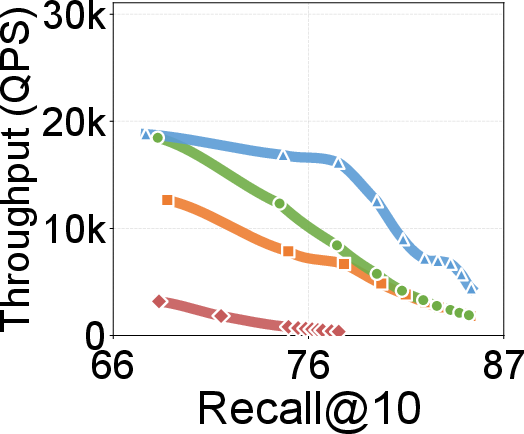
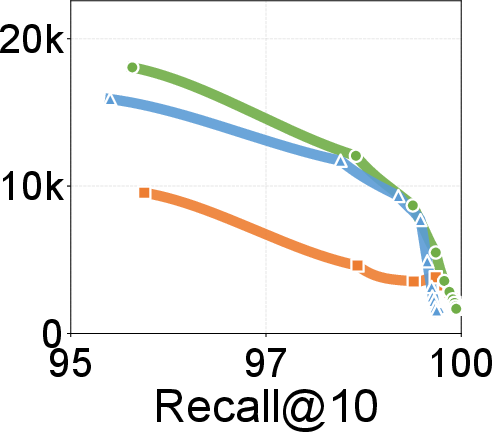
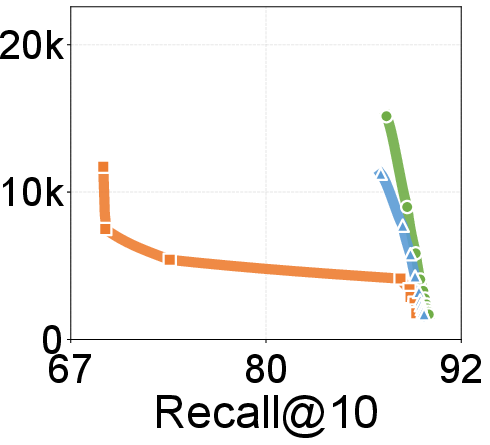
Figure 7: Search throughput vs. recall@10; DecoupleVS curve demonstrates higher QPS to high-recall regimes relative to PipeANN and DiskANN.
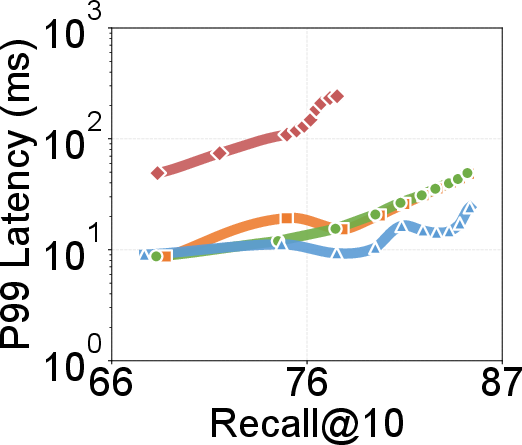
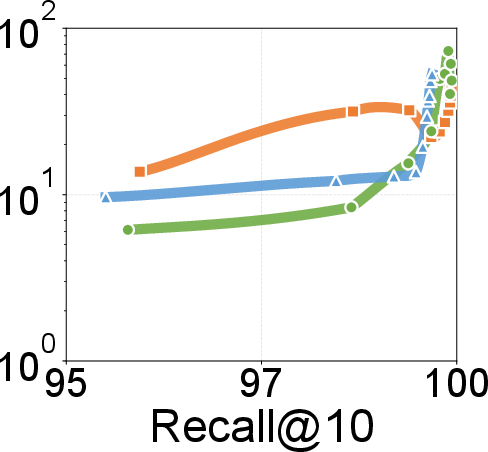
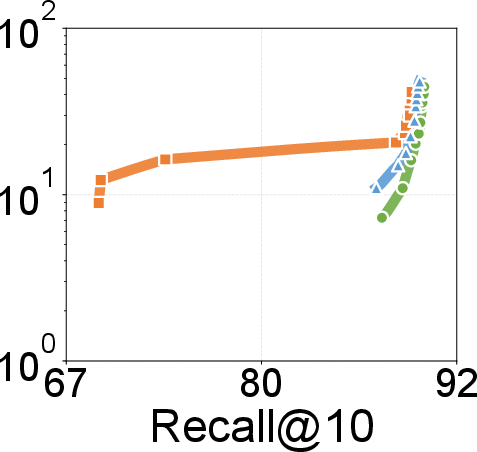
Figure 8: P99 search latency vs. recall@10; DecoupleVS achieves lower latency, particularly as recall demands approach 99%+.
- Concurrent updates: 1.88× throughput increase on concurrent search and updates, with 33.6% lower peak storage size and negligible memory overhead compared to DiskANN during merge cycles. The batched, append-only approach eliminates full rewrites and reduces write amplification.
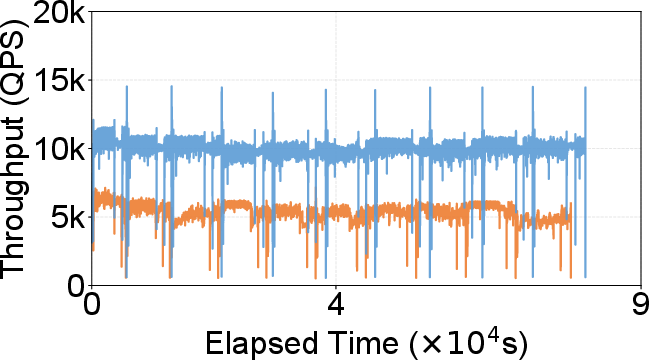
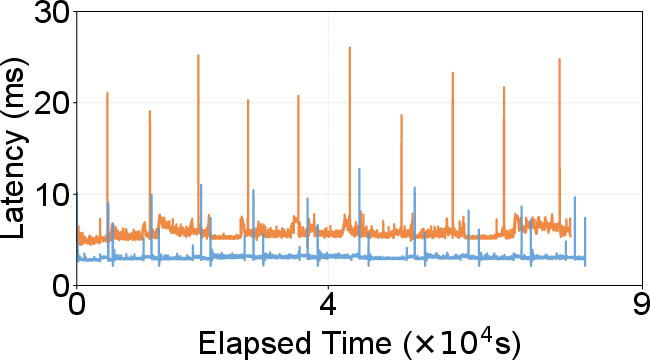
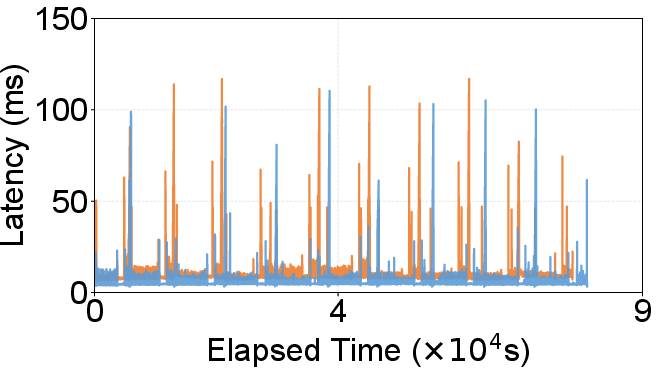
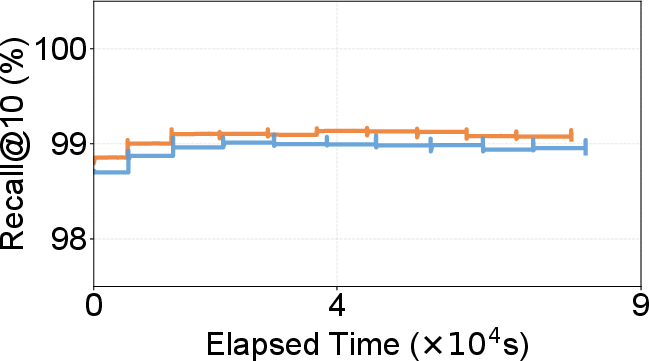
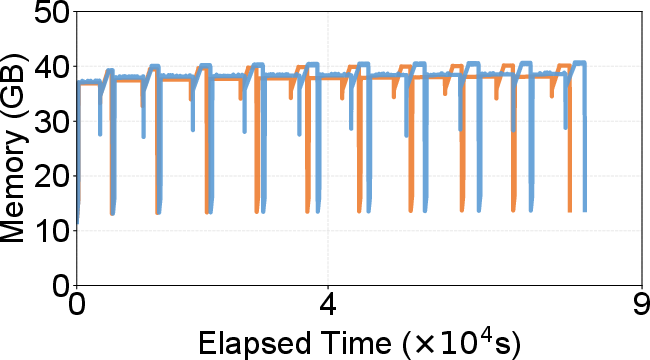
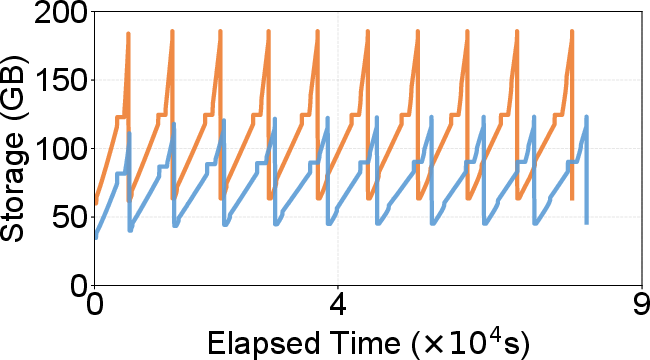
Figure 9: Concurrent search and update—DecoupleVS maintains high throughput and recall, stable and lower storage size despite a dynamic update workload.
- Update breakdown: While DecoupleVS introduces minor additional CPU utilization for compression/decompression, it achieves up to 13% reduction in disk I/O time per merge operation.
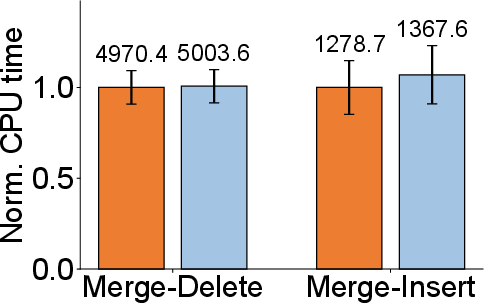
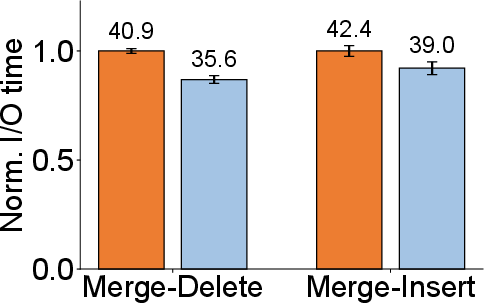
Figure 10: Update performance breakdown—reduction in disk I/O time per update compared to DiskANN, with moderate overhead in computation.
Implications, Limitations, and Directions for Future Work
DecoupleVS demonstrates that semantics- and pattern-aware decoupling of vector and index data is critical for addressing the growing cost and performance constraints in billion-scale ANNS deployments. The technical methodology is orthogonal to in-place update and lossy memory quantization techniques, suggesting that DecoupleVS can serve as a foundational layer in future vector search systems. Notably, dataset properties (e.g., bit-depth, pre-applied quantization) can modulate compression effectiveness; adaptive techniques may be further explored.
Potential advancements include deeper integration of device-side accelerators for decompression, co-designing layout strategies for emerging persistent memory, and more sophisticated cache allocation policies leveraging hardware heterogeneity.
Conclusion
DecoupleVS establishes the technical and practical merit of decoupling vector data and index storage in disk-based ANNS systems, combining advanced, component-specific storage compression, layout, and access mechanisms. The result is a highly space-efficient, performant, and update-capable system, empirically validated across public and commercial-scale datasets. As vector data continues to scale in AI infrastructure, such architectural separation and tailored engineering will be essential for the next generation of search platforms (2604.09173).